Downloaded 42 times








![13
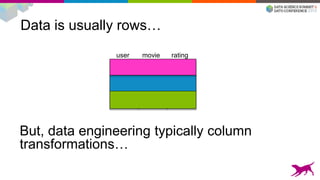
Feature engineering is columnar
Normalizes the feature x:
sf[‘rating’] = sf[‘rating’] / sf[‘rating’].sum()
Create a new feature:
sf[‘rating-squared’] =
sf[‘rating’].apply(lambda rating: rating*rating)
Create a new dataset with 2 of the features:
sf2 = sf[[‘rating’,’ rating-squared’]]
ratinguser movie
rating
squared](https://image.slidesharecdn.com/ypc0gagrcdgx3dqe8hqd-signature-efa99a5bb65223d1c11faeca715418b07c92615eeb3c248a5f1fc28769e36690-poli-150724045303-lva1-app6892/85/Making-Machine-Learning-Scale-Single-Machine-and-Distributed-11-320.jpg)




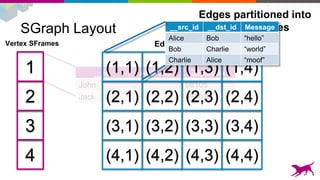
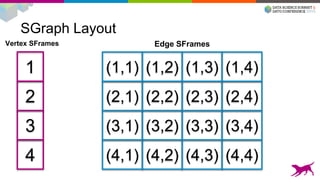
![SGraph
1. Immutable disk-backed graph representation.
(Append only)
2. Vertex / Edge Attributes.
3. Optimized for bulk access, not fine-grained queries.
Get neighborhood of [5 Million Vertices]
Get neighborhood of 1 vertex](https://image.slidesharecdn.com/ypc0gagrcdgx3dqe8hqd-signature-efa99a5bb65223d1c11faeca715418b07c92615eeb3c248a5f1fc28769e36690-poli-150724045303-lva1-app6892/85/Making-Machine-Learning-Scale-Single-Machine-and-Distributed-17-320.jpg)








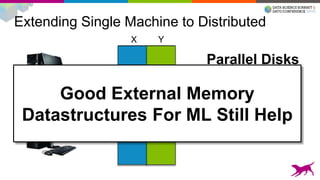
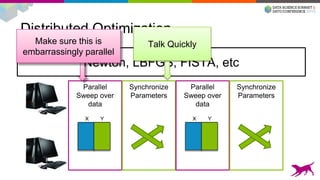
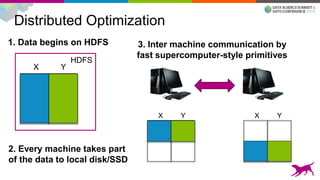




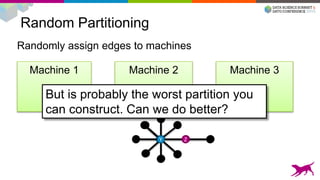






![Our Tools Are Easy To Use
import graphlab as gl
train_data = gl.SFrame.read_csv(traindata_path)
train_data['1grams'] = gl.text_analytics.count_ngrams(train_data[‘text’],1)
train_data['2grams'] = gl.text_analytics.count_ngrams(train_data[‘text’],2)
cls = gl.classifier.create(train_data, target='sentiment’)
5 line sentiment analysis
But
You have preexisting code in Numpy, Scipy, Scikit-learn](https://image.slidesharecdn.com/ypc0gagrcdgx3dqe8hqd-signature-efa99a5bb65223d1c11faeca715418b07c92615eeb3c248a5f1fc28769e36690-poli-150724045303-lva1-app6892/85/Making-Machine-Learning-Scale-Single-Machine-and-Distributed-48-320.jpg)

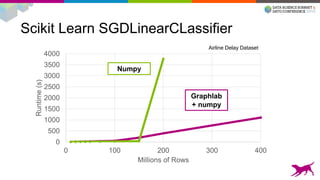

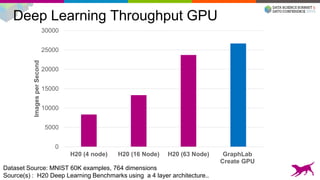

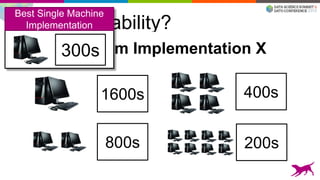
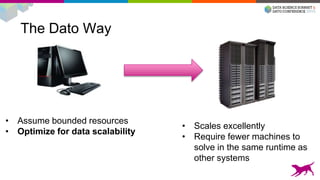
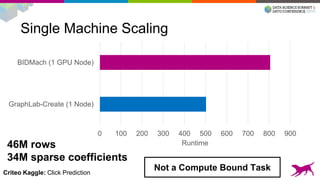
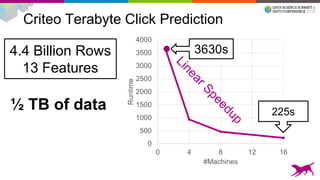
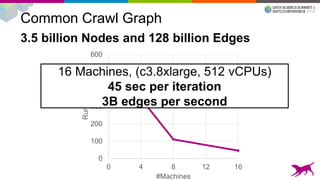
This document summarizes machine learning scalability from single machine to distributed systems. It discusses how true scalability is about how long it takes to reach a target accuracy level using any available hardware resources. It introduces GraphLab Create and SFrame/SGraph for scalable machine learning and graph processing. Key points include distributed optimization techniques, graph partitioning strategies, and benchmarks showing GraphLab Create can solve problems faster than other systems by using fewer machines.























































































