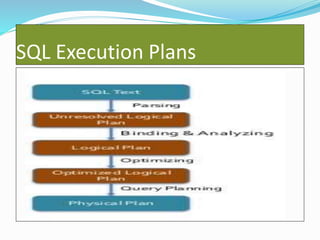
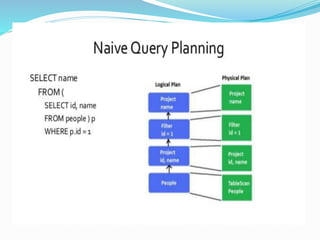
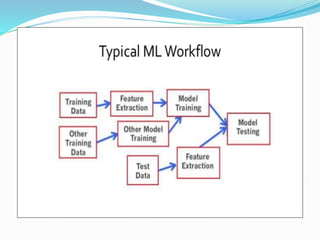
Spark is a framework for large-scale data processing. It includes Spark Core which provides functionality like memory management and fault recovery. Spark also includes higher level libraries like SparkSQL for SQL queries, MLlib for machine learning, GraphX for graph processing, and Spark Streaming for real-time data streams. The core abstraction in Spark is the Resilient Distributed Dataset (RDD) which allows parallel operations on distributed data.