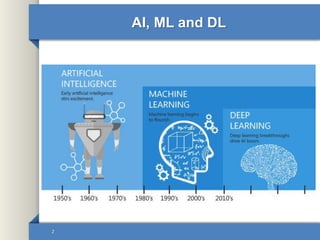
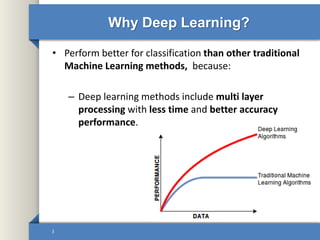
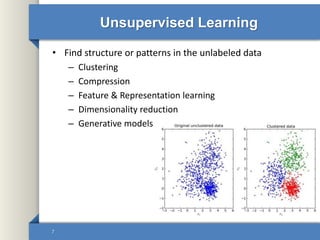
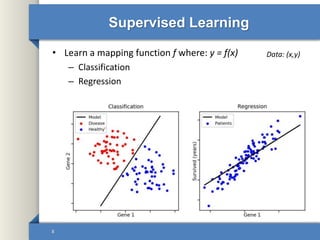
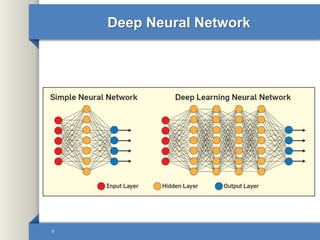
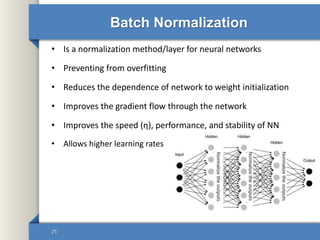
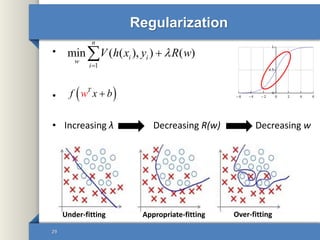
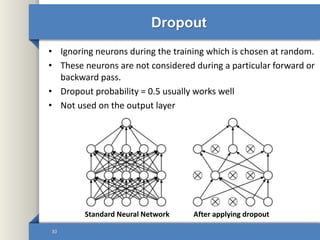
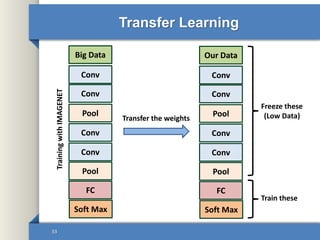
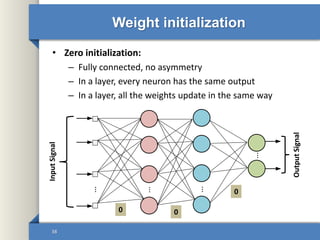
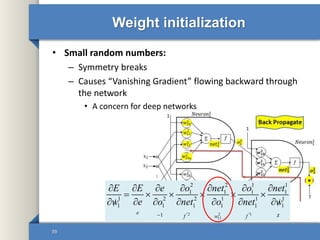
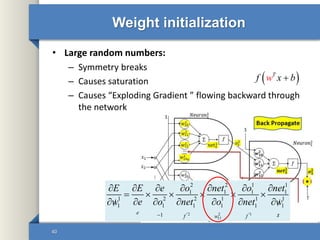
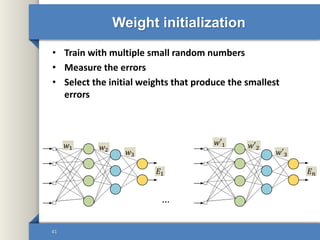
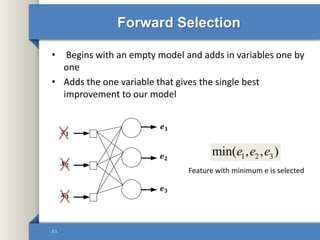
This document provides an overview of deep learning including why it is used, common applications, strengths and challenges, common algorithms, and techniques for developing deep learning models. In 3 sentences: Deep learning methods like neural networks can learn complex patterns in large, unlabeled datasets and are better than traditional machine learning for tasks like image recognition. Popular deep learning algorithms include convolutional neural networks for image data and recurrent neural networks for sequential data. Effective deep learning requires techniques like regularization, dropout, data augmentation, and hyperparameter optimization to prevent overfitting on training data.