Download as PDF, PPTX






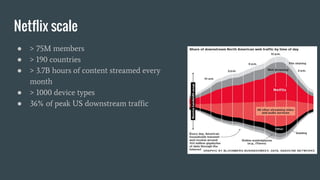




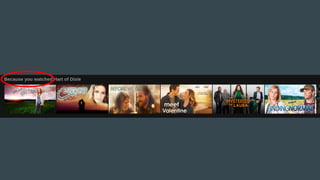





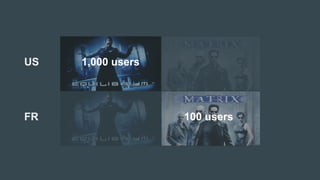
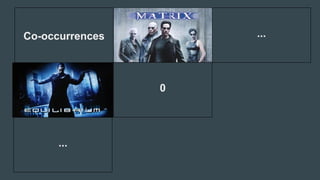


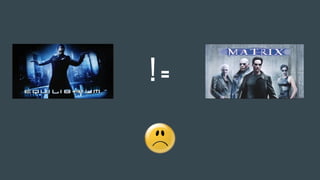


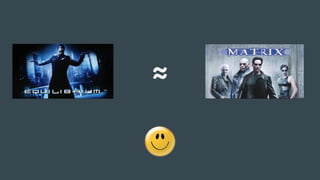








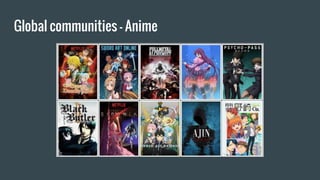




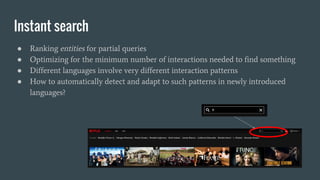
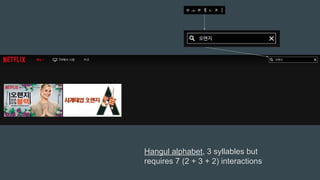







The document discusses the challenges Netflix faces in creating effective global recommendation algorithms for its vast user base. Key issues include uneven video availability, cultural differences in recommendations, language interaction patterns, and tracking algorithm effectiveness across diverse user groups. Solutions involve developing regional models, pooling global data, and adapting algorithms to cater to local tastes while maintaining a universal appeal.












































































