Download as PDF, PPTX







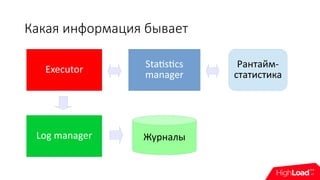























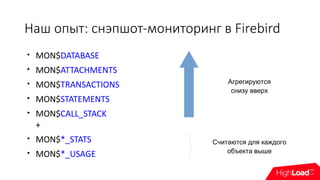









Доклад посвящен механизмам мониторинга баз данных с акцентом на необходимость понимания информации, необходимой для администраторов и DevOps. Обсуждаются методы сбора и анализа метрик, включая снэпшоты и логирование в разных системах управления базами данных, таких как MySQL, PostgreSQL и Firebird. Особое внимание уделяется детализации метрик, доступности и целостности данных, а также рекомендациям по оптимизации мониторинга.



































































