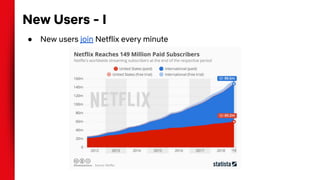
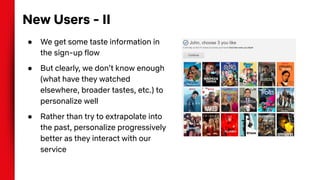
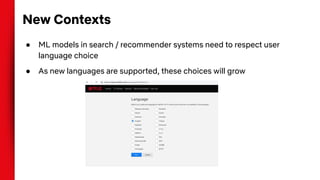
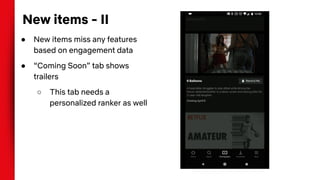
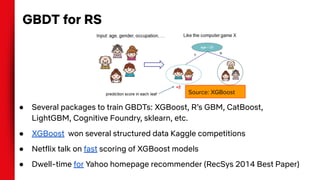
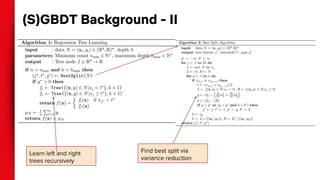
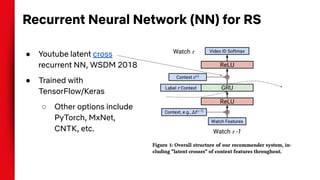
The document summarizes techniques for handling missing values in recommender models. It discusses how gradient boosted decision trees (GBDTs) and neural networks (NNs) can deal with missing features during training without imputing values. For GBDTs, XGBoost and R's GBM handle missing values differently, with XGBoost sending examples left or right and GBM using a ternary split. NNs can handle missing features via techniques like dropout, imputing averages, or including a "missing" embedding value. The document concludes that the optimal approach depends on the dataset.






![Improving correlational ML Models in RS
● Given context, predictive ML model in recommender system (RS) needs
to match users with items they might enjoy
● Thankfully, as ML engineers in the recommendation space, we need less
creativity and labor than Einstein / Eddington to improve models
● In supervised ML models, we can time-travel our (features, labels) to see
if our newer predictive models improve performance on historical offline
metrics [Netflix Delorean ML blog]
● Model improvements come from leveraging
○ business information (more appropriate metrics or inputs)
○ ML models: BERT, CatBoost, Factorization Machines, etc.](https://image.slidesharecdn.com/handlingmissingvaluesinmodels1-210416033652/85/Missing-values-in-recommender-models-7-320.jpg)
![Problem of Missing Data in RS - I
● ML models in RS need to deal with missing data patterns for cases such as:
○ New users
○ New contexts (e.g., country, time-zone, language, device, row-type)
○ New items
○ Timeouts and failures in data microservices
○ Modeling causal impact of recommendations
○ Intent-to-treat
● Unfortunately, last two problems similar to Einstein/Eddington example:
Solutions involve causal models / contextual bandits and discussed elsewhere [Netflix talk]
● Not handling missing labels: Optimizing RS for longer-term reward (label) a harder problem
[Netflix talk]](https://image.slidesharecdn.com/handlingmissingvaluesinmodels1-210416033652/85/Missing-values-in-recommender-models-8-320.jpg)