





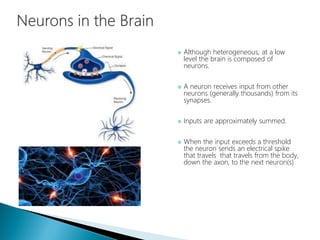
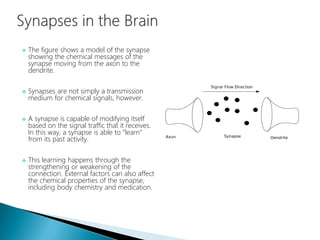


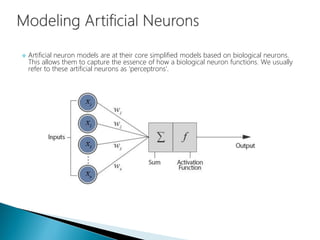
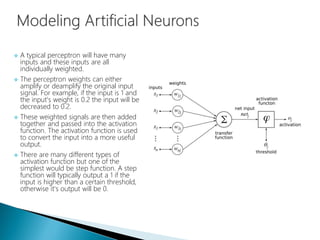

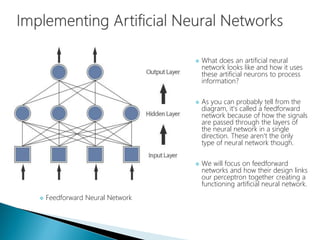
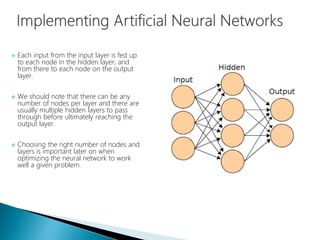
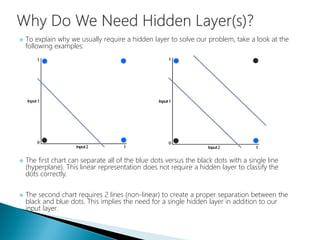
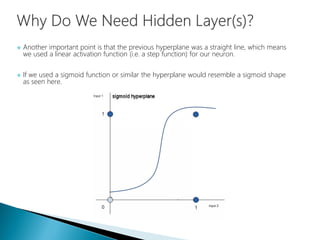
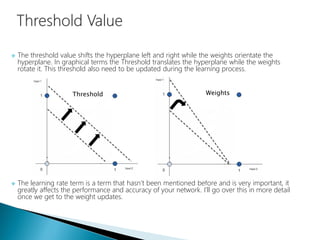
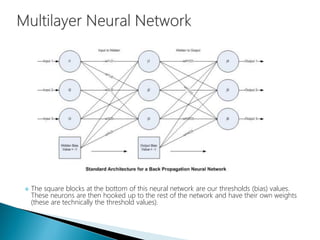

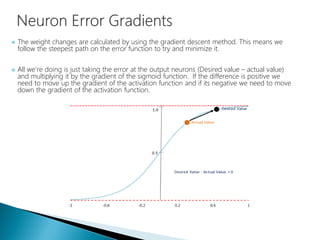



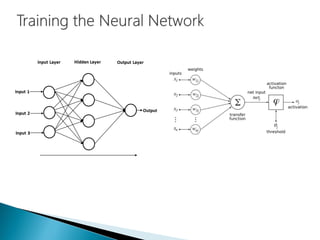
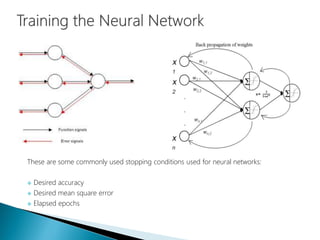


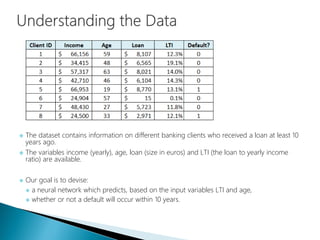

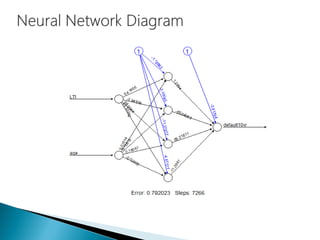


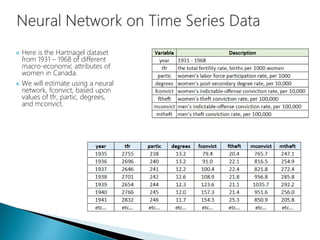
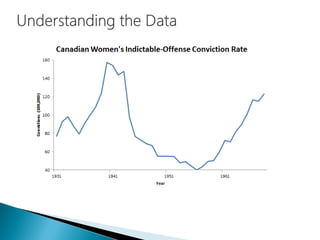

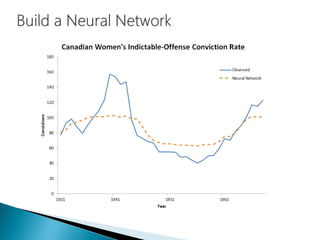


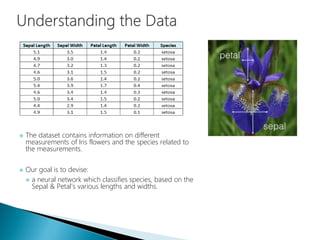

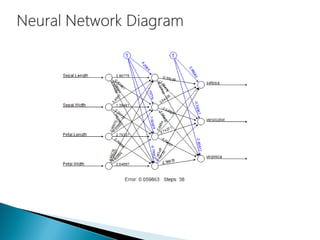




The document discusses the history and functioning of artificial neural networks (ANNs), drawing parallels between biological neural processes and computational models. It covers concepts like multilayer networks, back-propagation, and various applications, including handwriting and face recognition. Additionally, it provides examples of real-world datasets used to test and validate neural network predictions in supervised learning contexts.



















































































