Downloaded 23 times






![7
7
Parallel
Graph
Processing:
OpportuniEes
• Extend
Exis2ng
Paradigms
– Vertex
centric
– Edge
centric
• BUILD
NEW
FRAMEWORKS
for
Parallel
Graph
Processing
– Single
Machine
Solu2ons
• GraphLego
[ACM
HPDC
2015]
/
GraphTwist
[VLDB2015]
– Distributed
Approaches
• GraphMap
[IEEE
SC
2015],
PathGraph
[IEEE
SC
2014]
7](https://image.slidesharecdn.com/lingliu-part02biggraphprocessing-160616082655/85/Ling-liu-part-02-big-graph-processing-7-320.jpg)























![33
33
Summary
GraphMap
! Distributed
itera2ve
graph
computa2on
framework
that
effec2vely
u2lizes
secondary
storage
! Clear
separa2on
between
mutable
and
read-‐only
data
! Locality-‐based
data
placement
on
disk
! Dynamic
access
methods
based
on
the
workloads
of
the
current
itera2on
Ongoing
Research
! Disk
and
worker
coloca2on
to
improve
the
disk
access
performance
! Efficient
and
lightweight
par22oning
techniques,
incorpora2ng
our
work
on
GraphLego
for
single
PC
graph
processing
[ACM
HPDC
2015]
! Comparing
with
SPARK/GraphX
on
larger
DRAM
cluster](https://image.slidesharecdn.com/lingliu-part02biggraphprocessing-160616082655/85/Ling-liu-part-02-big-graph-processing-33-320.jpg)



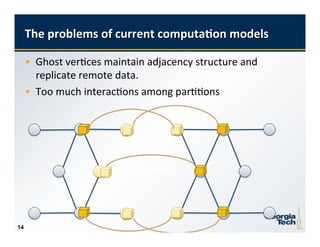
This document discusses challenges and opportunities in parallel graph processing for big data. It describes how graphs are ubiquitous but processing large graphs at scale is difficult due to their huge size, complex correlations between data entities, and skewed distributions. Current computation models have problems with ghost vertices, too much interaction between partitions, and lack of support for iterative graph algorithms. New frameworks are needed to handle these graphs in a scalable way with low memory usage and balanced computation and communication.























































































