Download as PDF, PPTX










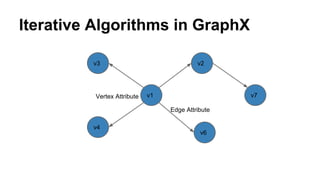
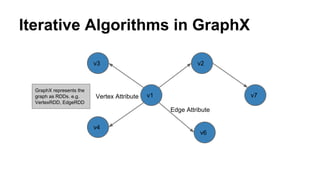
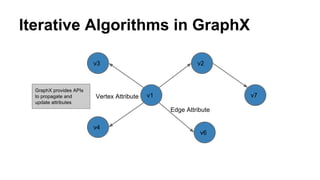
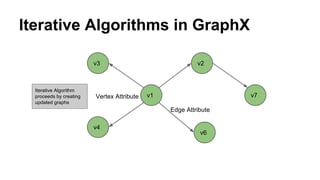


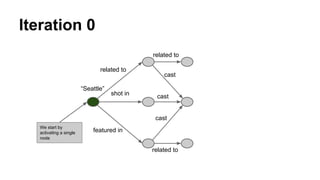
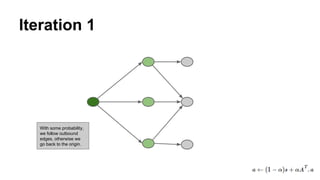
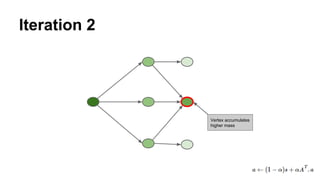
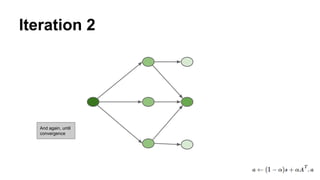

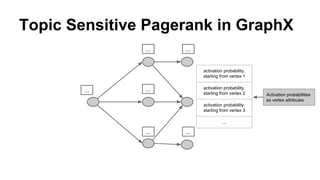



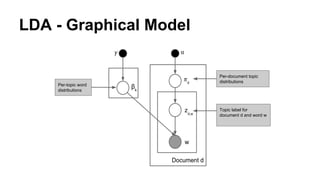

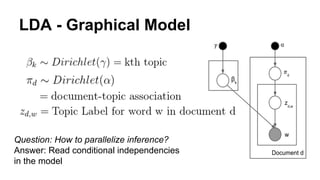





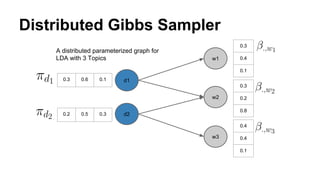
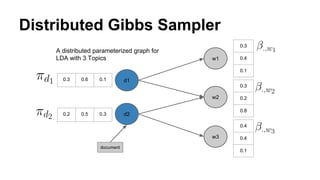
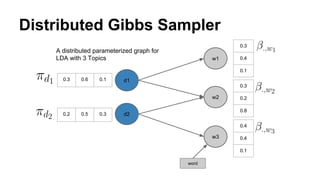
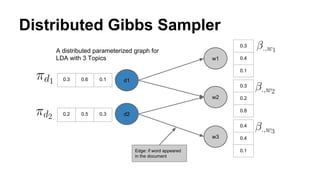
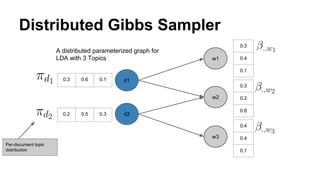
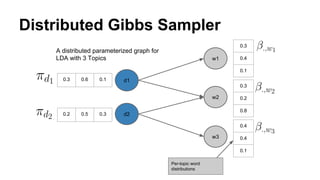
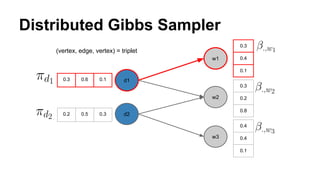
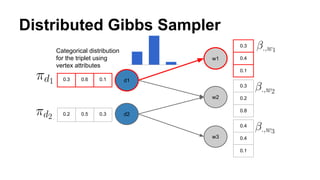
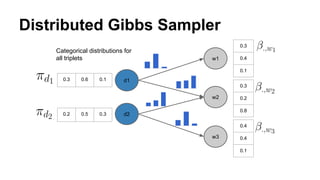
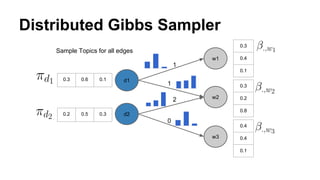
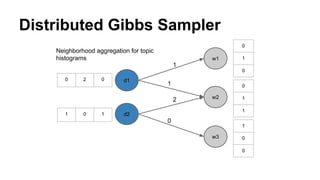
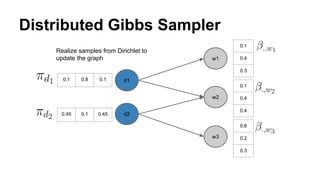



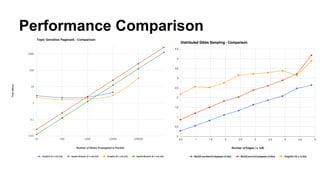
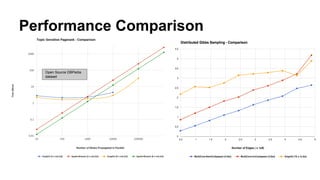
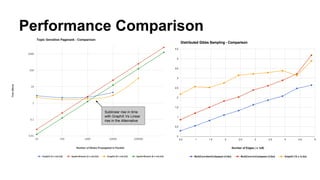
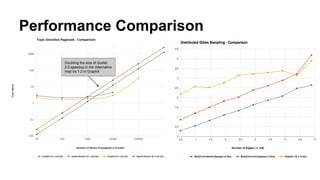
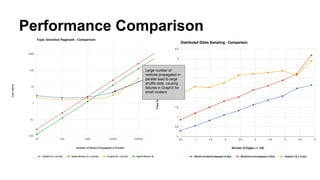
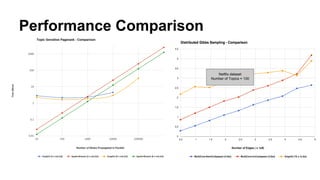
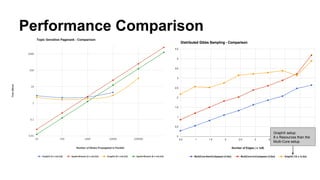
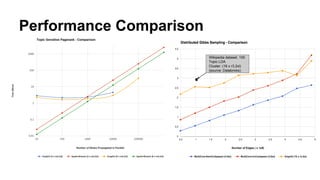
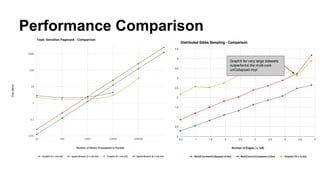






The document discusses the use of Spark and GraphX in Netflix's recommendation system to enhance content discovery for over 62 million members globally. It covers machine learning algorithms such as graph diffusion and clustering techniques, specifically topic-sensitive PageRank and Latent Dirichlet Allocation (LDA), and their implementation challenges and performance comparisons. Key insights include the benefits of using GraphX for iterative machine learning problems and efficient data processing at scale.




















































































