Download as PDF, PPTX













![Related Concepts
Fairness: - typically refers to persons or groups within a population
- several fairness criteria besides calibration exist:
- equal(ized) odds, equal opportunity, statistical parity
Diversity: - minimal similarity or redundancy among items [majority of literature]
- proportionality in search results [Dang, Croft 2012]
- new metric to capture three properties [Vargas et al. 2014]
- focus on submodularity [Teo et al. 2016]](https://image.slidesharecdn.com/papers3-haraldsteck-calibratedrecommendations-181004220136/85/Calibrated-Recommendations-16-320.jpg)

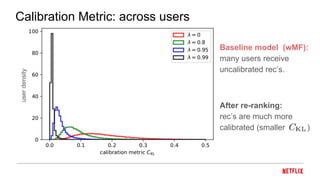
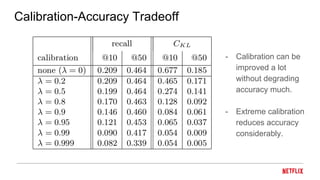
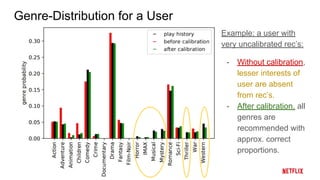
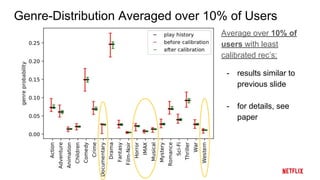




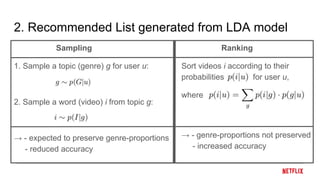
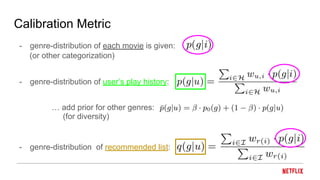
This document proposes a calibrated recommendations approach that aims to provide recommendations that reflect all of a user's interests in correct proportions. Standard recommender systems trained for accuracy can lead to unbalanced recommendations that amplify a user's main interests and crowd out lesser interests. The calibrated recommendations approach uses a post-processing re-ranking step to optimize a submodular calibration metric, balancing accuracy and fairness by recommending items from all a user's interests in their correct proportions. Experiments on MovieLens data show that calibration can be improved significantly without degrading accuracy much.








































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)












