Downloaded 21 times







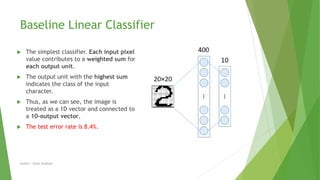
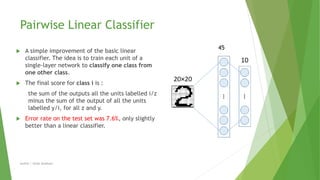

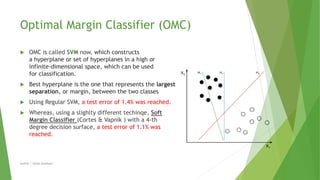





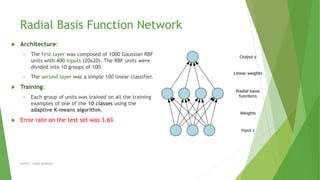
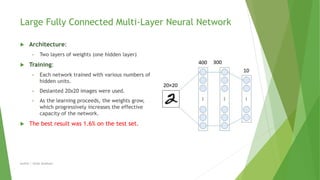


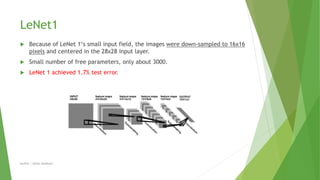











This document compares different machine learning algorithms for handwritten digit recognition on the MNIST dataset. Convolutional neural networks achieved the best results, with LeNet5 achieving 0.9% error and boosted LeNet4 achieving the lowest error rate of 0.7%. Neural networks required more training time but had faster recognition times and lower memory requirements compared to nearest neighbor classifiers. Overall, convolutional neural networks were best suited for handwritten digit recognition due to their ability to handle variations in size, position and orientation of digits.



































































