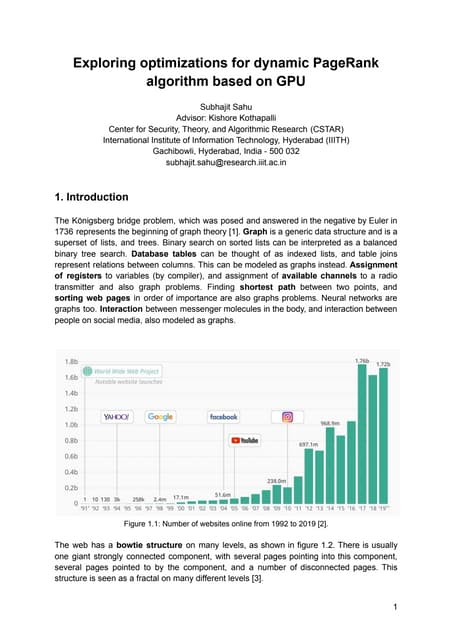
Downloaded 32 times


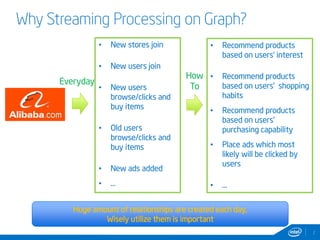


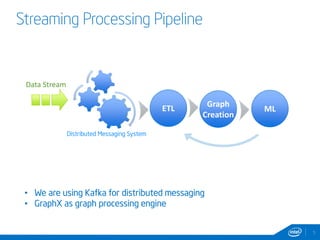
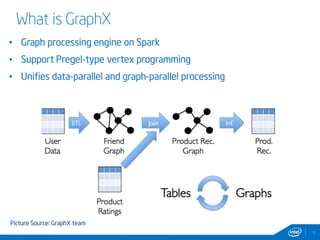

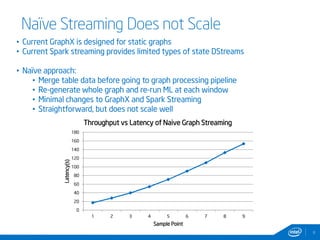


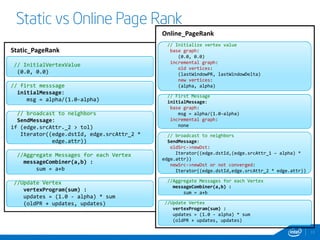
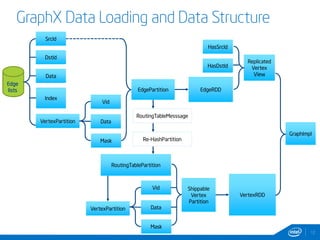
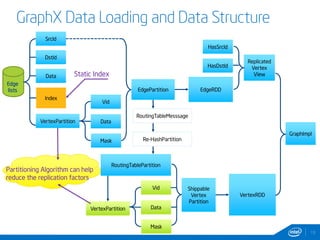
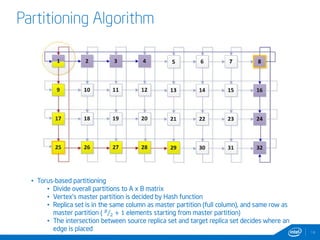
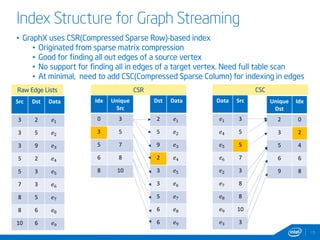

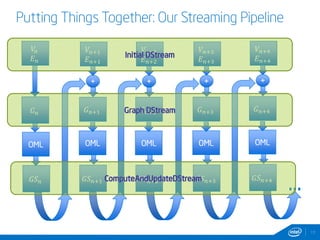
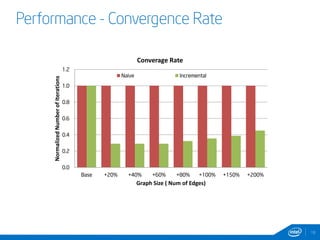
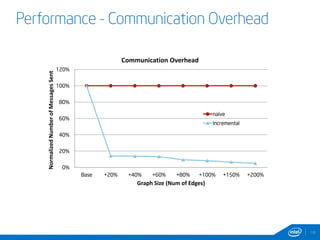



This document discusses streaming and online algorithms for graph processing using GraphX on Spark. It proposes moving from static algorithms that recompute the entire graph at each time interval to online algorithms that use incremental machine learning triggered by graph changes. The key aspects of the solution include efficient graph storage for evolving graphs, partitioning algorithms to reduce replication, and on-the-fly indexing methods instead of prebuilding indexes. Performance results show the online algorithms have better convergence rates and lower communication overhead compared to naive recomputation approaches as the graph sizes increase over time.