Download to read offline







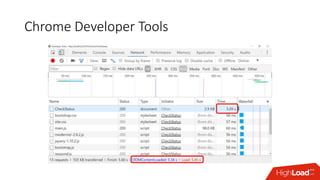










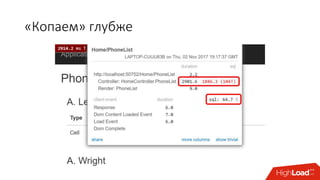
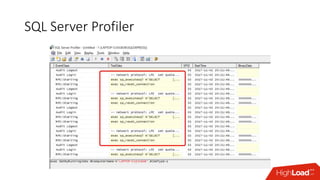






![[AppName].runtimeconfig.json
{
"runtimeOptions": {
"configProperties": {
"System.GC.Server": true|false,
"System.GC.Concurrent": true|false,
...
},
...
}](https://image.slidesharecdn.com/9-171116105737/85/ASP-NET-Core-WebStoating-s-r-o-27-320.jpg)

















Документ представляет собой экспертное руководство по оптимизации приложений на ASP.NET Core, охватывающее различные аспекты от управления памятью до кэширования и профилирования производительности. Автор делится своим опытом и предлагает инструменты для улучшения работы веб-приложений, такие как MiniProfiler и различные методы кэширования. Основное внимание уделяется важности применения рекомендаций по улучшению производительности, профилированию и использованию облачных технологий.













































































