Downloaded 82 times




























![Creating a GraphX graph
scala> val graph = GraphLoader.edgeListFile(sc, edgesFile, false, 100)
graph: org.apache.spark.graphx.Graph[Int,Int] = org.apache.spark.graphx.
impl.GraphImpl@547a8dc1
scala> graph.edges.count
res3: Long = 16090021
scala> graph.vertices.count
res4: Long = 4548083](https://image.slidesharecdn.com/9ehtshamelahi-sparkandgraphxinthenetflixrecommendersystem-150430120021-conversion-gate01/75/Ehtsham-Elahi-Senior-Research-Engineer-Personalization-Science-and-Engineering-Group-at-Netflix-at-MLconf-SEA-5-01-15-63-2048.jpg)



![References
● Topic Sensitive Pagerank [Haveliwala, 2002]
● Latent Dirichlet Allocation [Blei, 2003]](https://image.slidesharecdn.com/9ehtshamelahi-sparkandgraphxinthenetflixrecommendersystem-150430120021-conversion-gate01/75/Ehtsham-Elahi-Senior-Research-Engineer-Personalization-Science-and-Engineering-Group-at-Netflix-at-MLconf-SEA-5-01-15-67-2048.jpg)

The document discusses the implementation of Spark and GraphX in Netflix's recommender system, aiming to enhance content discovery for over 62 million members. It details the challenges of scaling machine learning algorithms across various devices and countries, and presents solutions using distributed algorithms to perform tasks like graph diffusion and clustering. Findings indicate that GraphX significantly improves performance for large datasets and highlights lessons learned regarding iterative machine learning and state management.
Explains the role of algorithms for member satisfaction and content recommendations to maximize retention.
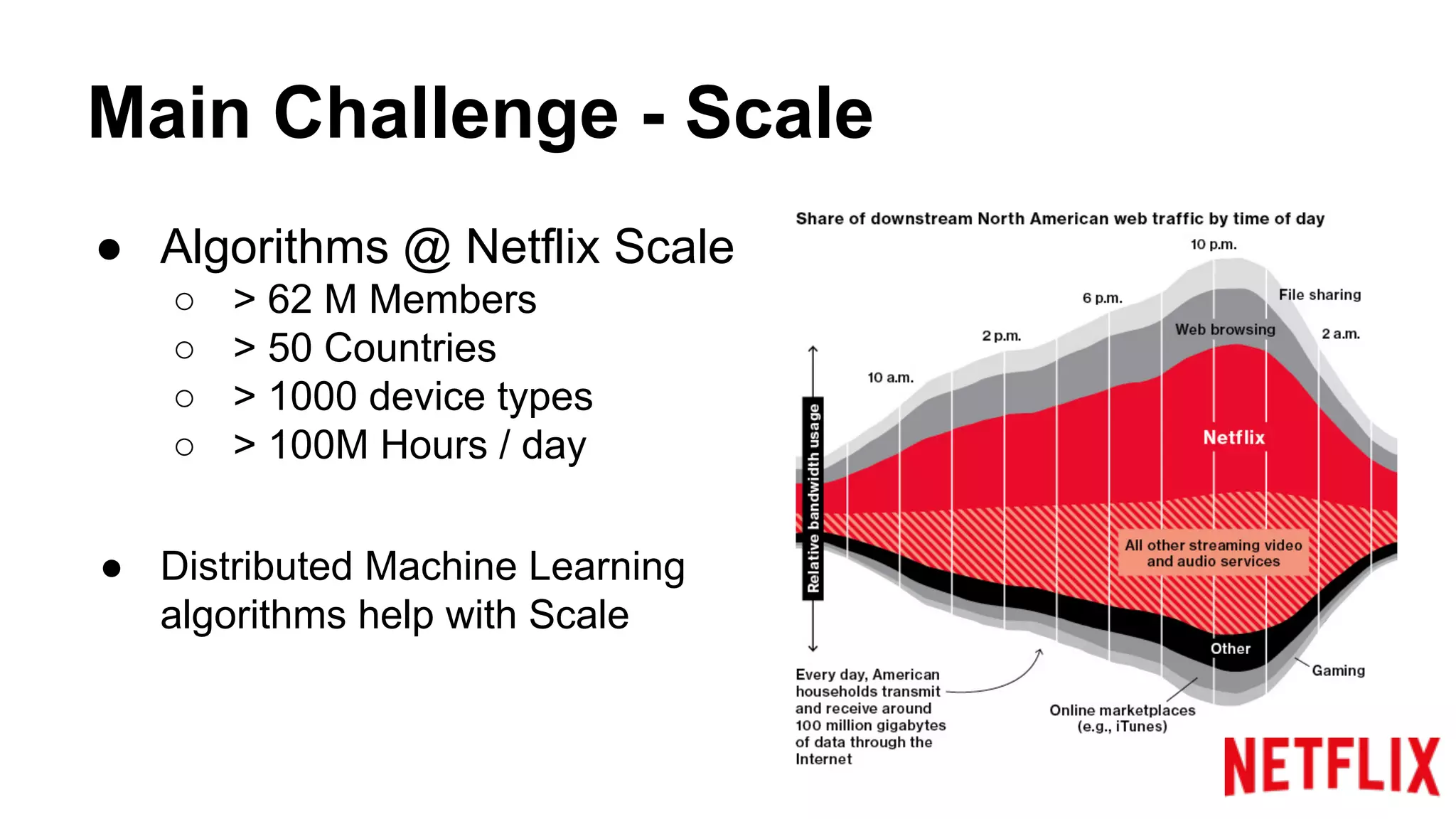
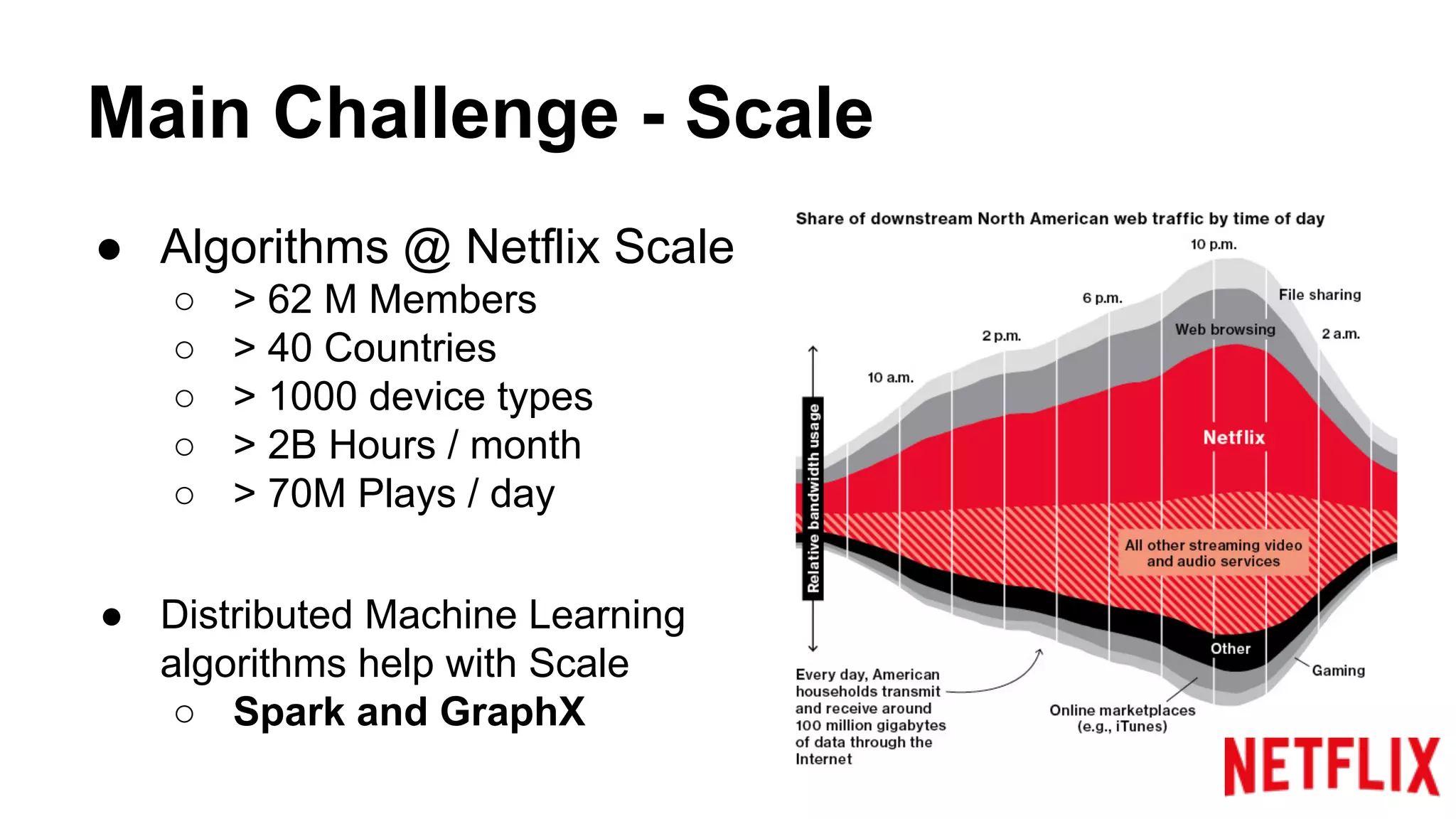
Discusses the scale of Netflix's service with over 62M members across 50 countries and the need for distributed machine learning.
Introduces Spark as a distributed computational engine and GraphX for graph analytics using Resilient Distributed Datasets.
Outlines two machine learning problems: ranking items and finding related clusters using Graph Diffusion Algorithms and Probabilistic Graphical Models.
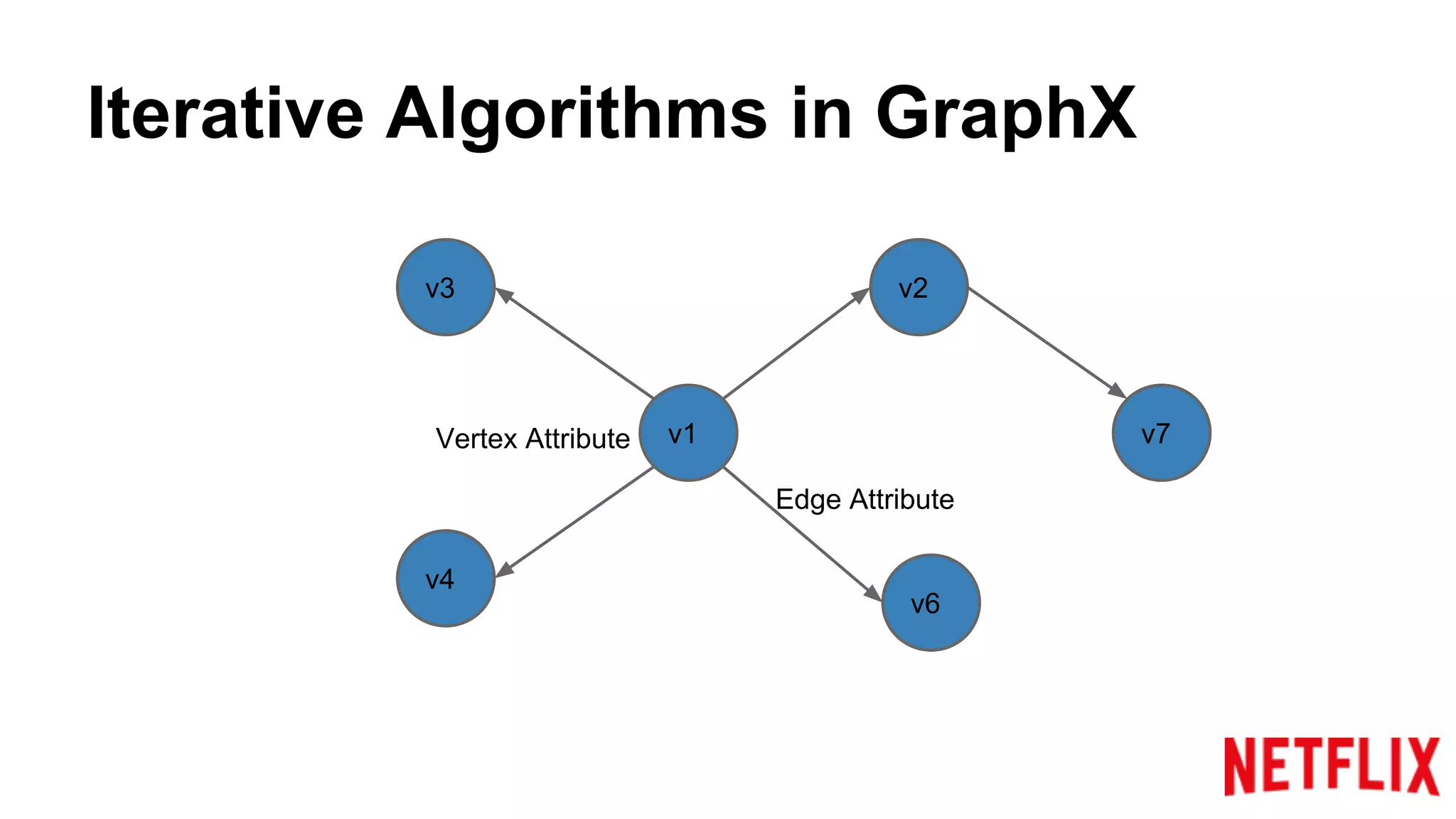
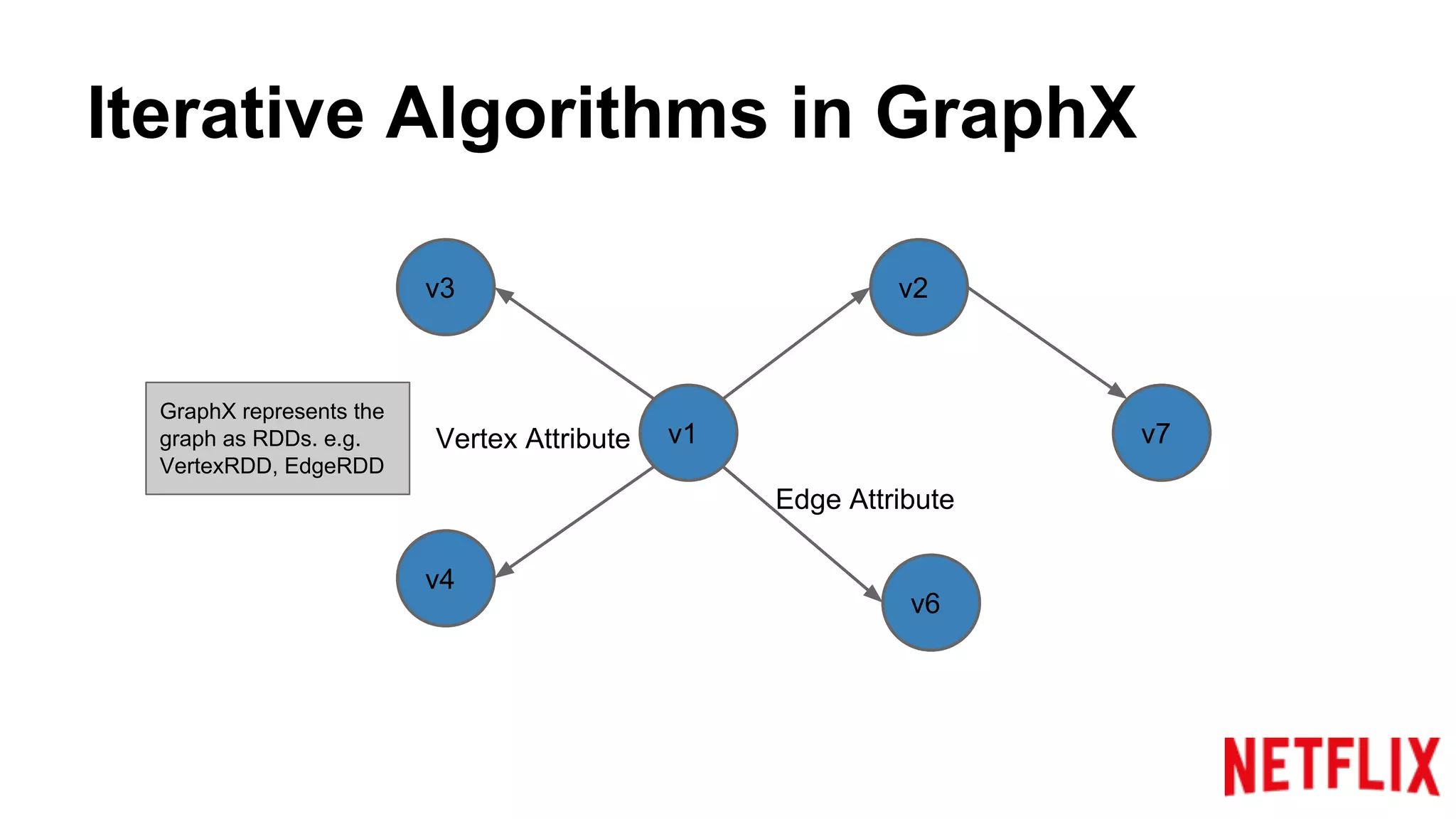
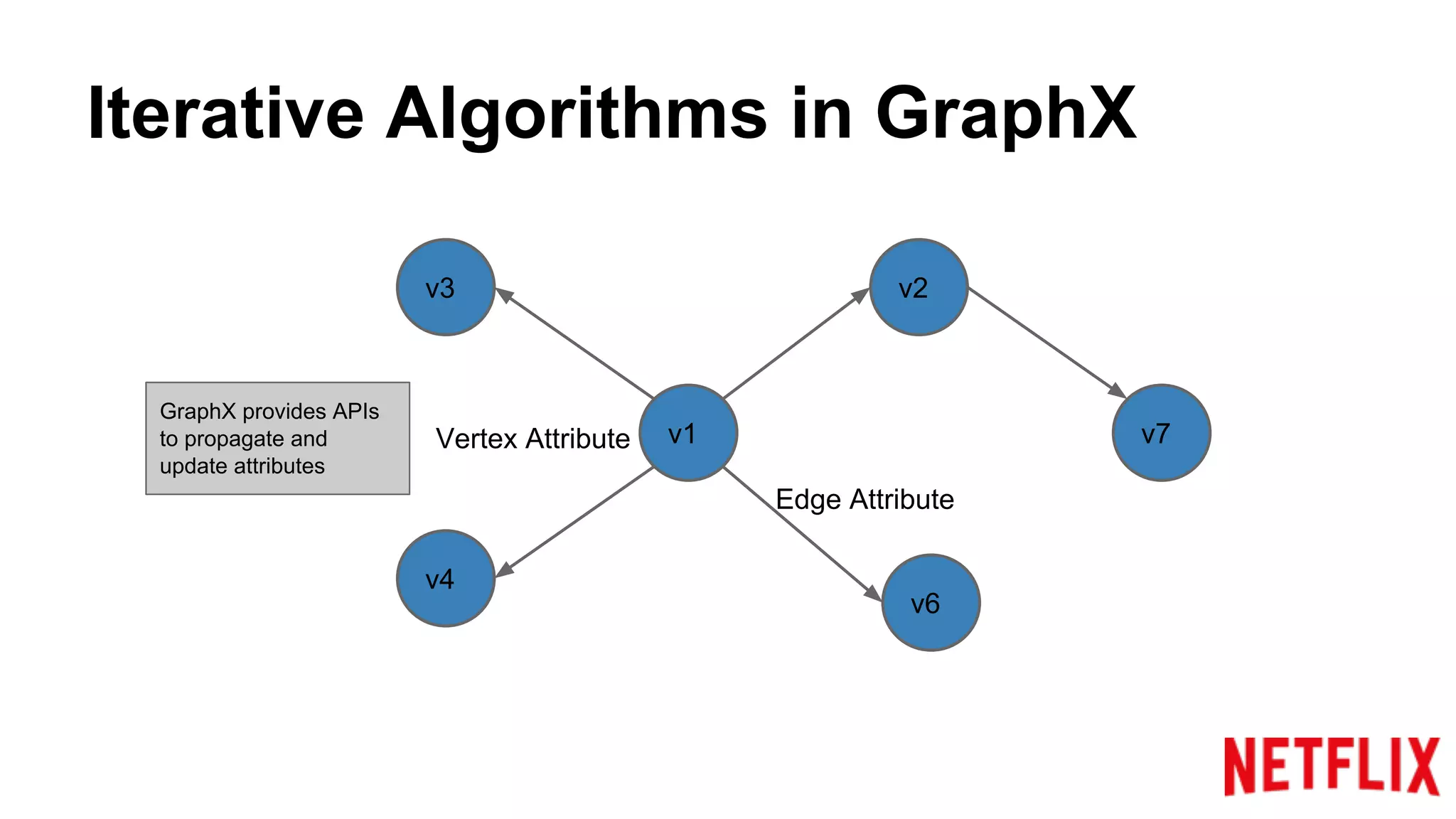
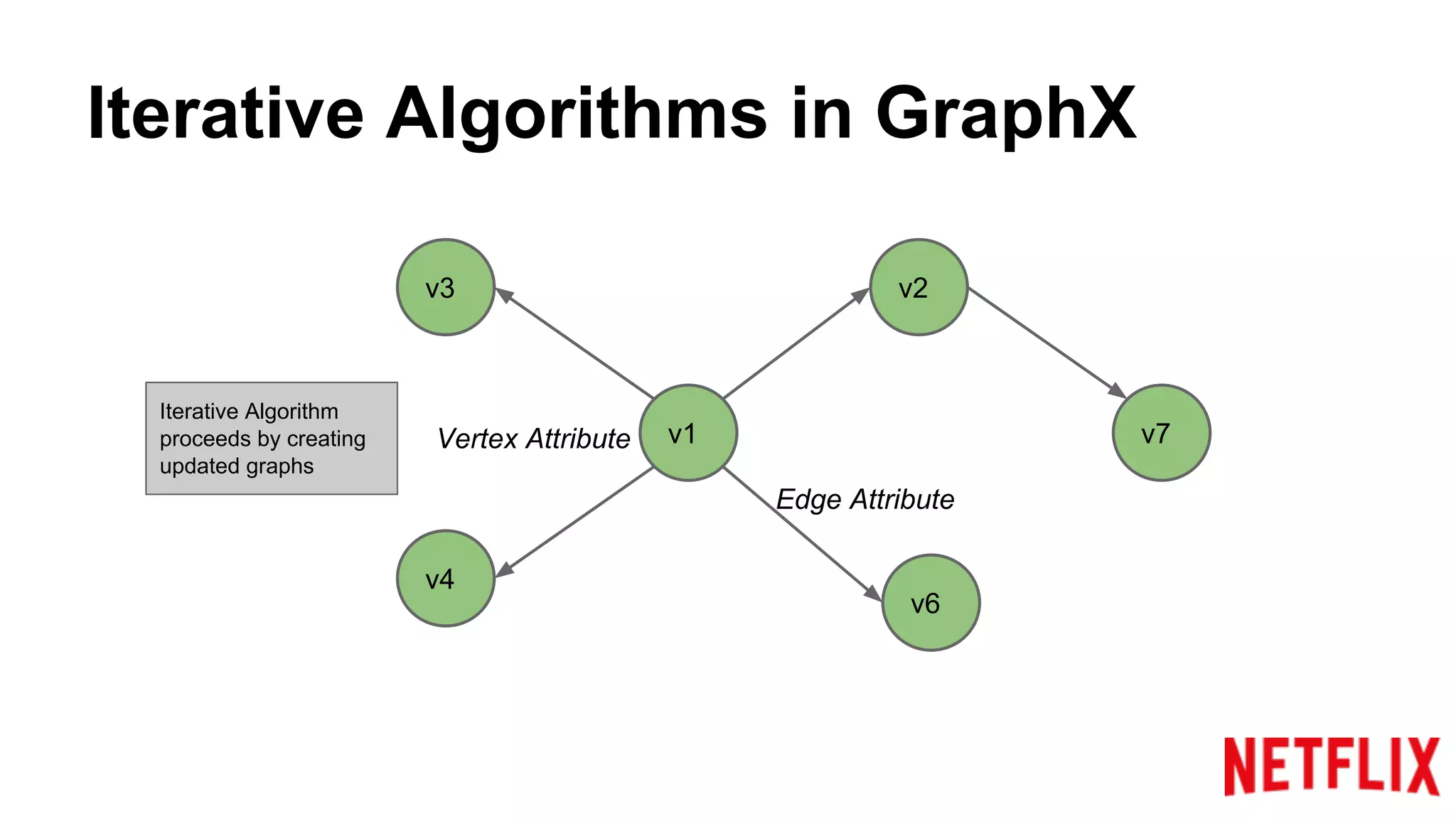
Describes how GraphX represents graphs and utilizes APIs for propagating and updating attributes in iterative algorithms.
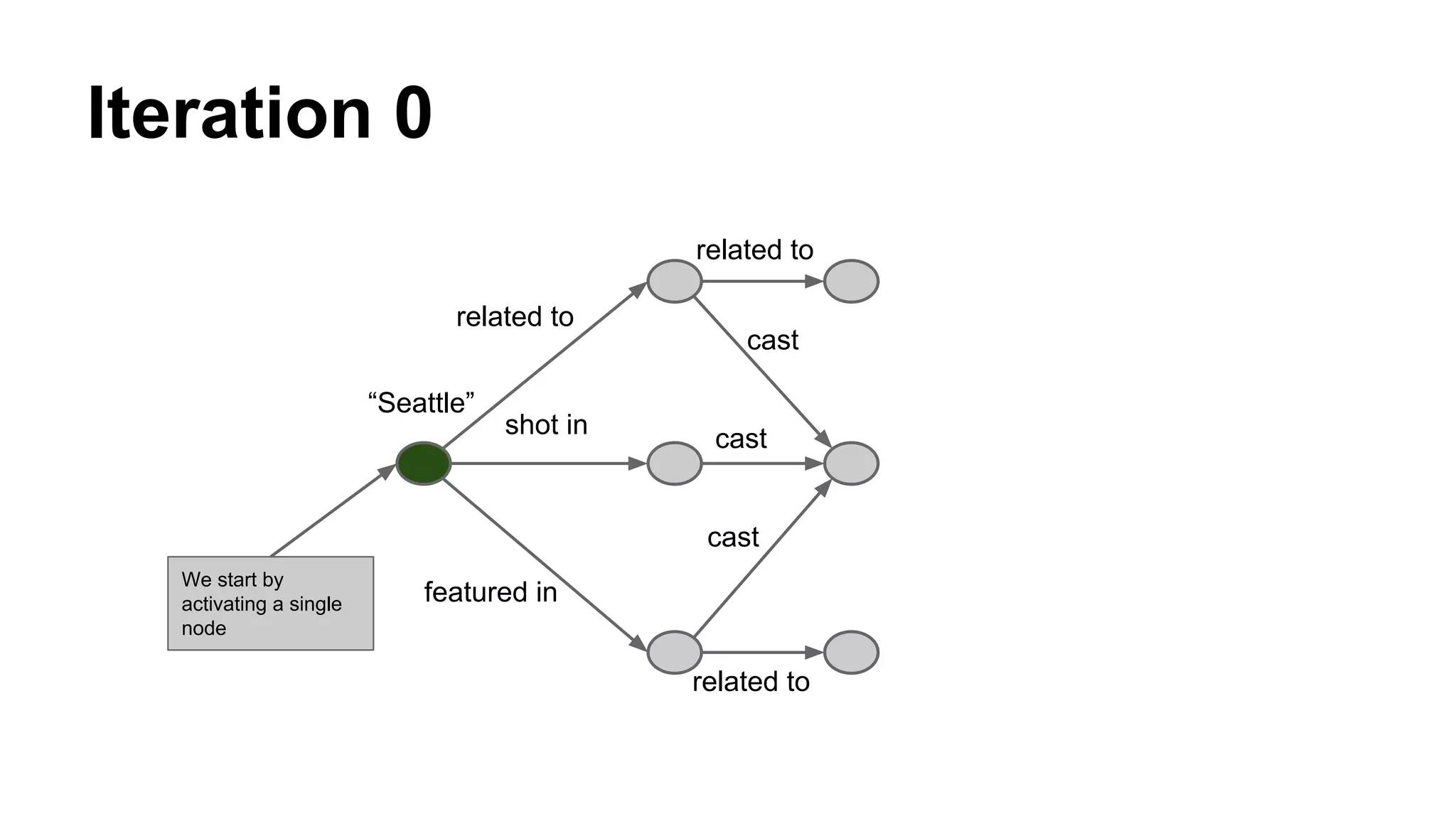
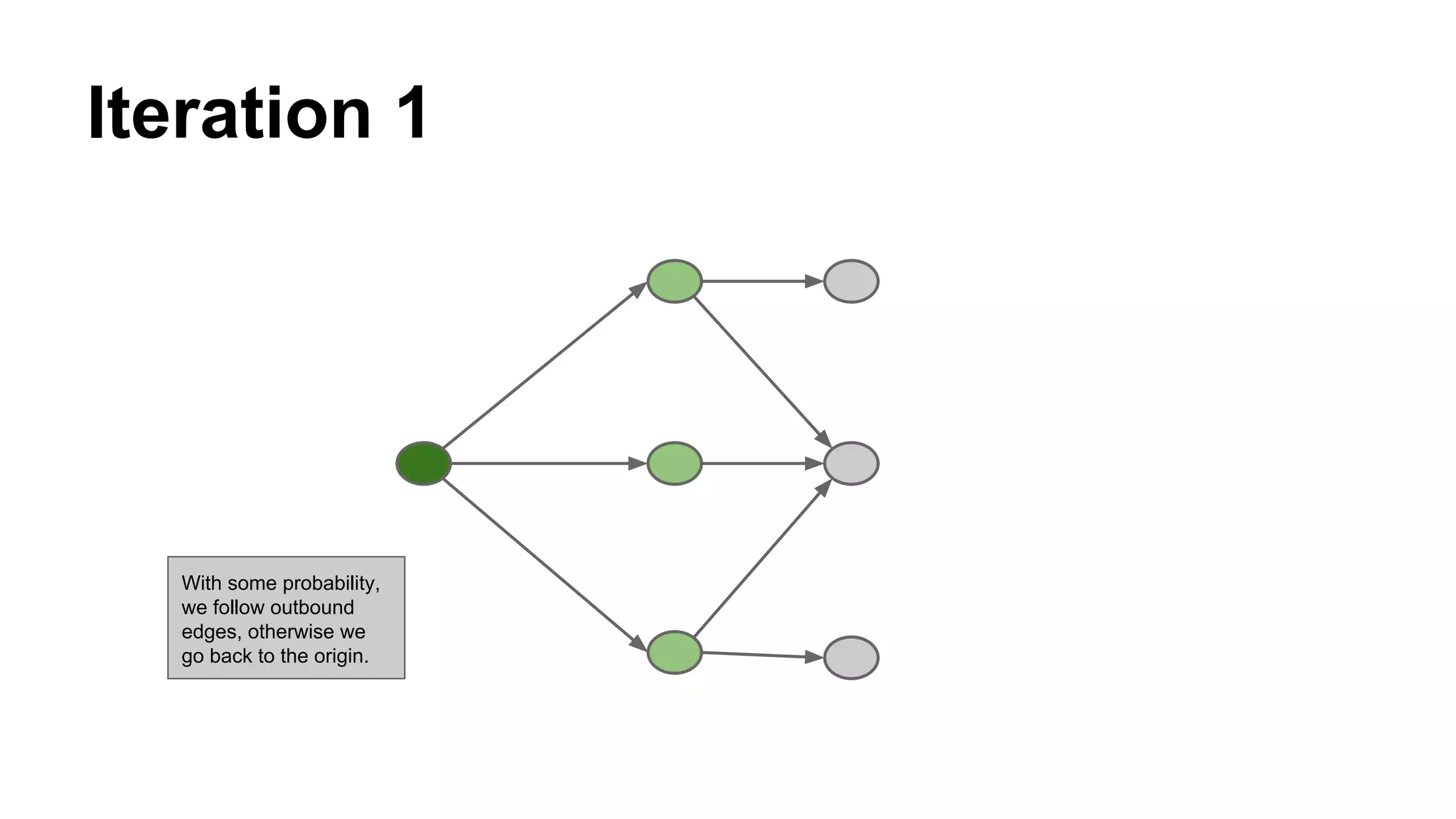
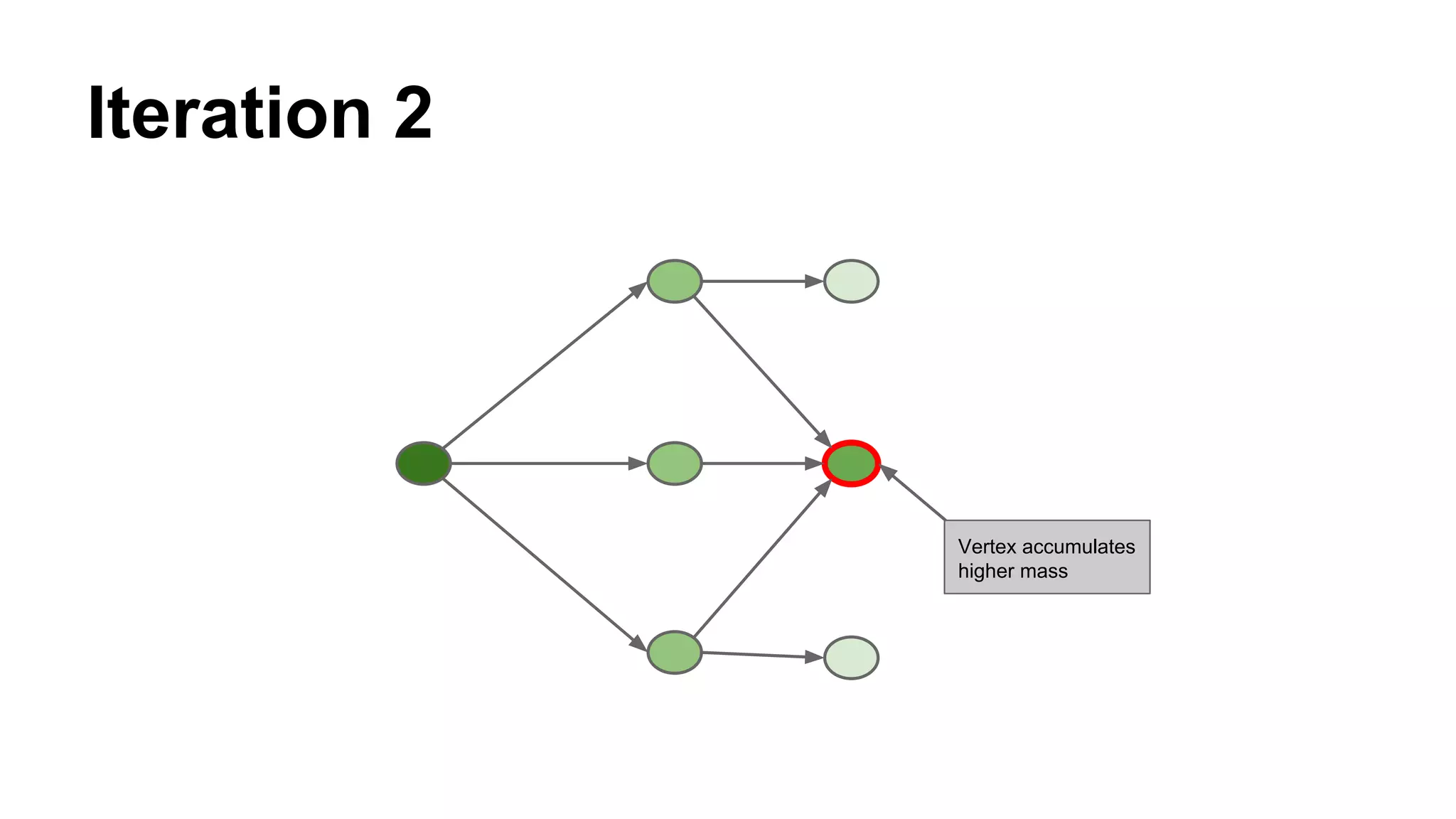
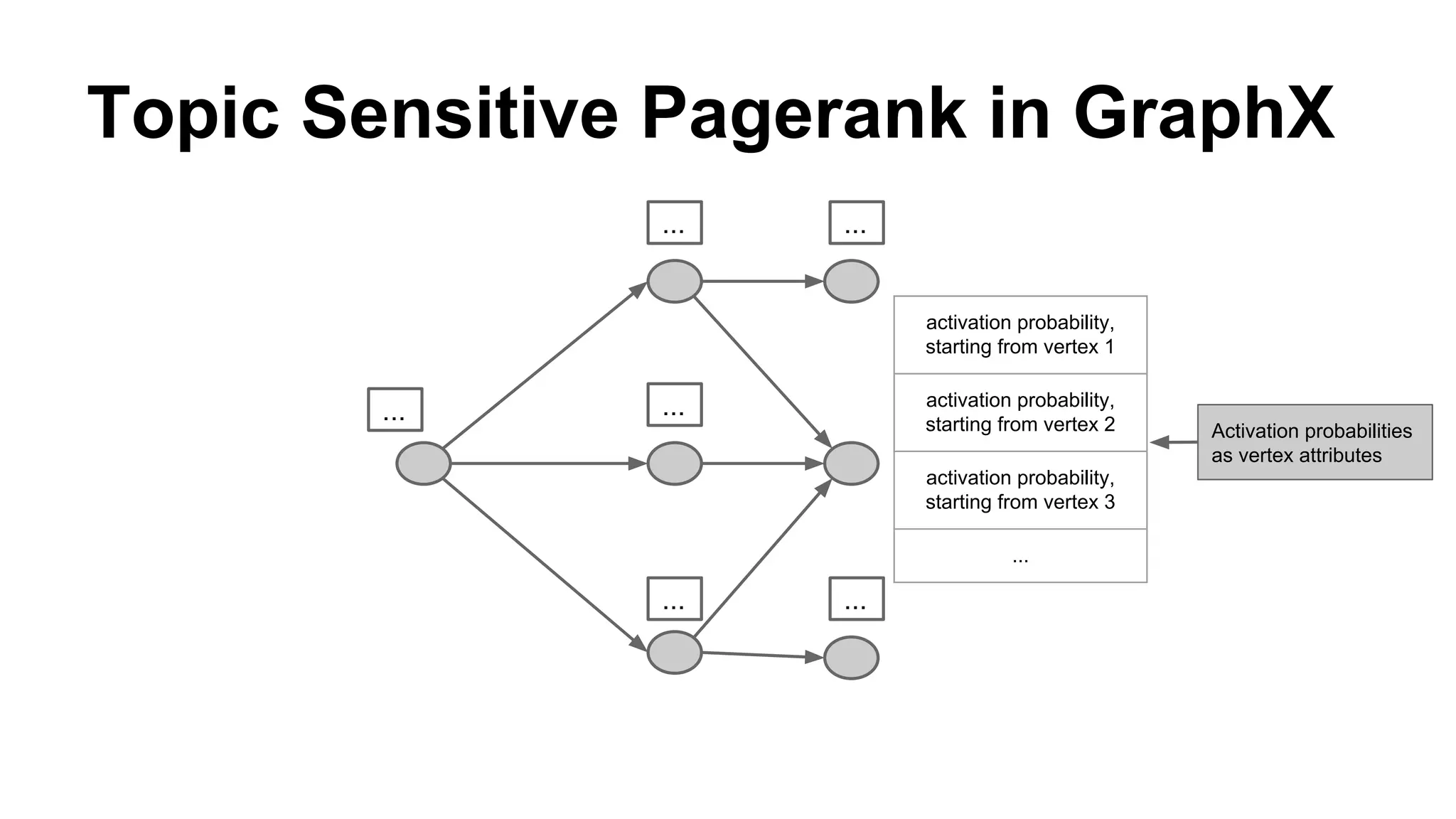
Details on the Topic Sensitive Pagerank, a graph diffusion algorithm, which captures vertex importance regarding specific topics.
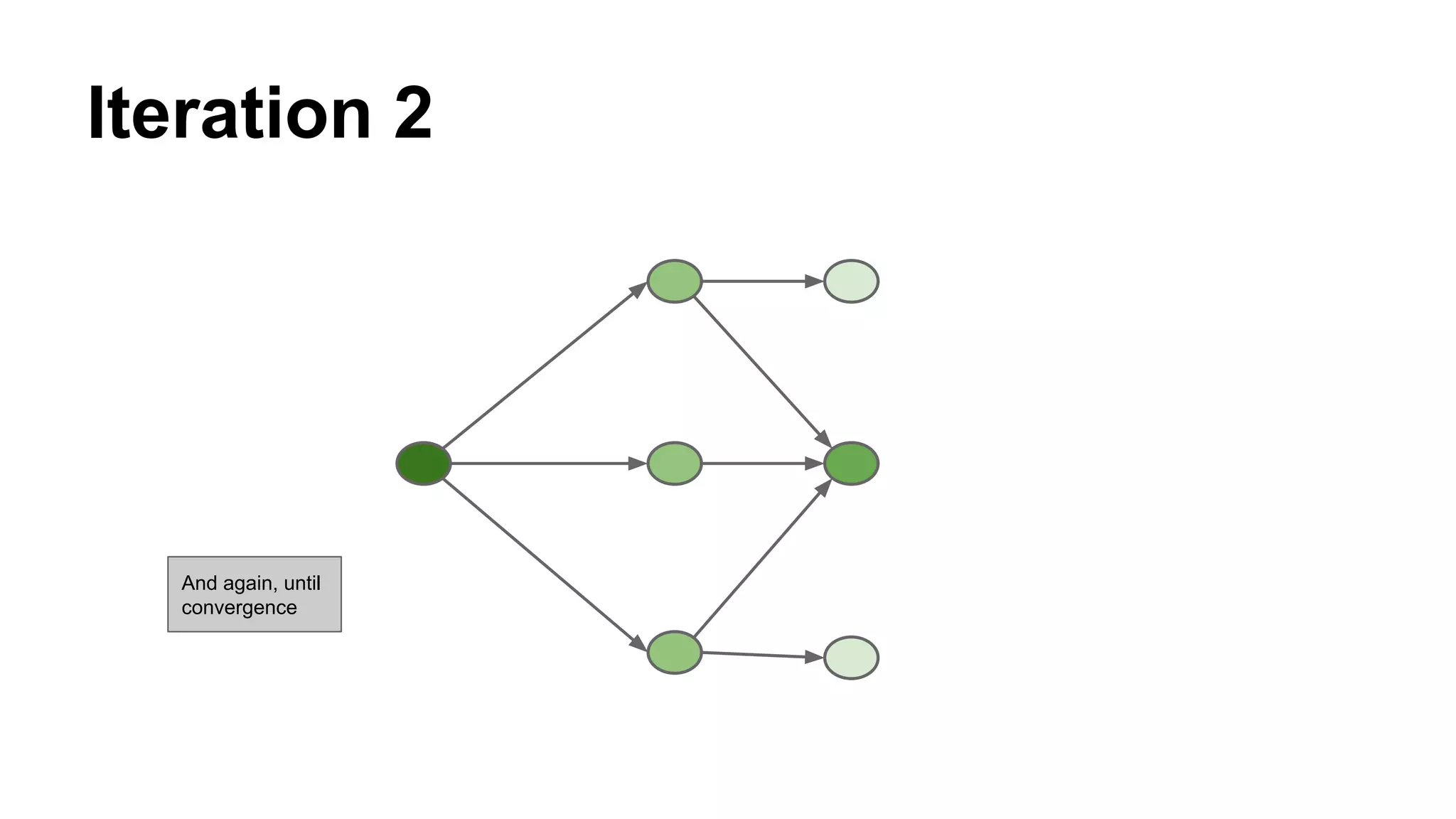
Explains the iterative process where nodes accumulate mass through connections until convergence is achieved.
Outlines the implementation process in GraphX to run multiple propagations of Topic Sensitive Pagerank in parallel.
Introduces Latent Dirichlet Allocation as a method for identifying video clusters and topics within Netflix's data.
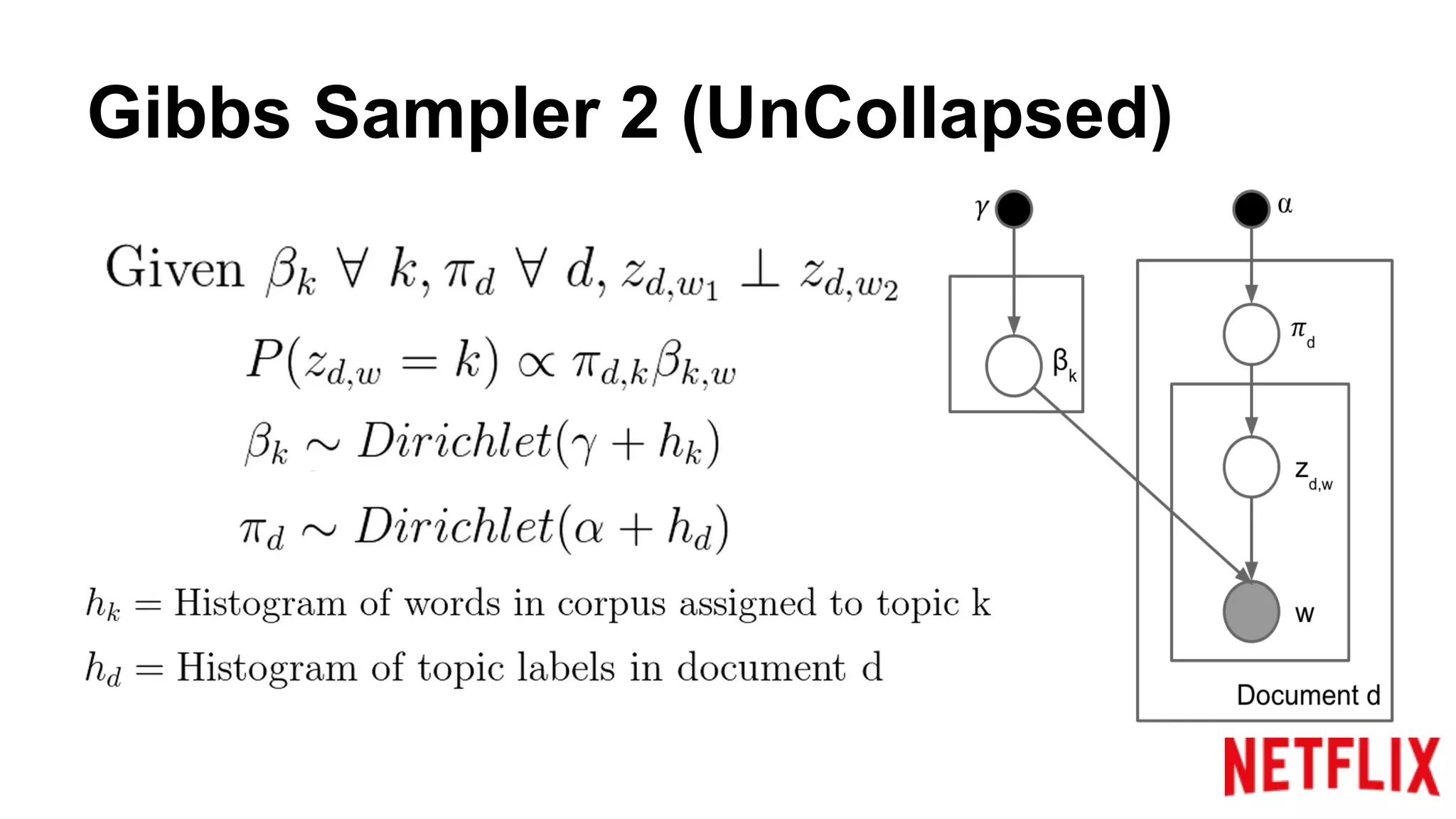
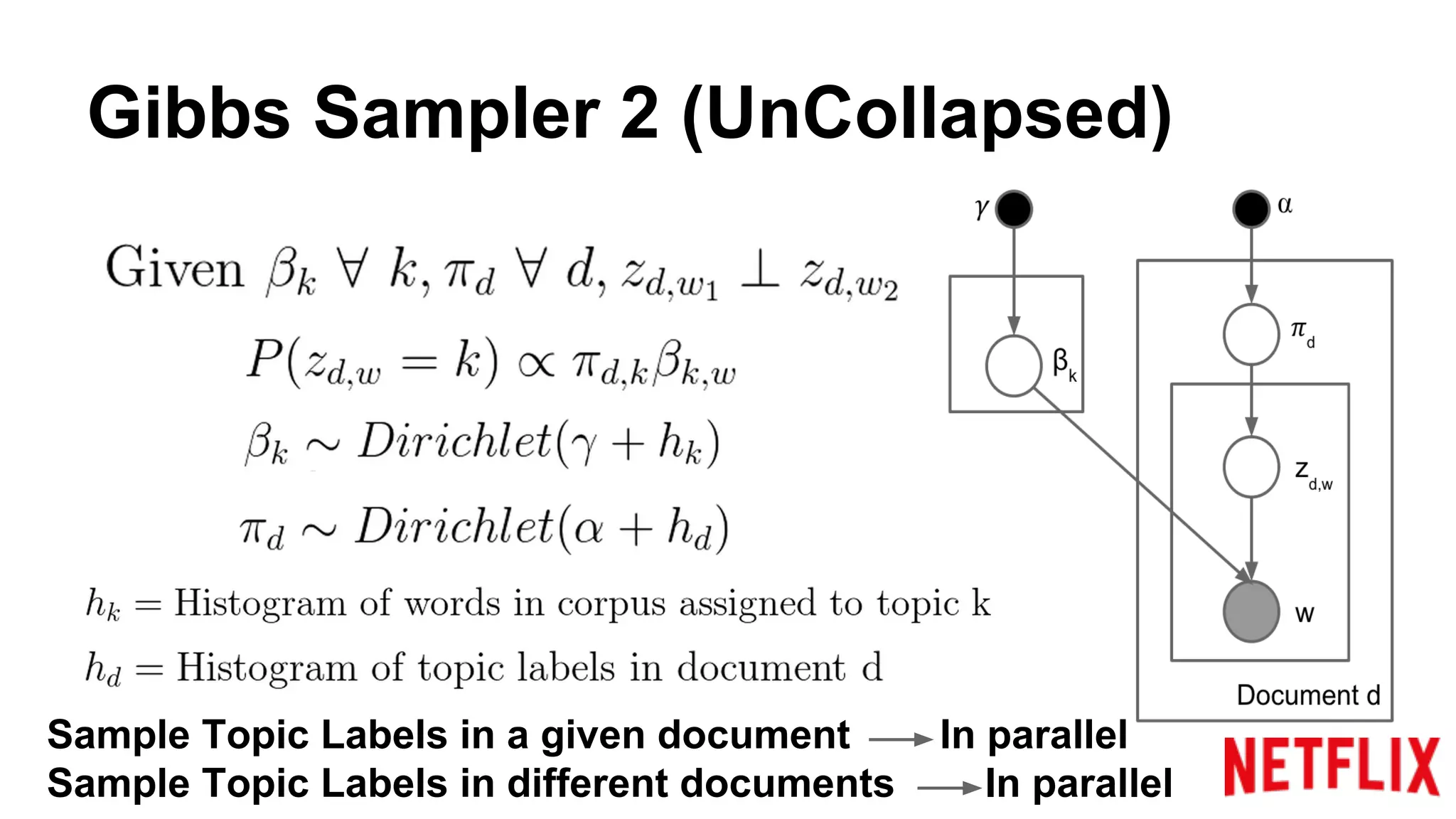
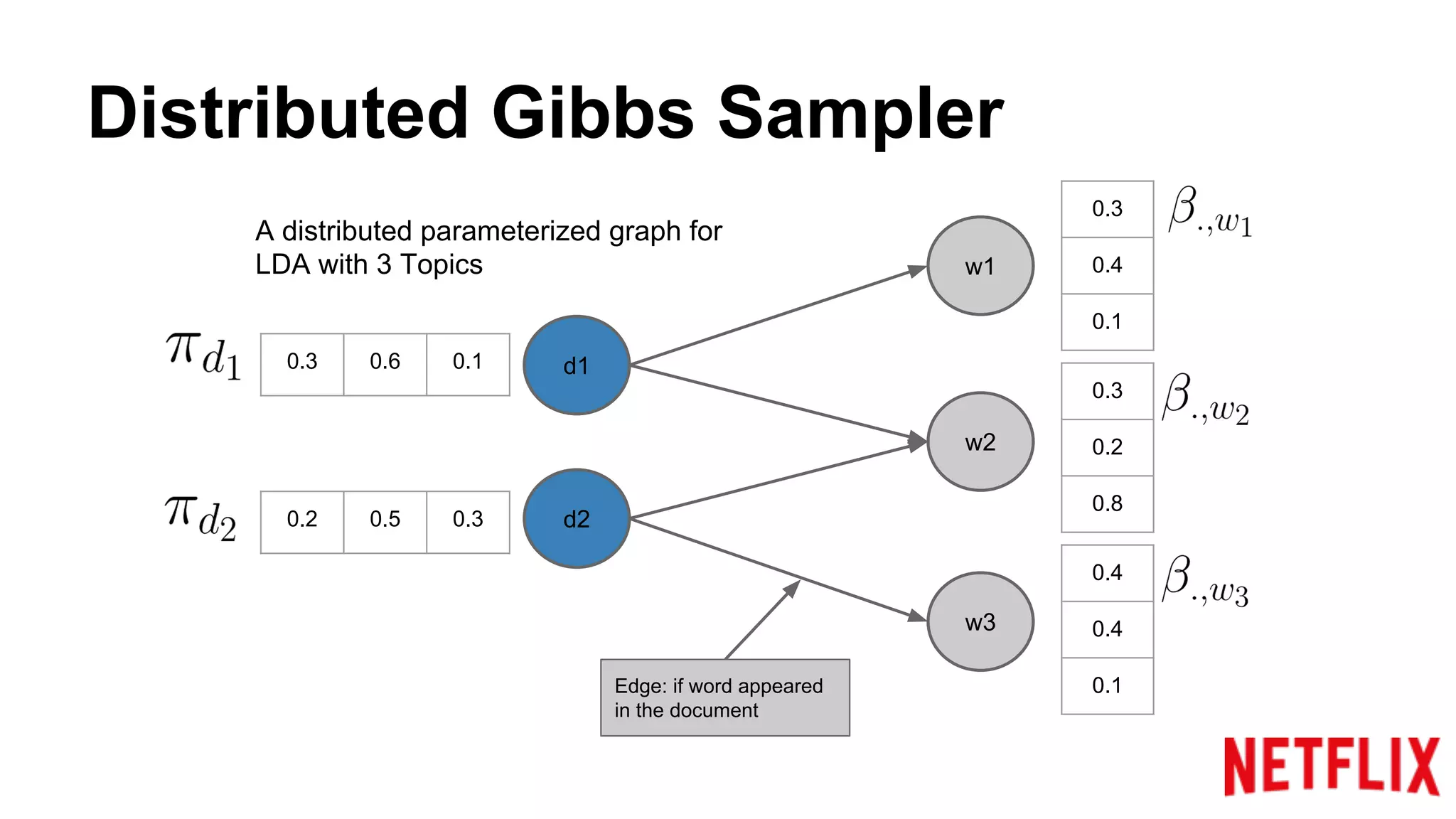
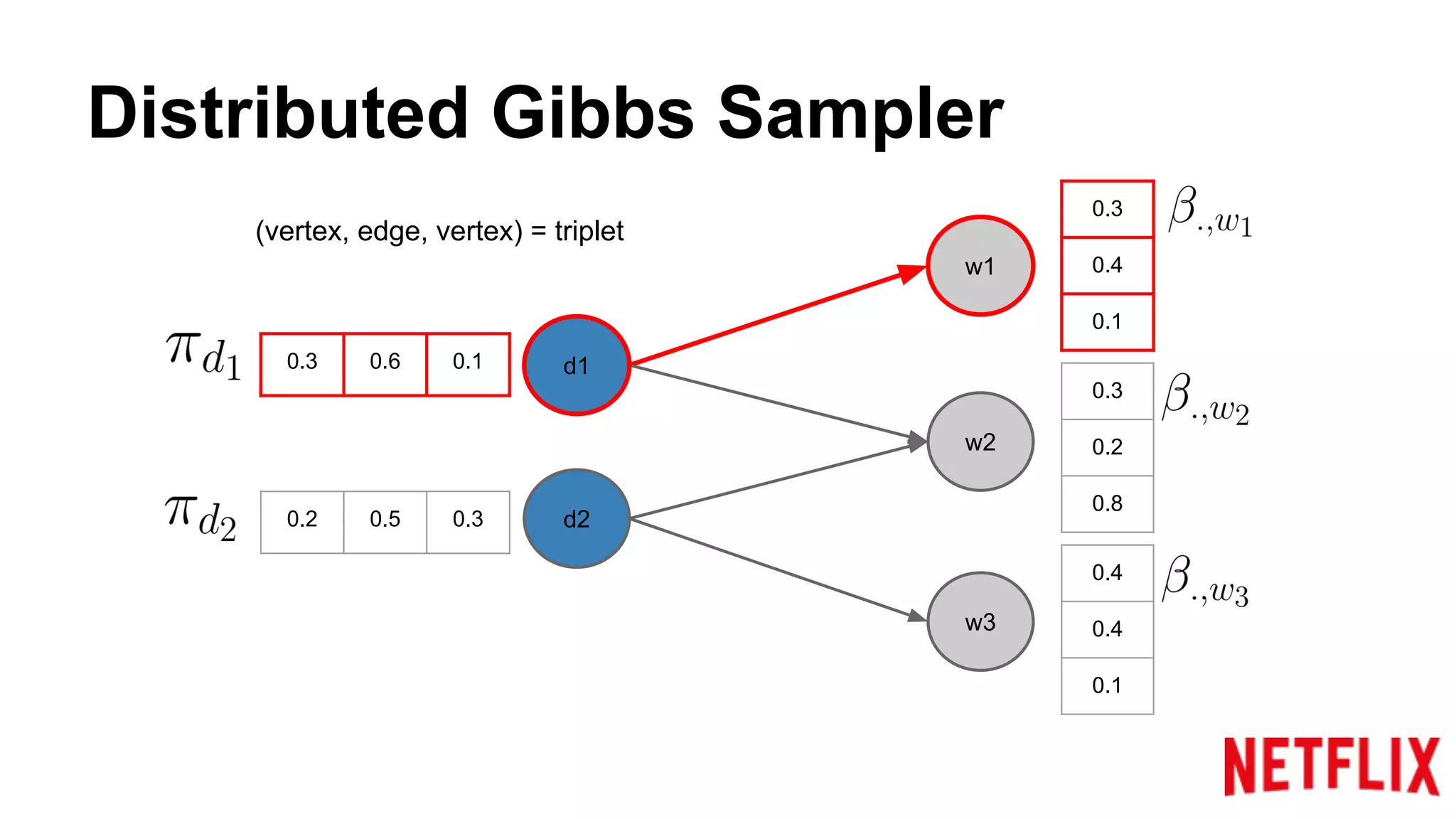
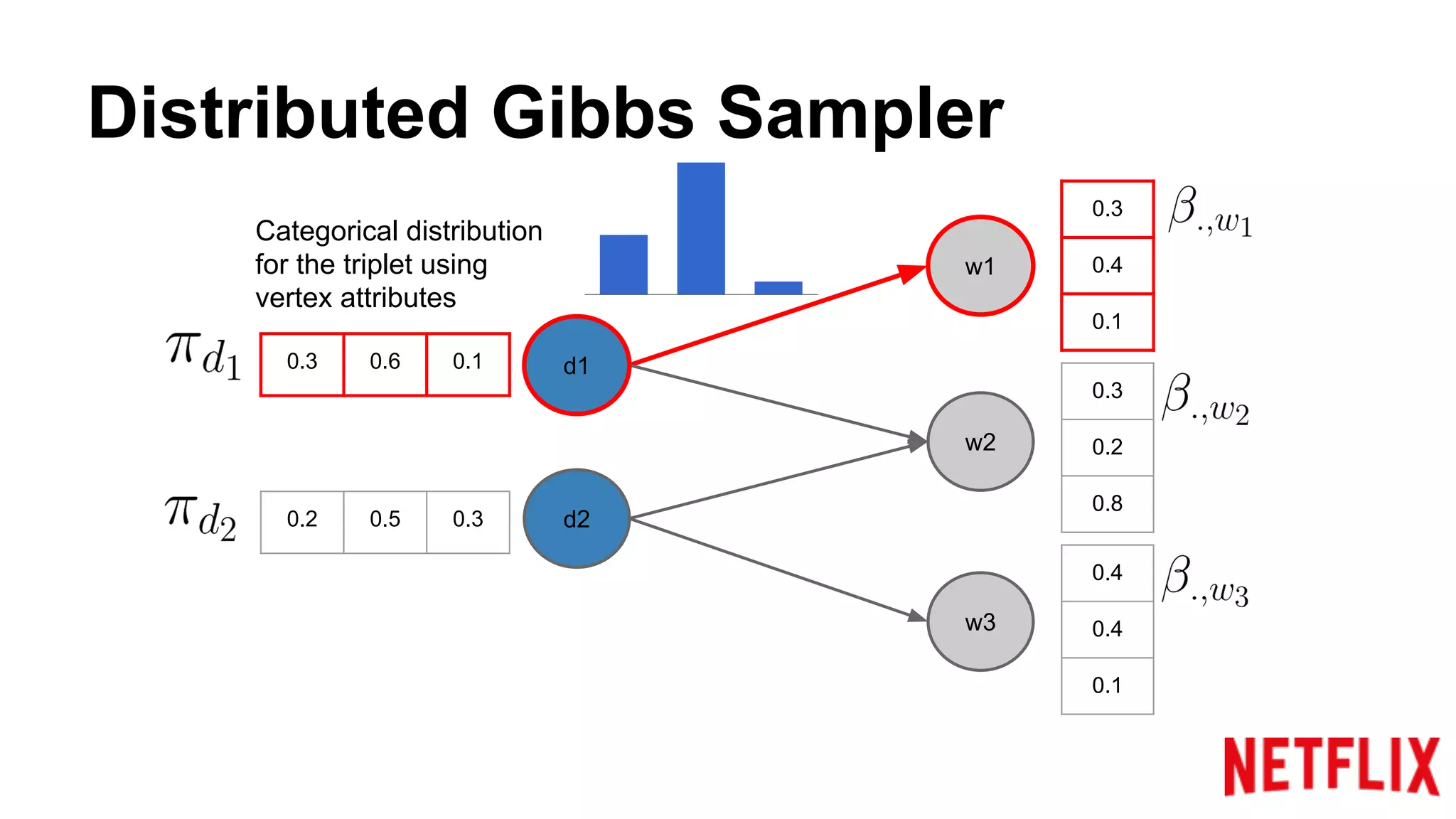
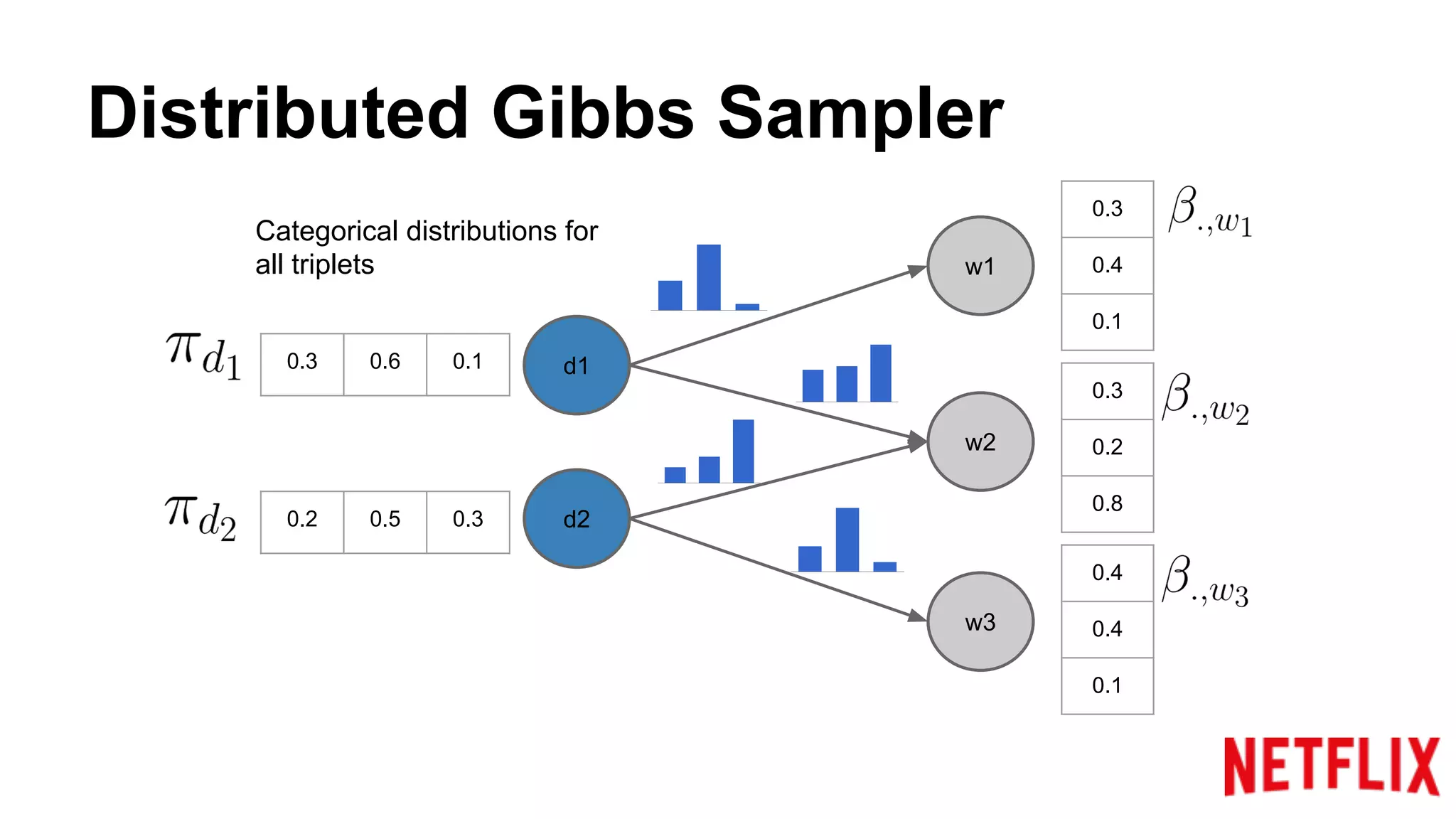
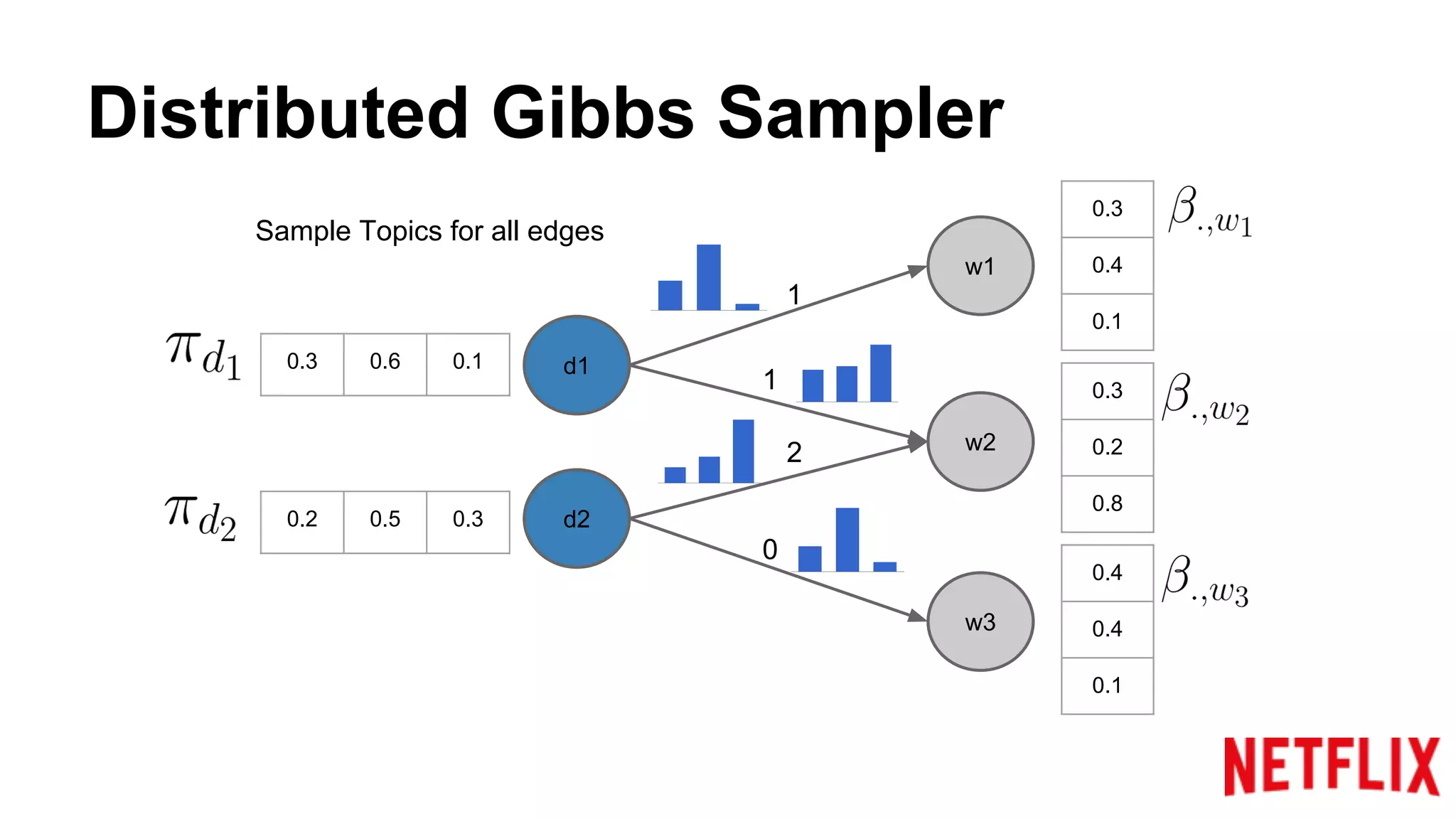
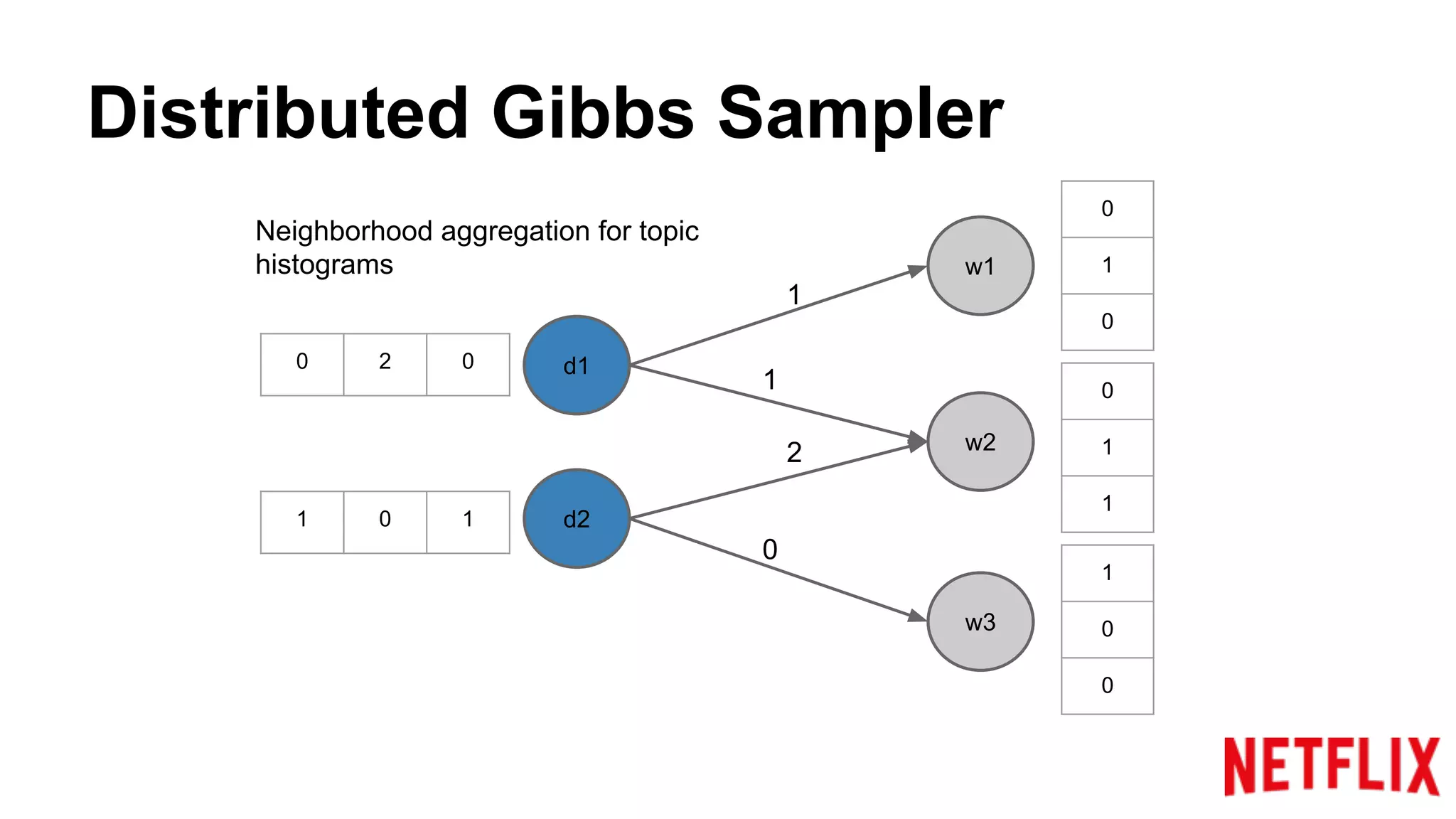
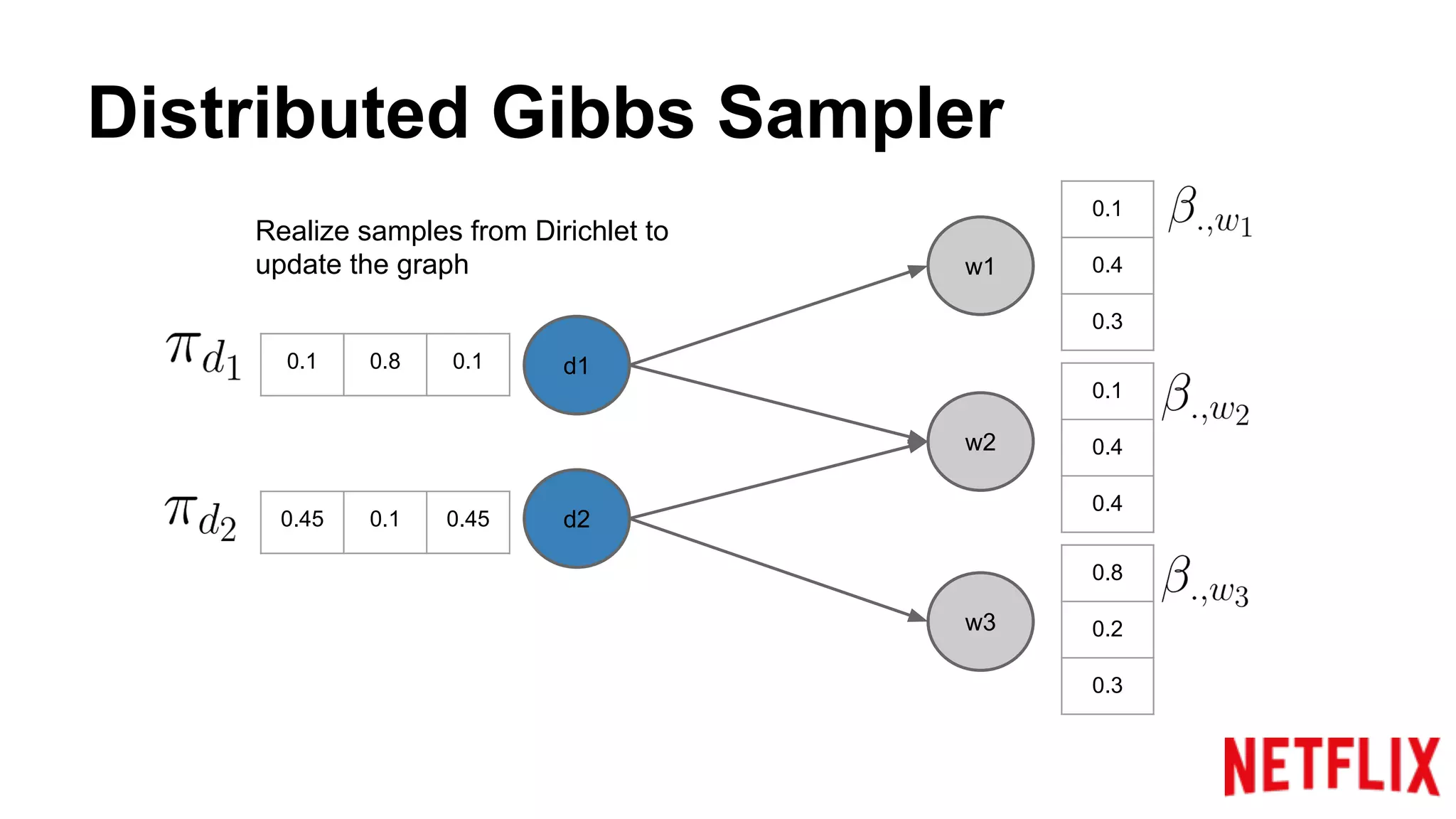
Addresses the inference parallelization challenge in LDA and presents approaches using Gibbs Sampling.
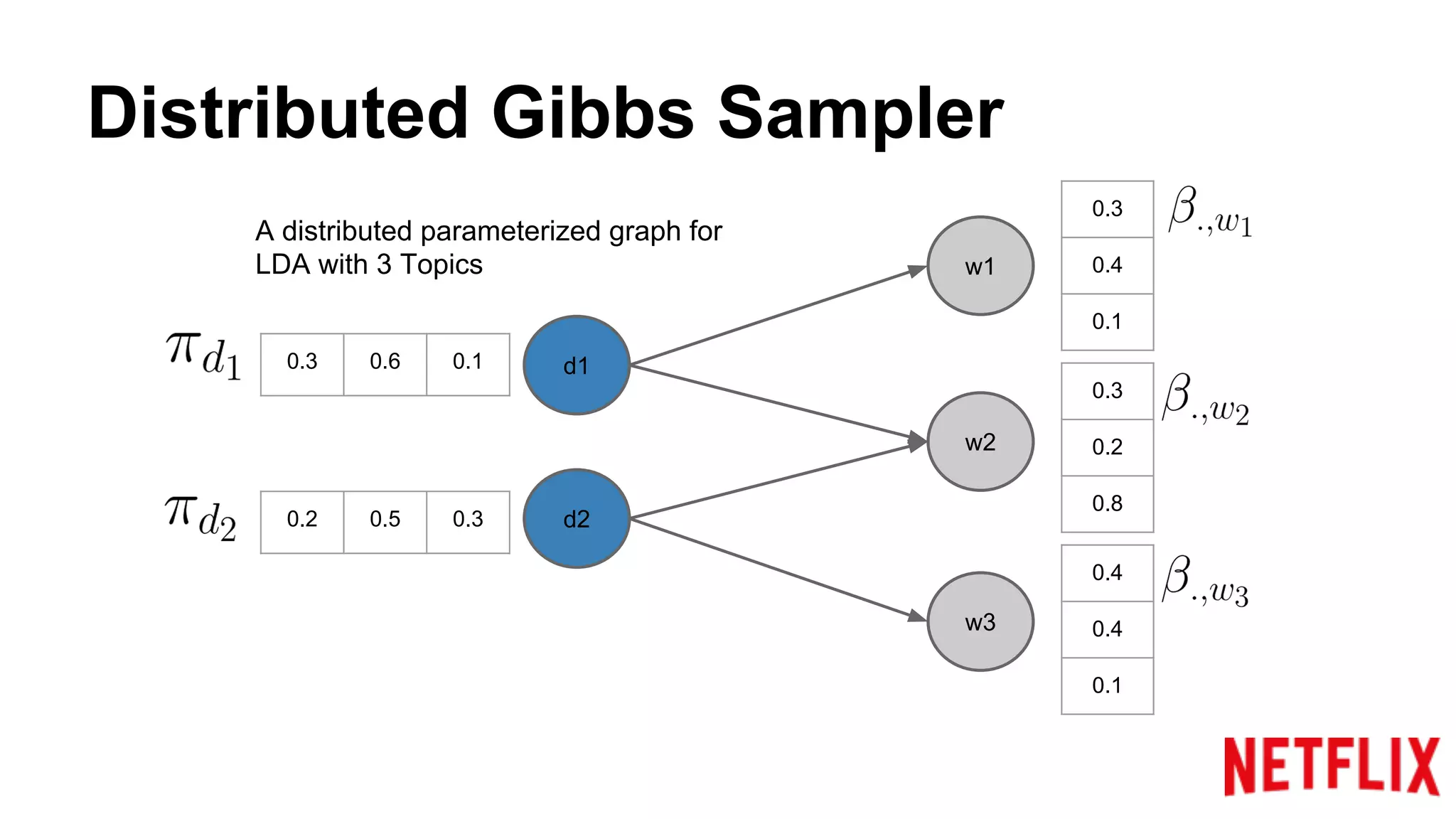
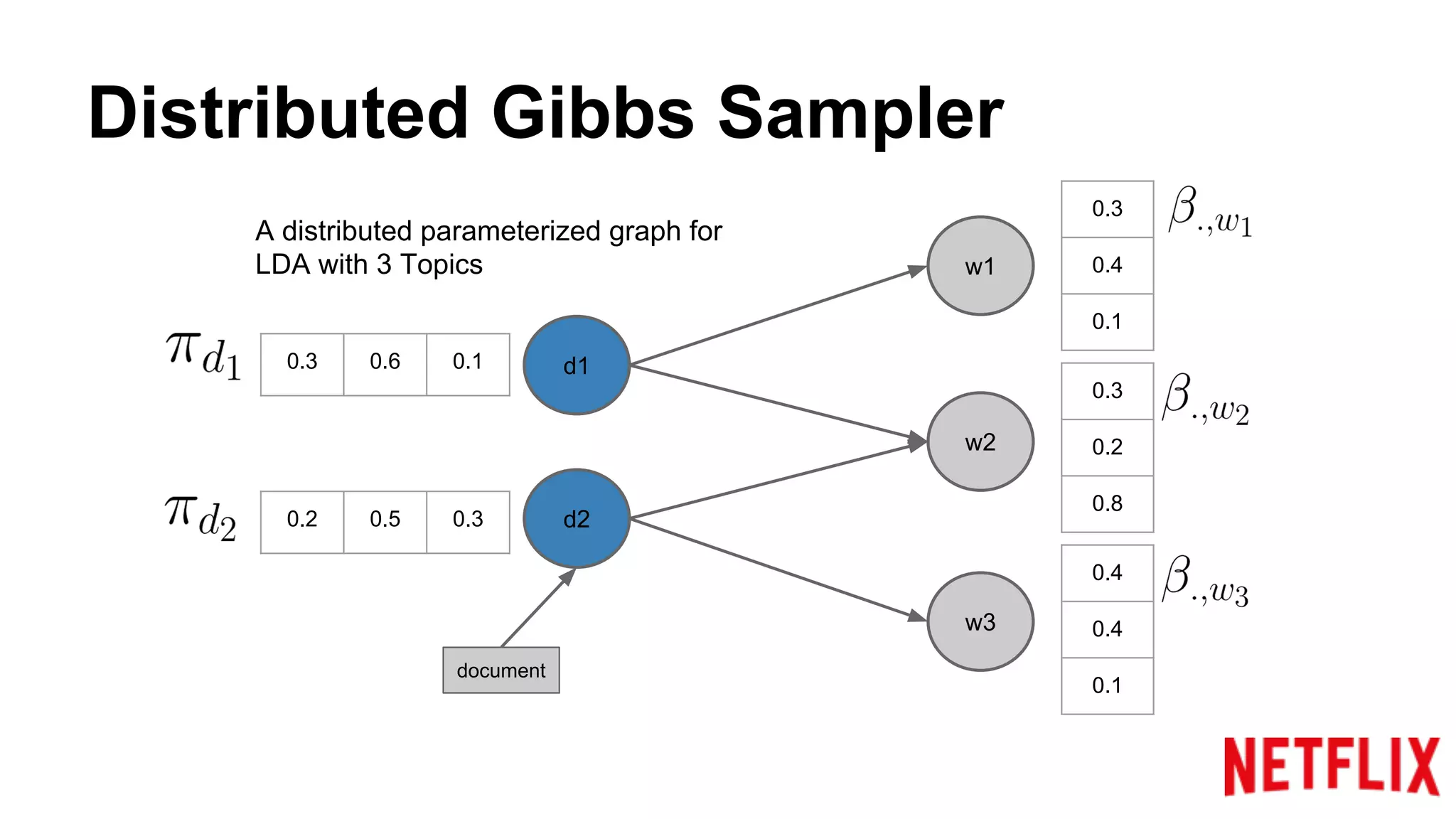
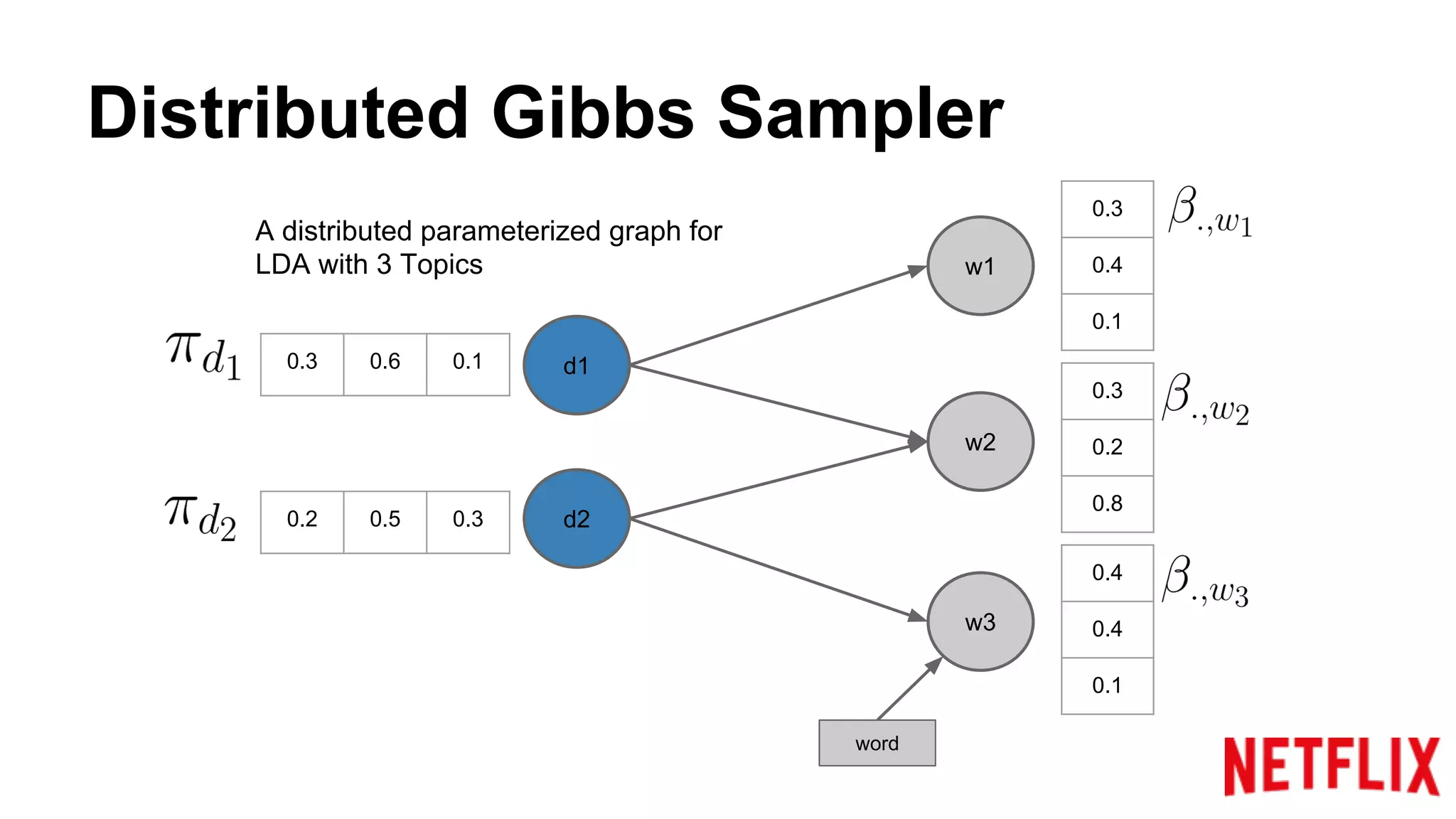
Discusses the structure of distributed Gibbs Samplers for LDA, including word-document relationships and sampling processes.
Presents example results from LDA showing clusters of movies and kids shows identified by topics.
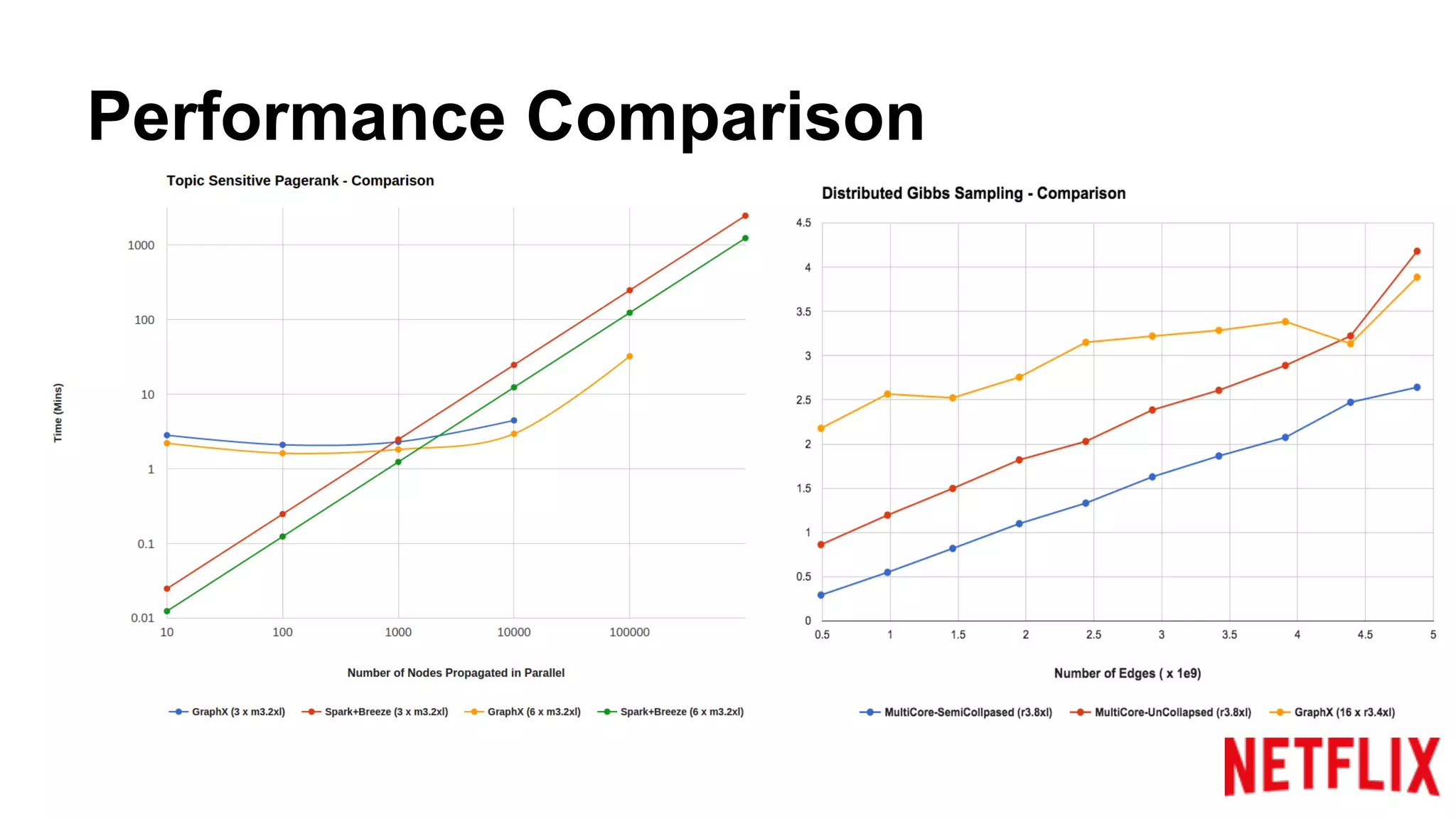
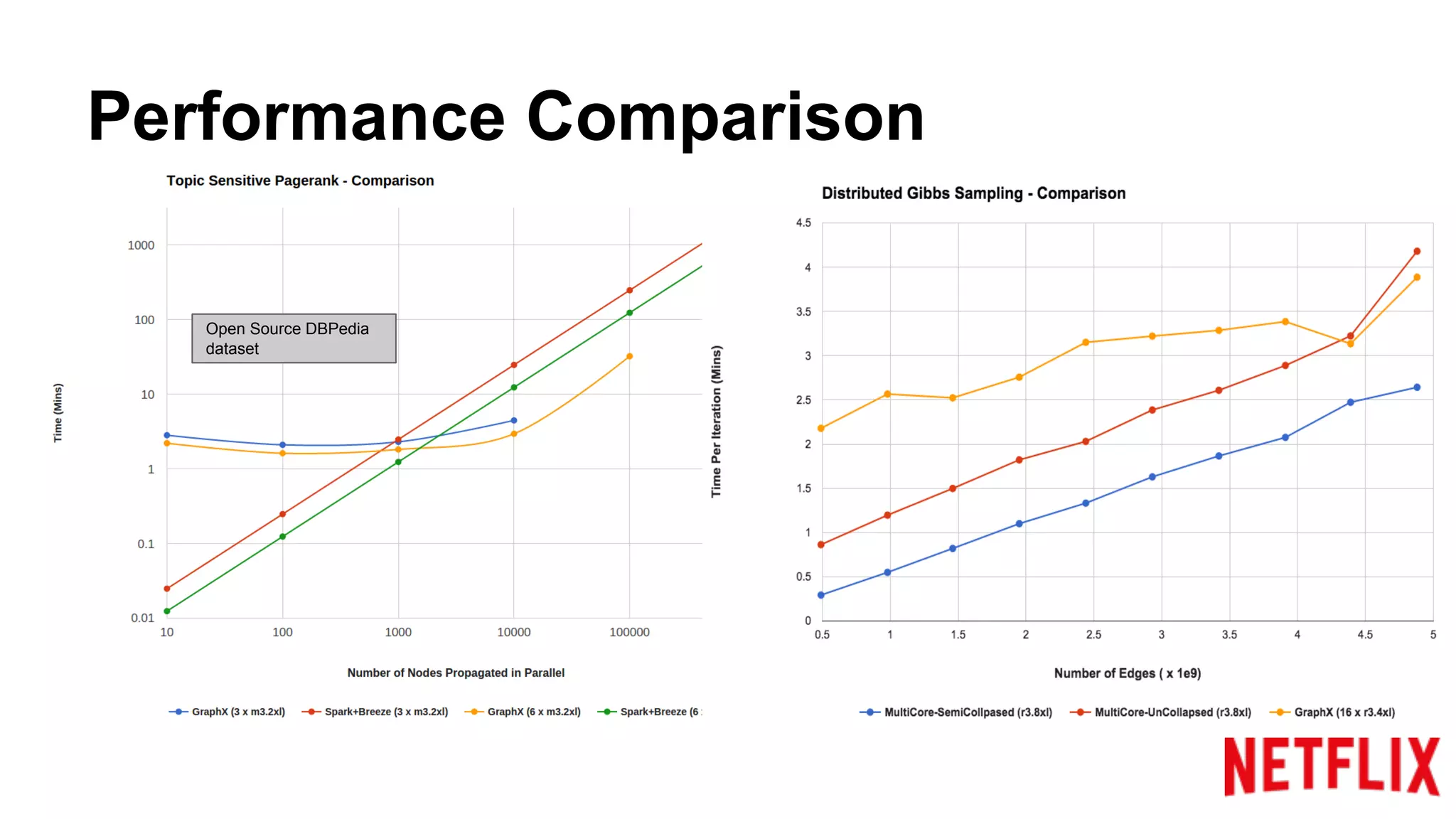
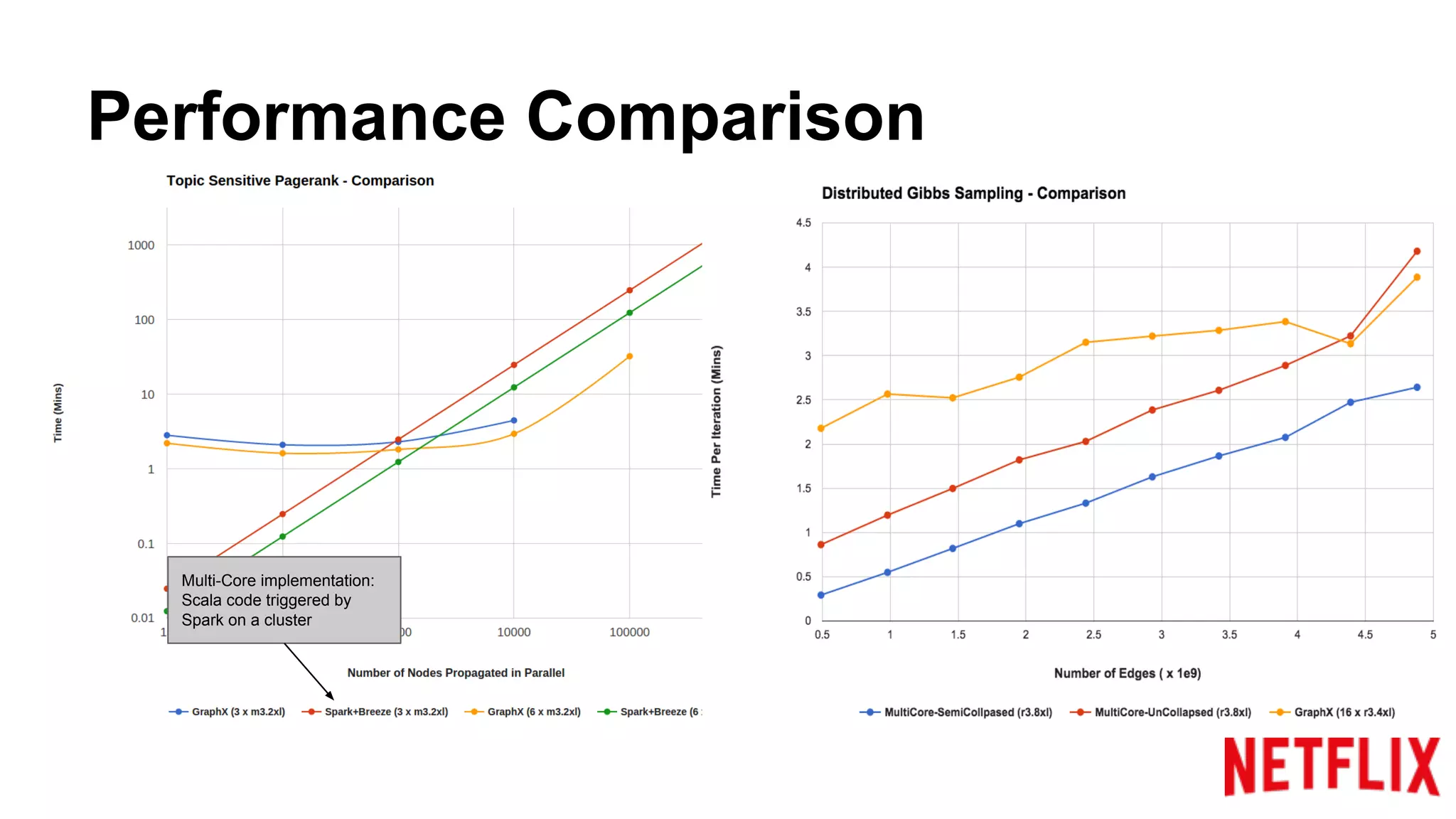
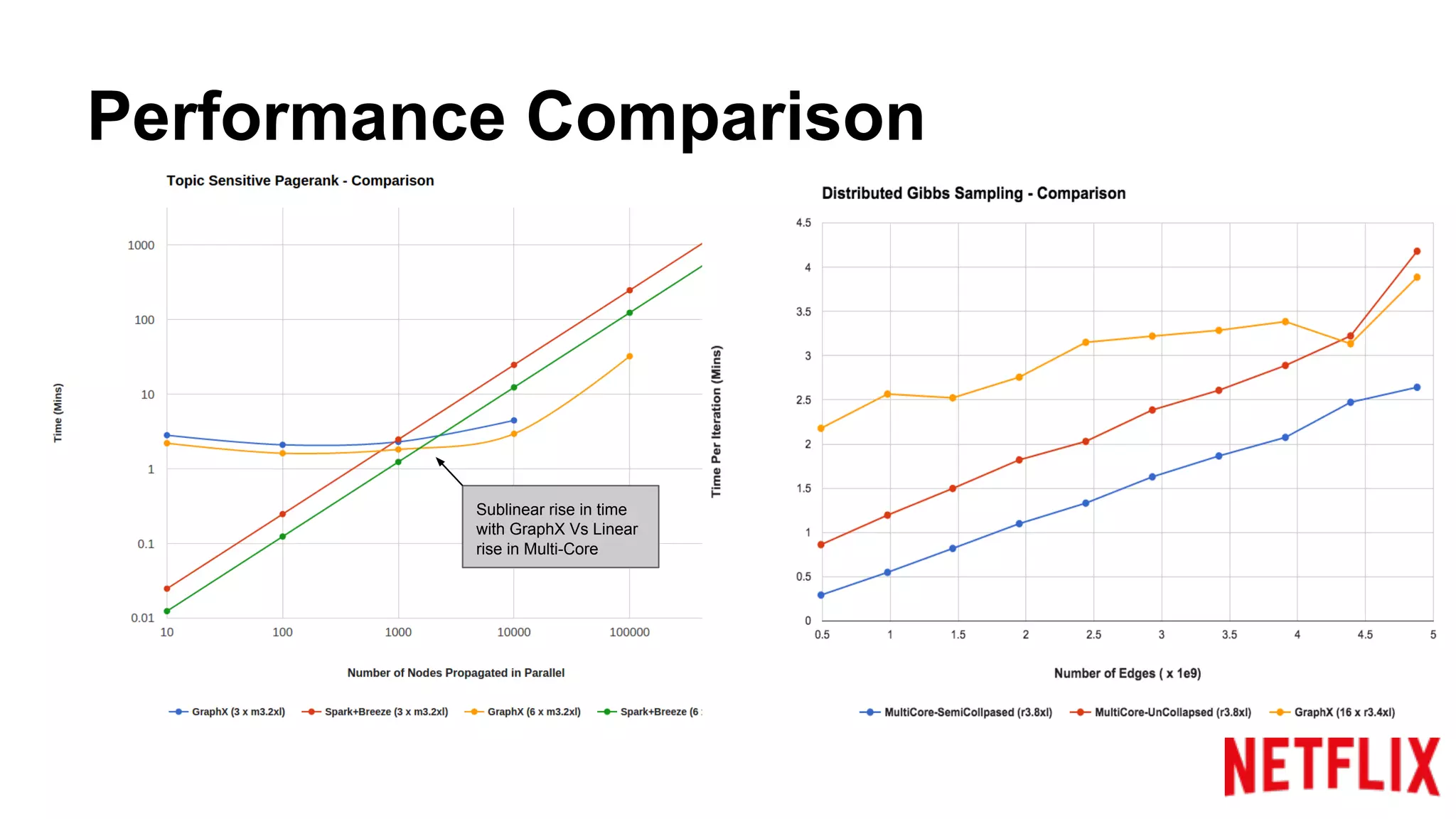
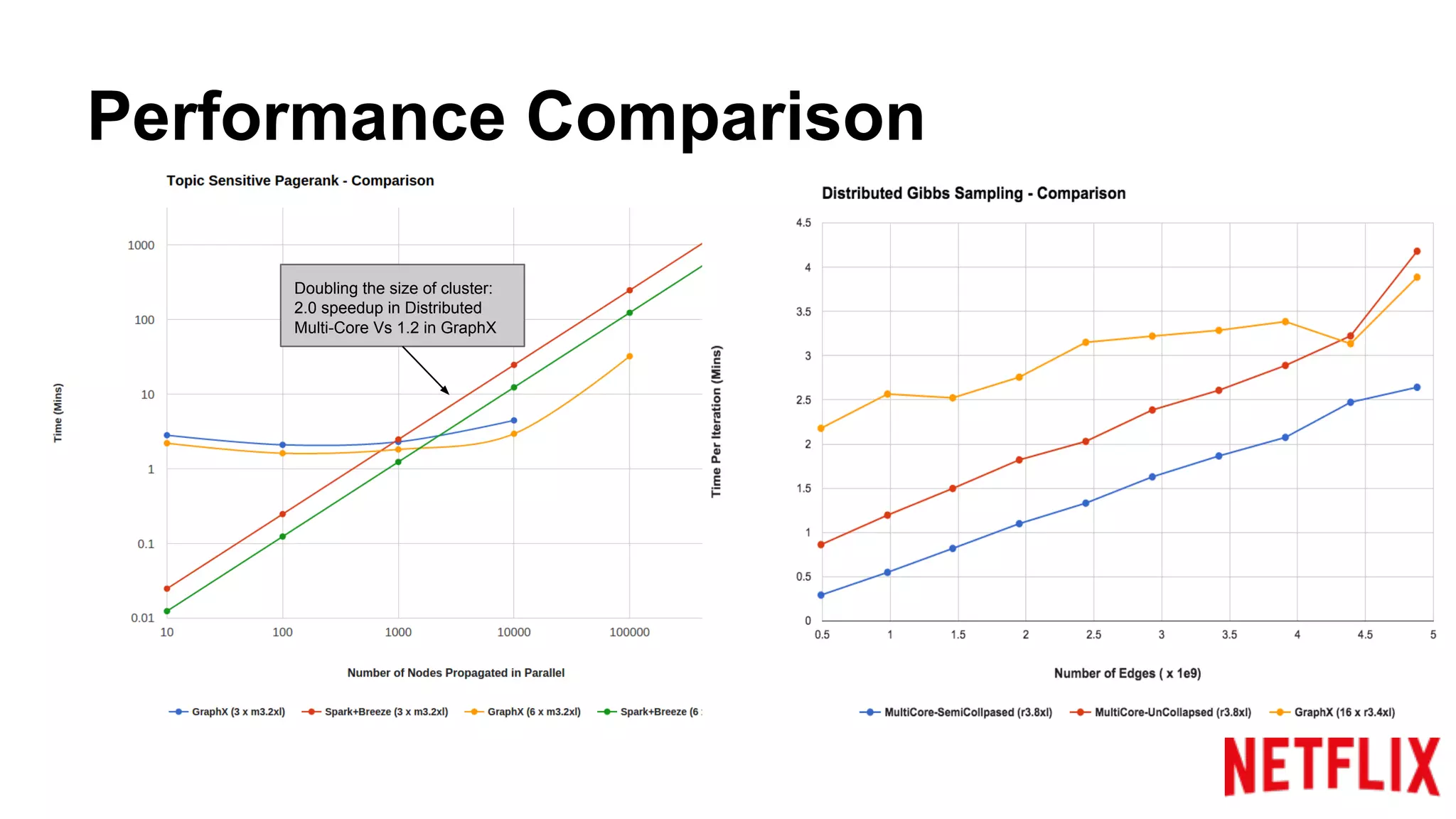
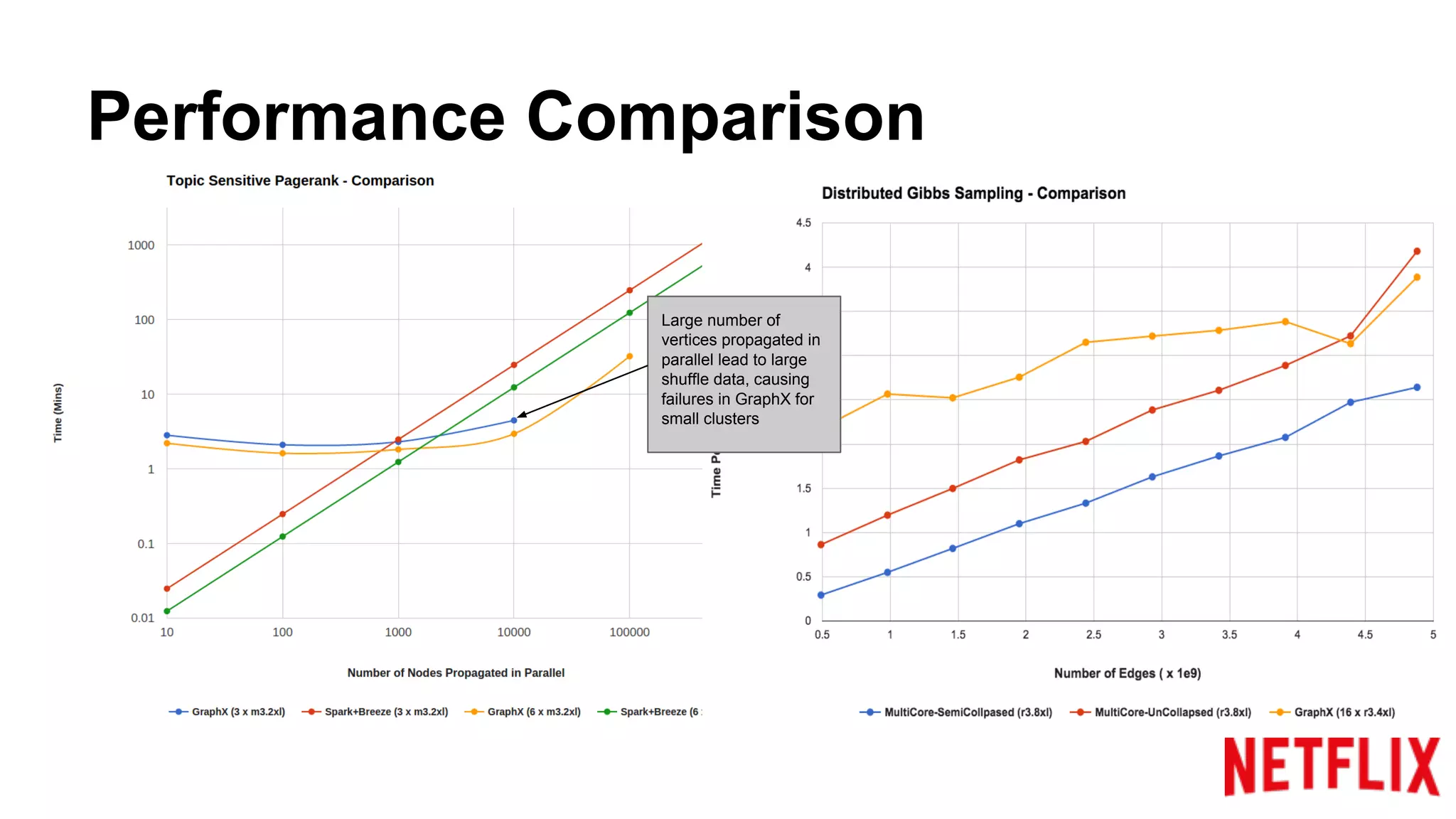
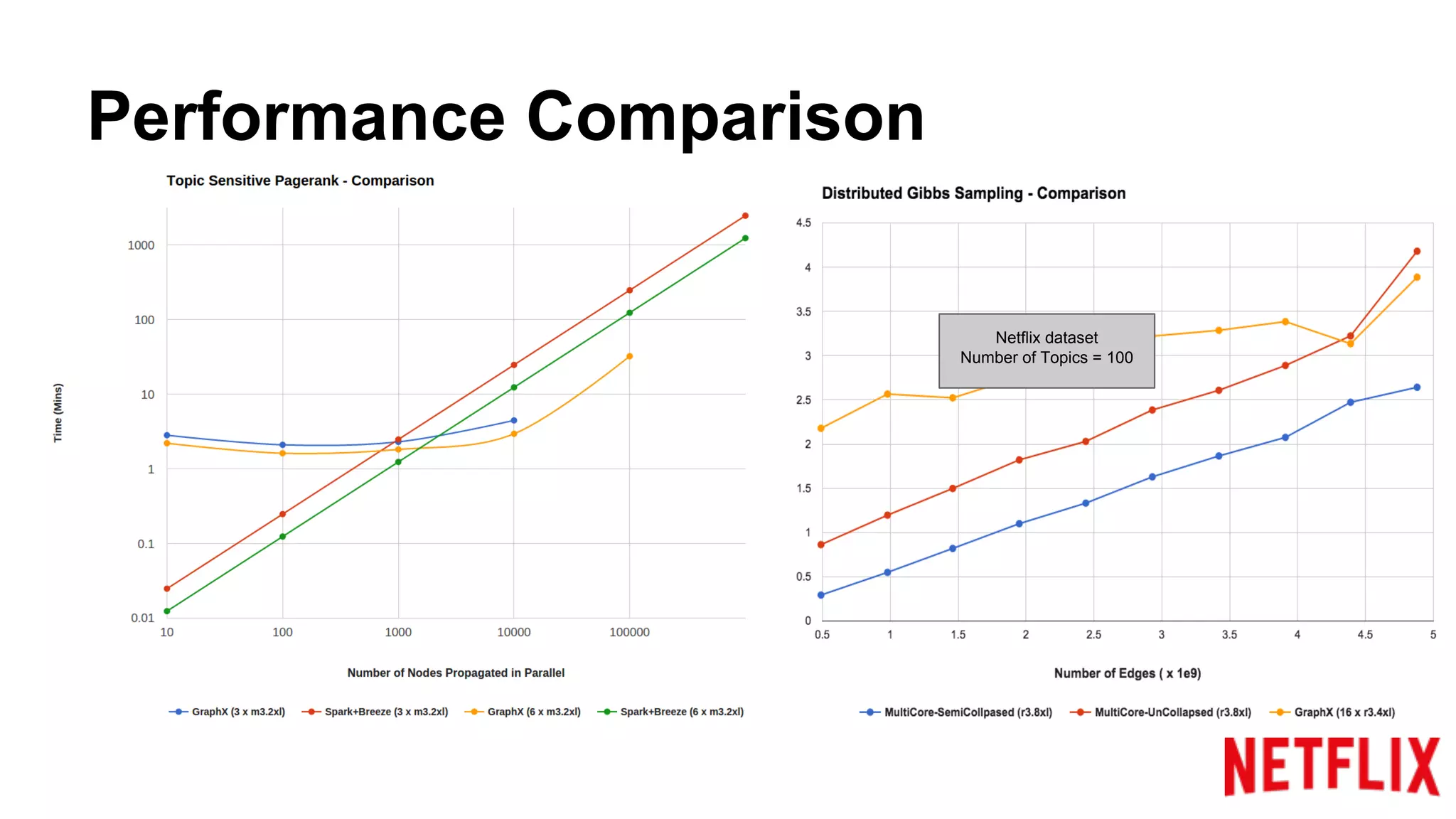
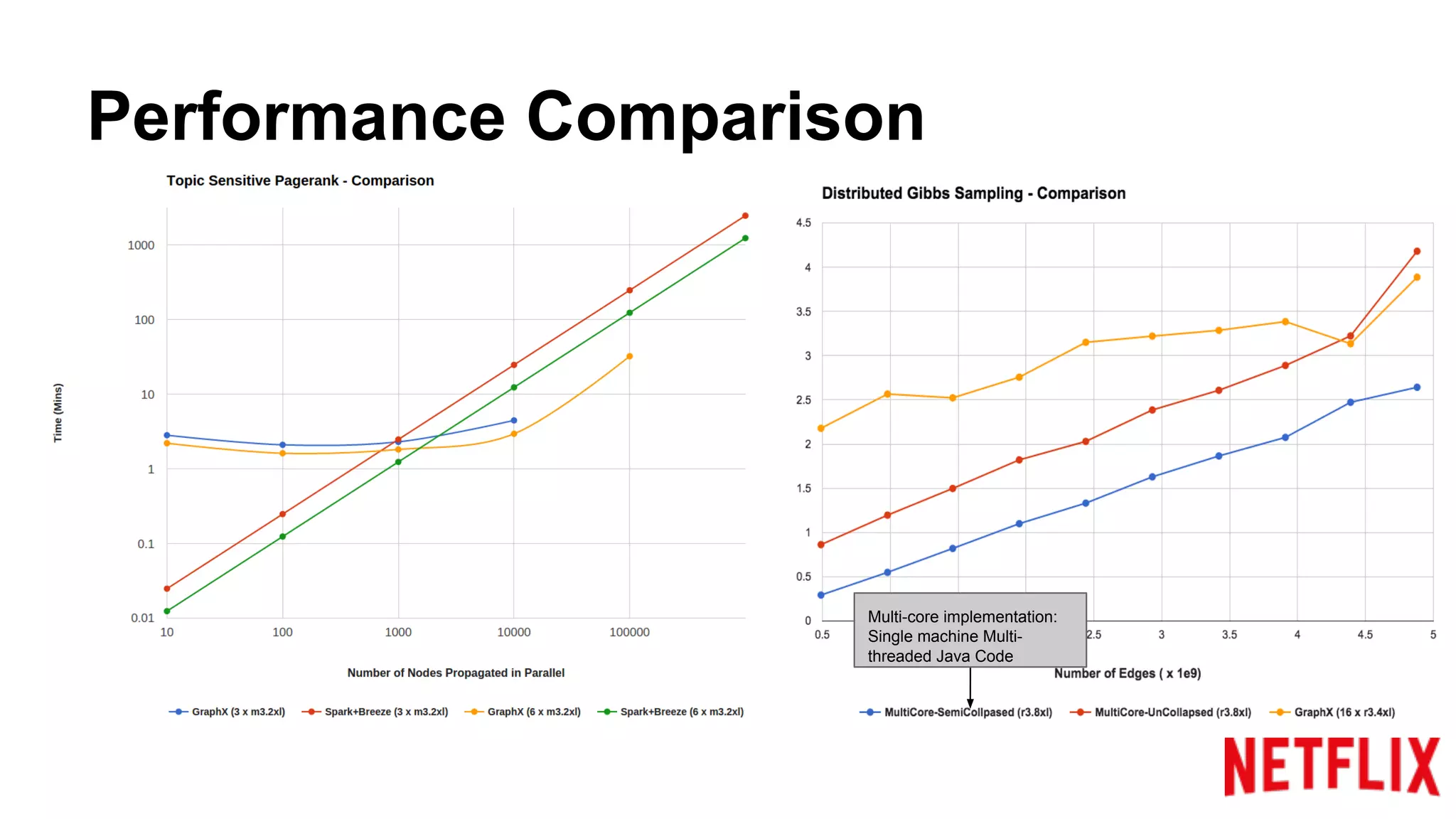
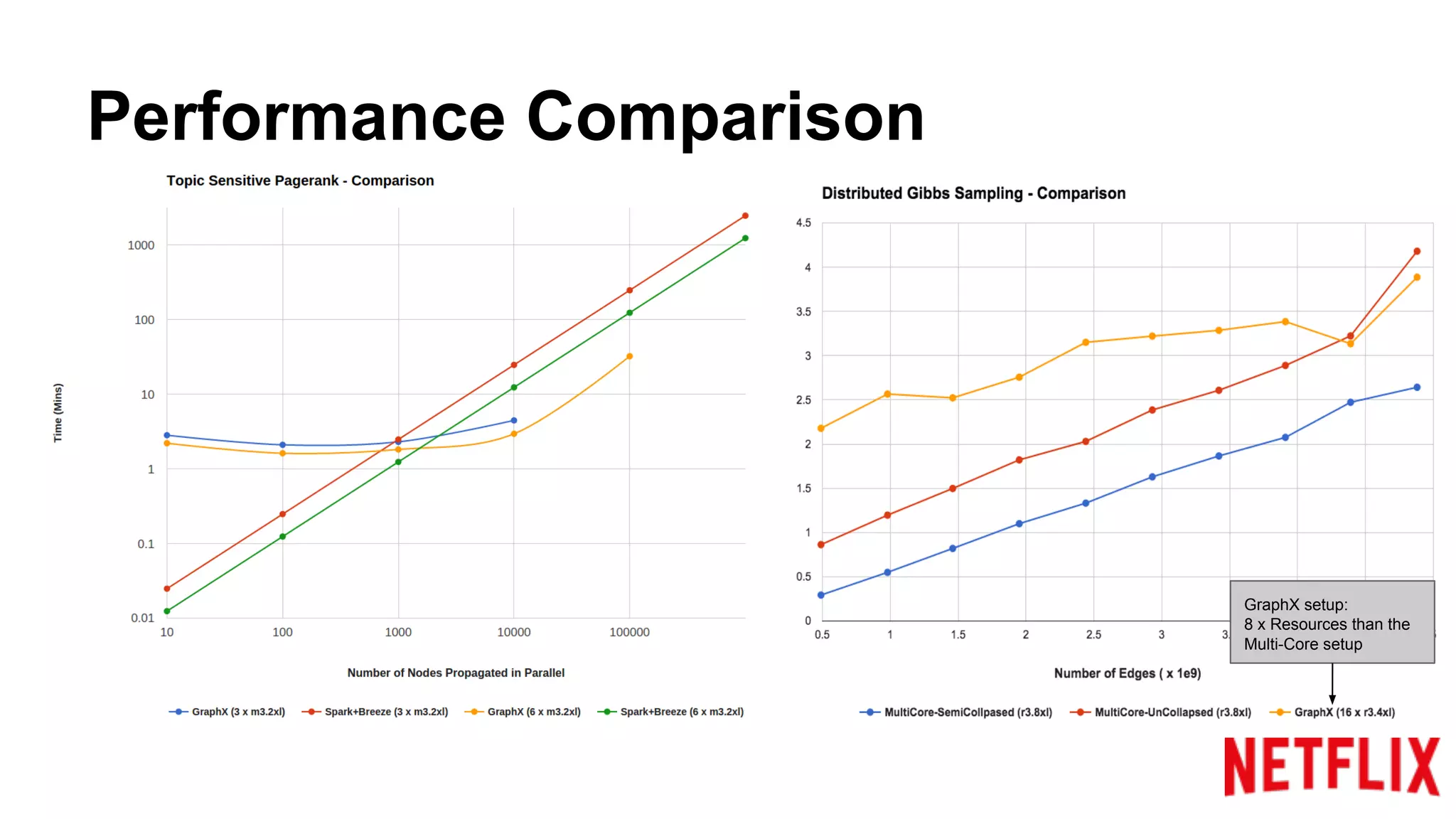
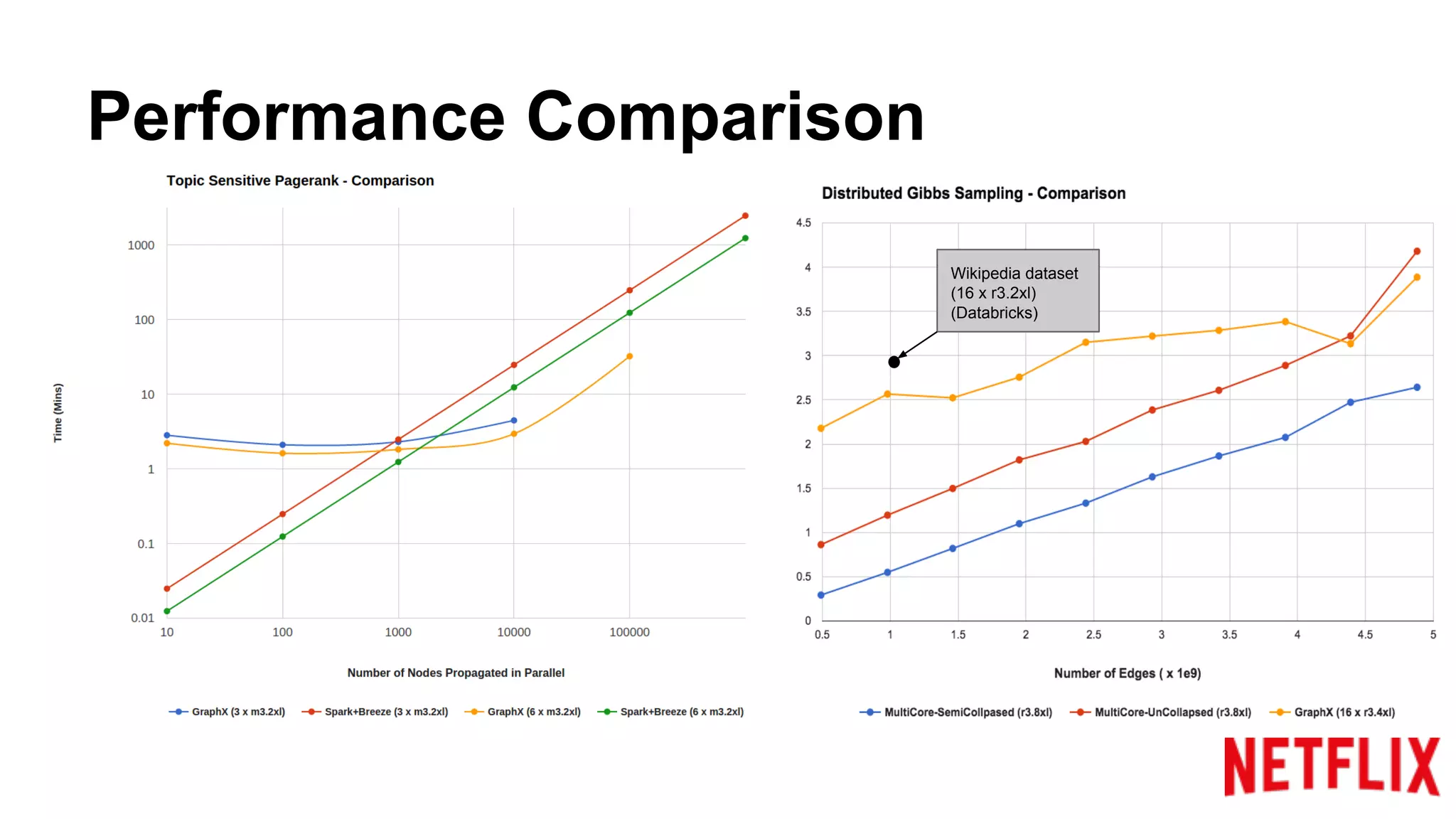
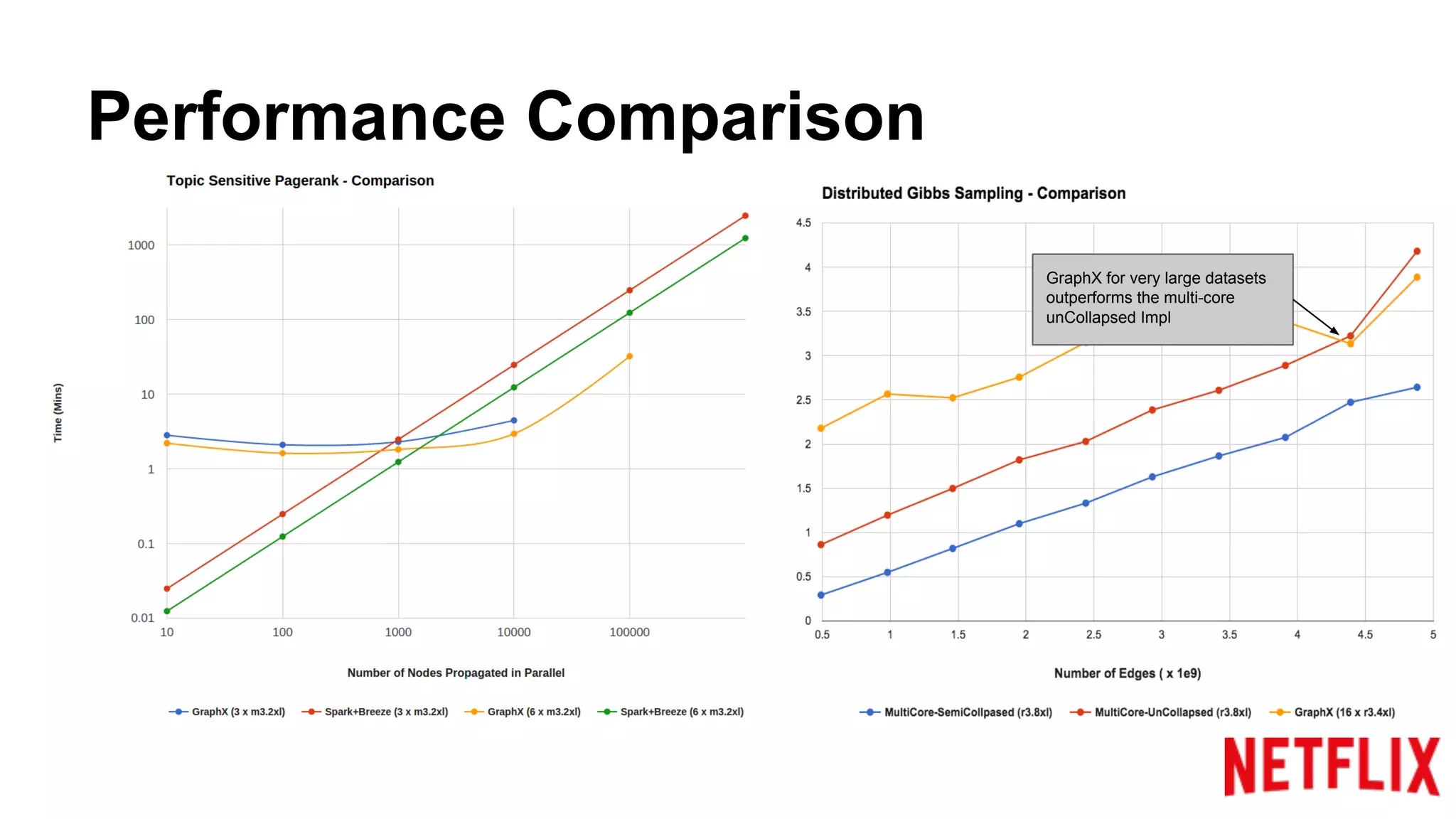
Compares the performance of algorithms in handling datasets, highlighting GraphX efficiencies against alternatives.Summarizes key insights around the performance benefits of GraphX and the importance of iterative algorithm design.
Opens the opportunity for employment at Netflix and provides coding and data handling examples in GraphX.
Technical instructions and references related to the implementation of Pagerank and distributed Gibbs Sampler in GraphX.











































































































