




















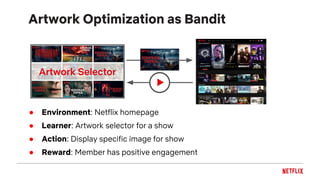
















![Bayesian UCB Example
1 0 1 1 ?
0 0 ?
0 1 0 ?
[0.15, 0.85]
[0.07, 0.81]
Reward 95%
Confidence
[0.01, 0.71]](https://image.slidesharecdn.com/2018-11-qconartworkpersonalizationtalk-181105201733/85/Artwork-Personalization-at-Netflix-41-320.jpg)
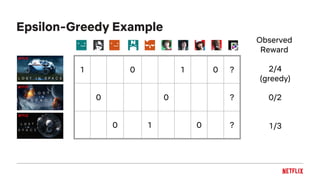
![Bayesian UCB Example
1 0 1 1 ?
0 0 ?
0 1 0 ?
[0.15, 0.85]
[0.07, 0.81]
Reward 95%
Confidence
[0.01, 0.71]](https://image.slidesharecdn.com/2018-11-qconartworkpersonalizationtalk-181105201733/85/Artwork-Personalization-at-Netflix-42-320.jpg)
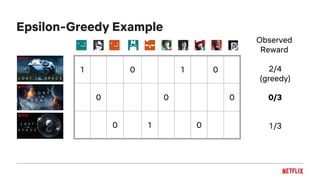
![Bayesian UCB Example
1 0 1 1 0
0 0
0 1 0
[0.12, 0.78]
[0.07, 0.81]
Reward 95%
Confidence
[0.01, 0.71]](https://image.slidesharecdn.com/2018-11-qconartworkpersonalizationtalk-181105201733/85/Artwork-Personalization-at-Netflix-43-320.jpg)
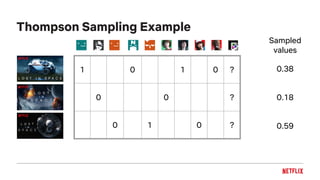
![Bayesian UCB Example
1 0 1 1 0
0 0
0 1 0
[0.12, 0.78]
[0.07, 0.81]
Reward 95%
Confidence
[0.01, 0.71]](https://image.slidesharecdn.com/2018-11-qconartworkpersonalizationtalk-181105201733/85/Artwork-Personalization-at-Netflix-44-320.jpg)















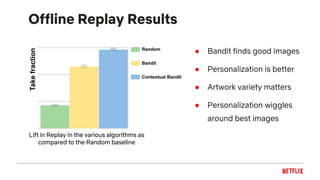





















This document summarizes an presentation about personalizing artwork selection on Netflix using multi-armed bandit algorithms. Bandit algorithms were applied to choose representative, informative and engaging artwork for each title to maximize member satisfaction and retention. Contextual bandits were used to personalize artwork selection based on member preferences and context. Netflix deployed a system that precomputes personalized artwork using bandit models and caches the results to serve images quickly at scale. The system was able to lift engagement metrics based on A/B tests of the personalized artwork selection models.









































































