







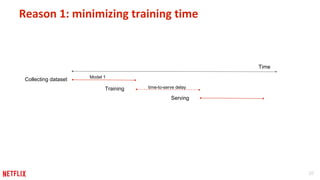





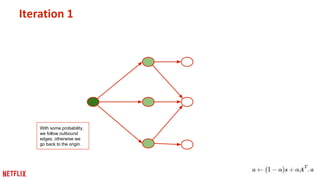
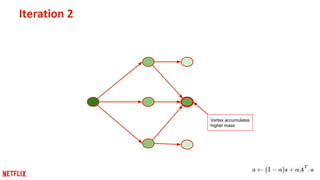
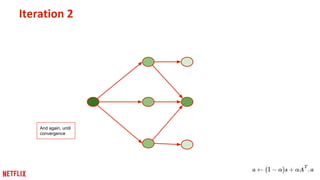
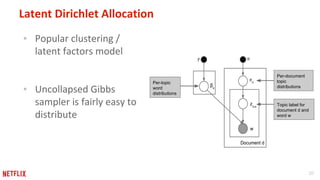
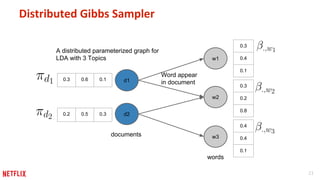
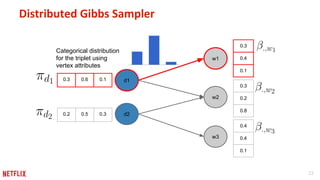
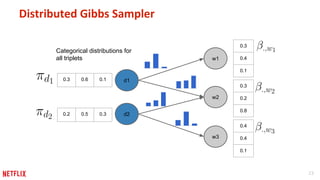
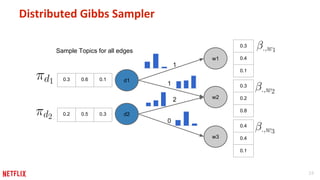
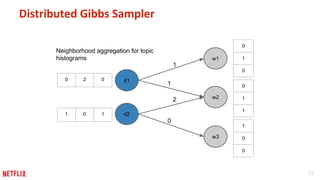
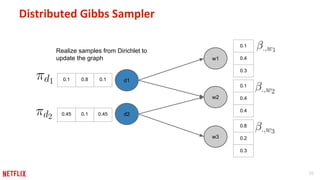






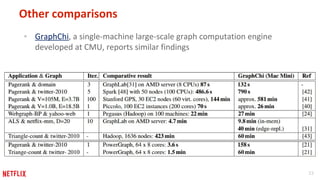





This document discusses some potential pitfalls of distributed learning. It notes that while distributing training across multiple machines can reduce training time and allow processing of larger datasets, there is also communication overhead between machines that can slow down training. It provides examples of distributing two algorithms, Topic-Sensitive PageRank and Latent Dirichlet Allocation, across Spark and finds that a single-machine implementation can often outperform a distributed one for smaller problems and datasets due to lower communication costs. It concludes that distribution is best suited to problems and datasets too large to fit or train on a single machine.


























































































