Download to read offline



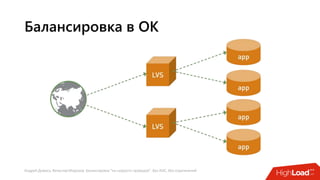
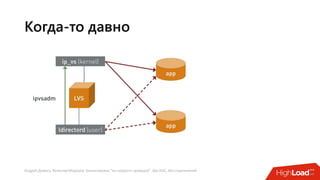
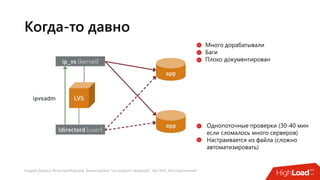
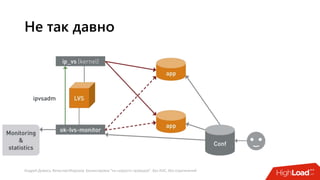
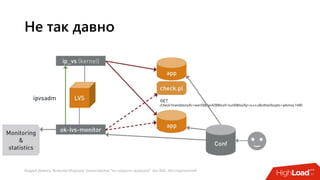
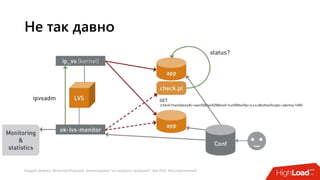
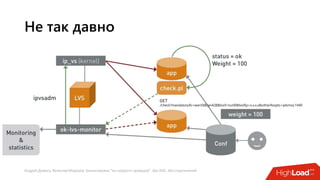
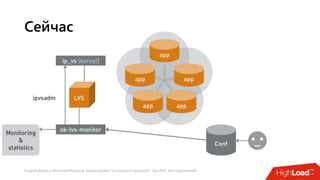
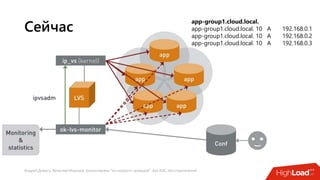
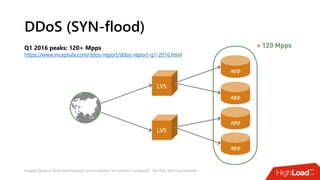
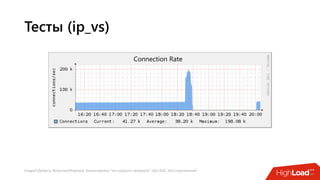
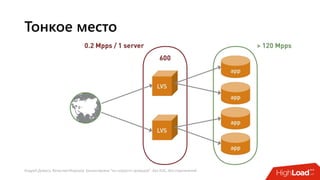
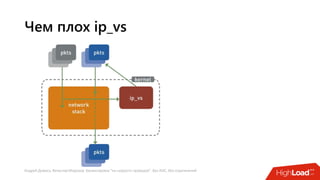
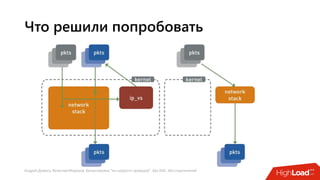
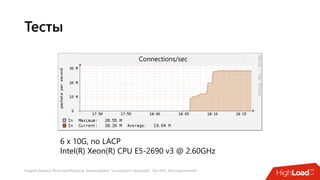
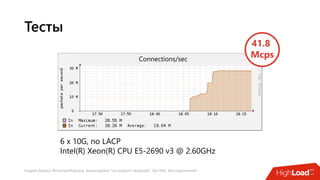
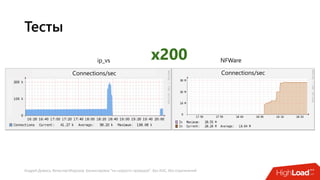
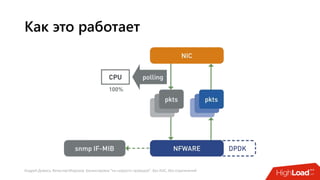
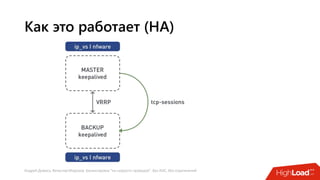
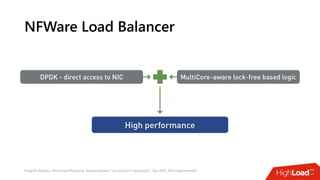

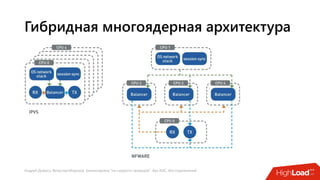
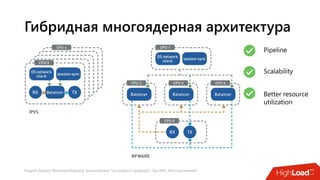
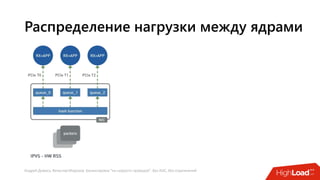
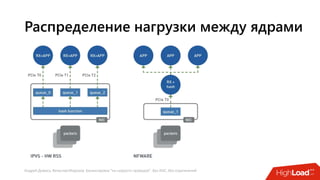
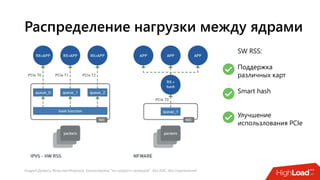
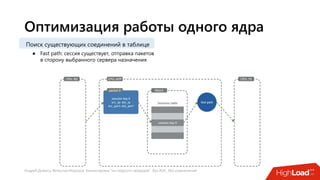
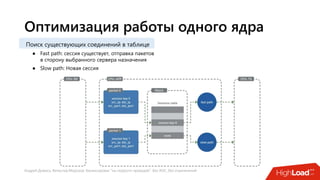
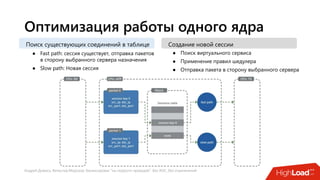
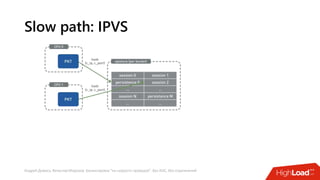
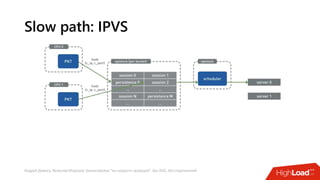
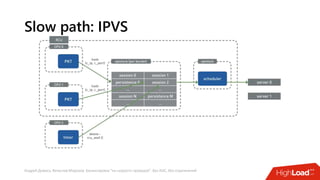
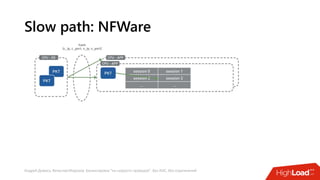
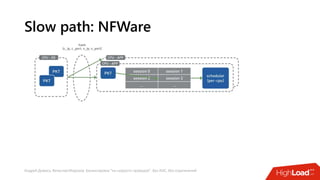
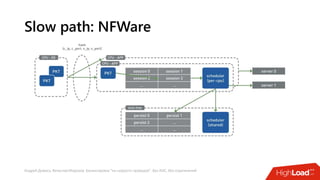

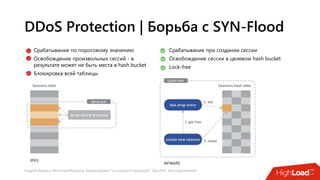



Документ посвящен балансировке трафика 'на скорости проводов' без использования ASIC и описывает решения для борьбы с атаками типа SYN-флуд. Рассматриваются вопросы оптимизации работы серверов, архитектурные особенности, а также преимущества и функциональность системы. В заключении представлены контактные данные авторов для дальнейших вопросов.















































