
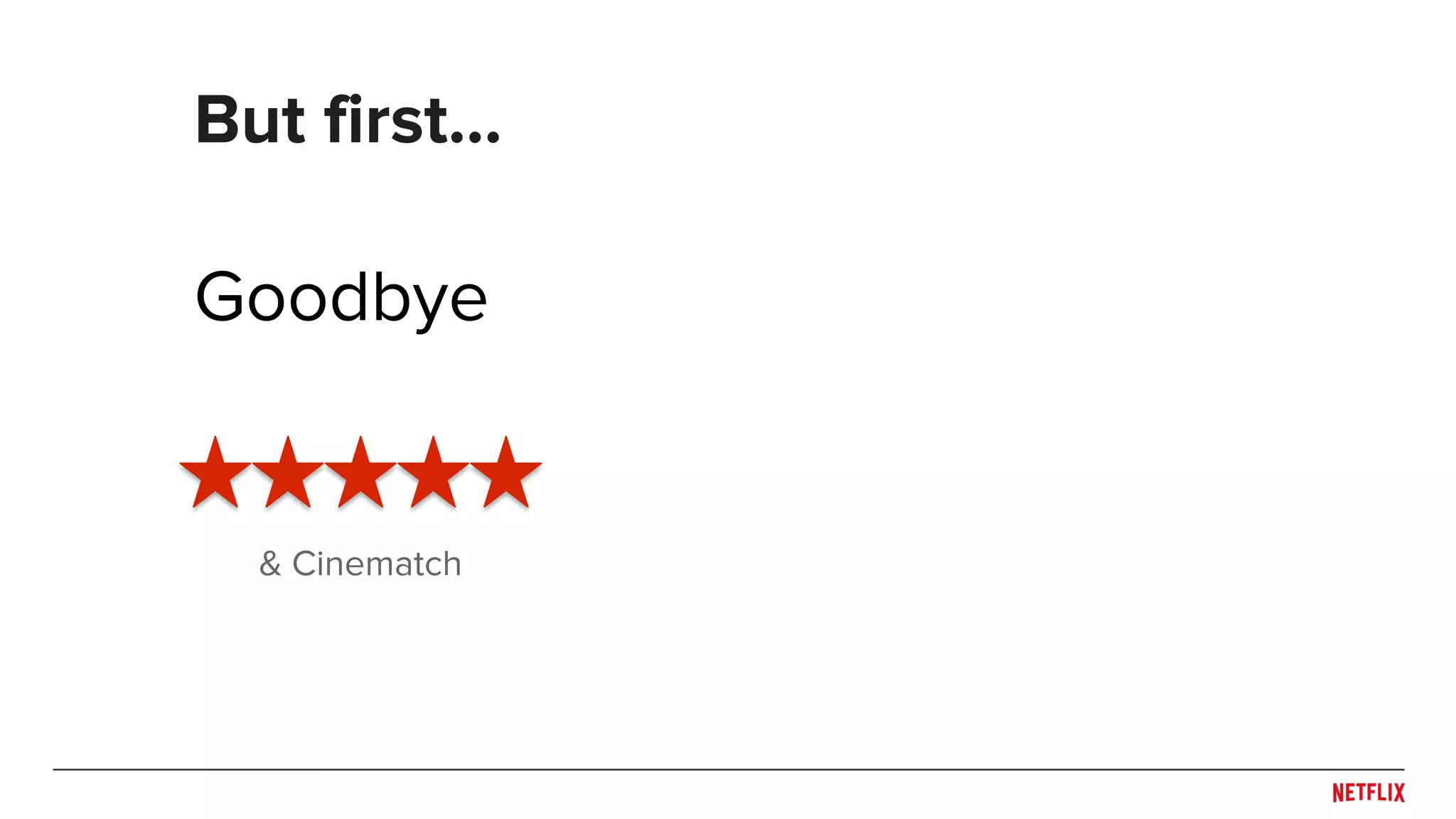



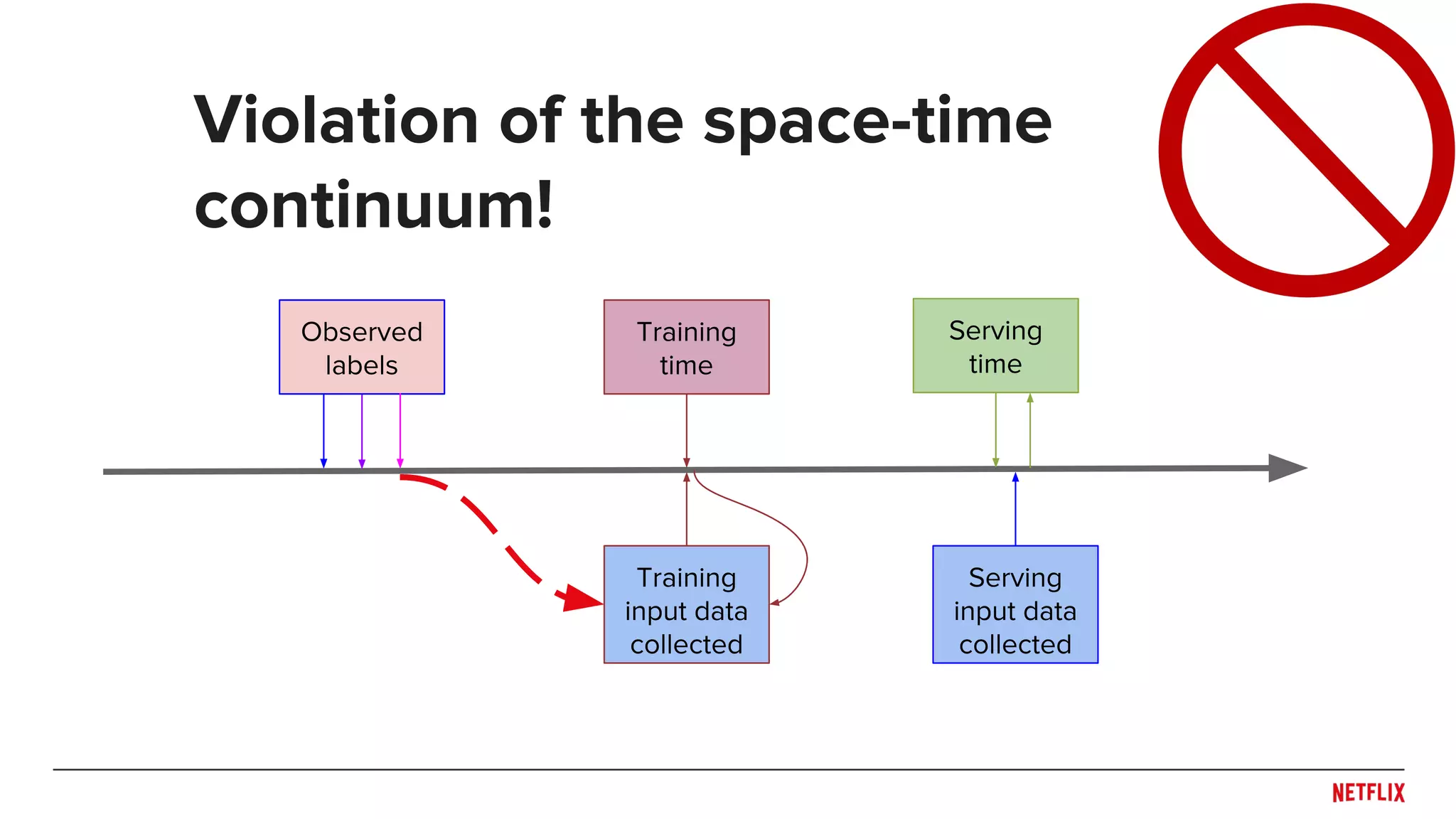
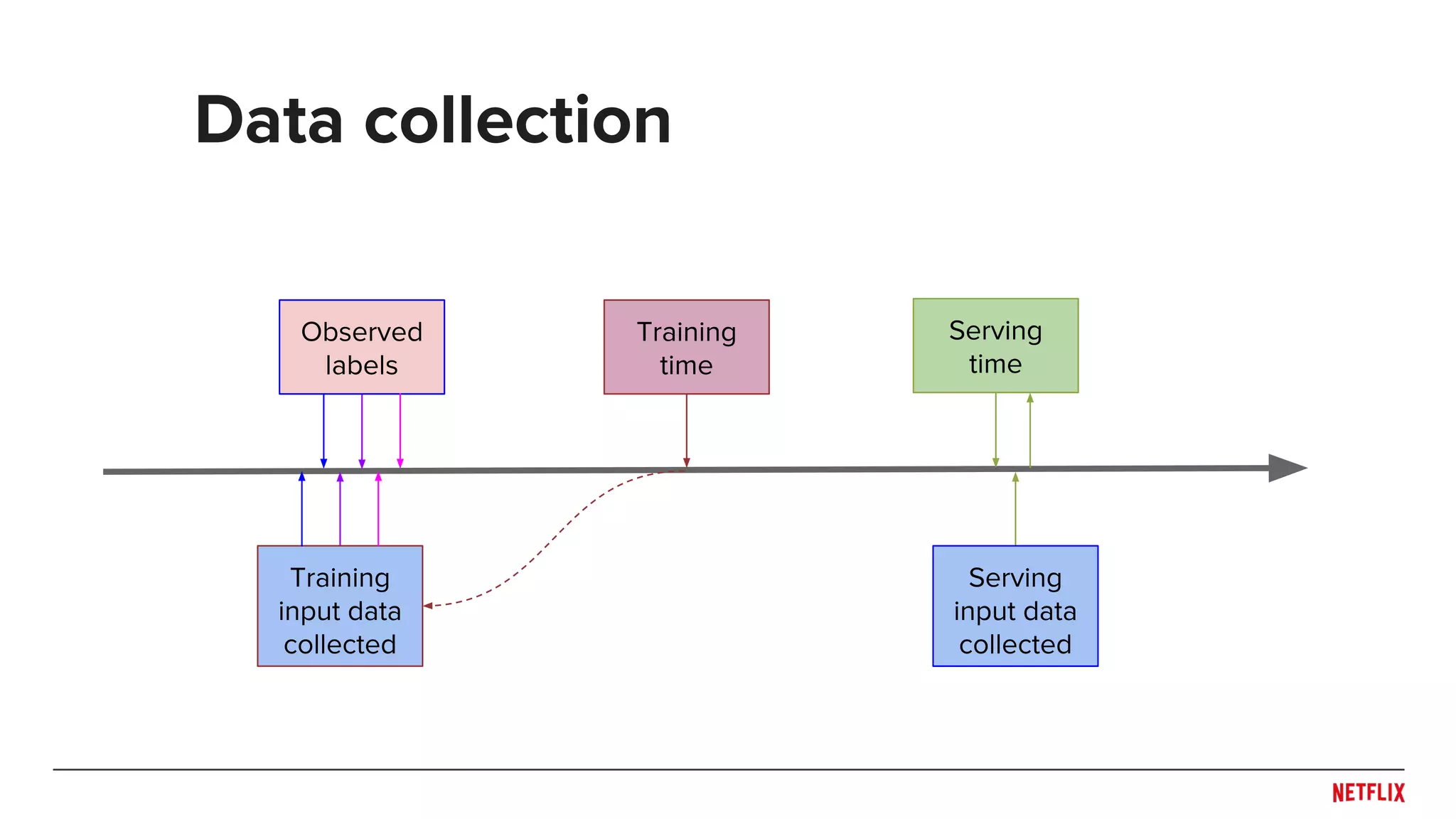
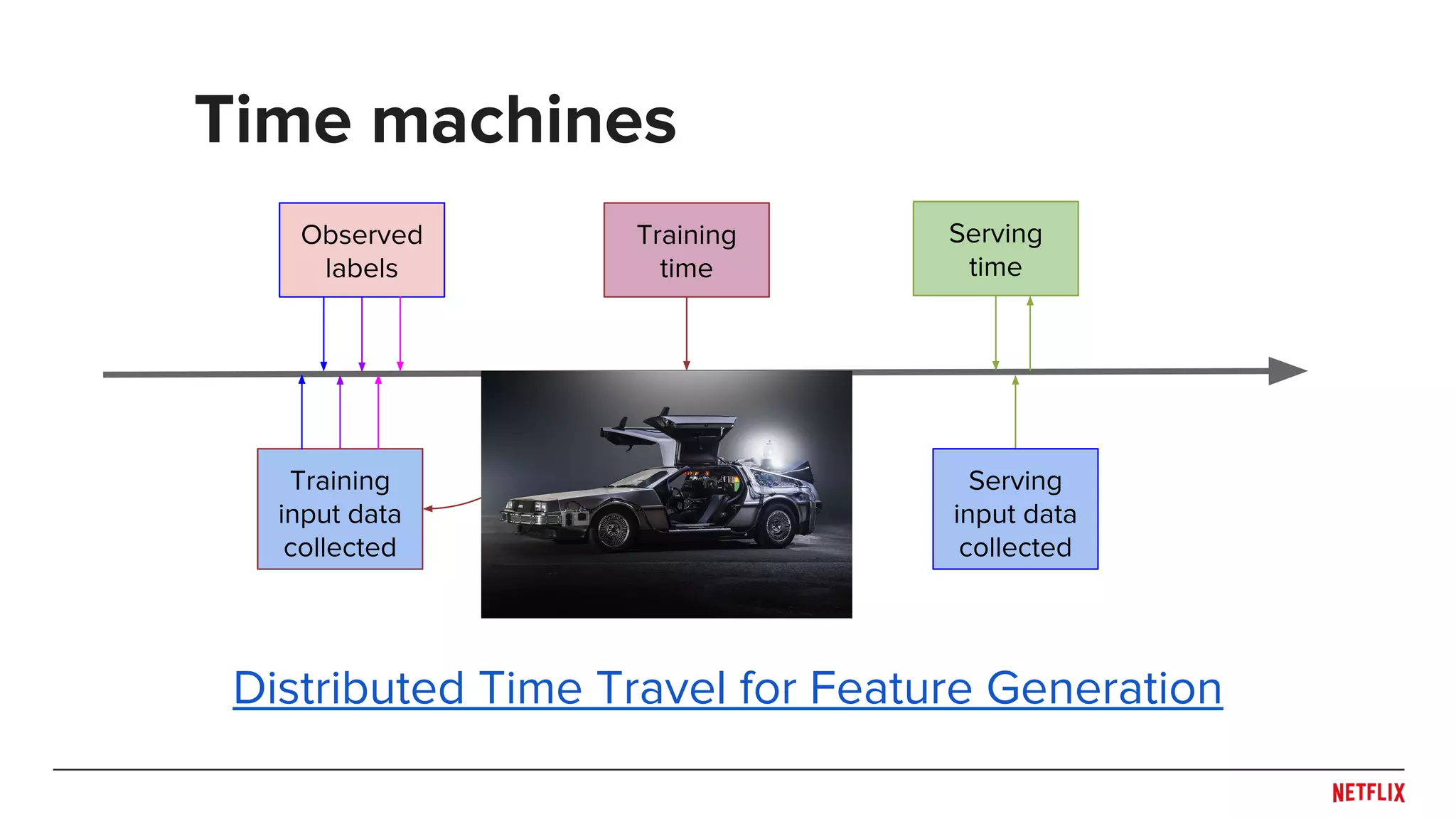
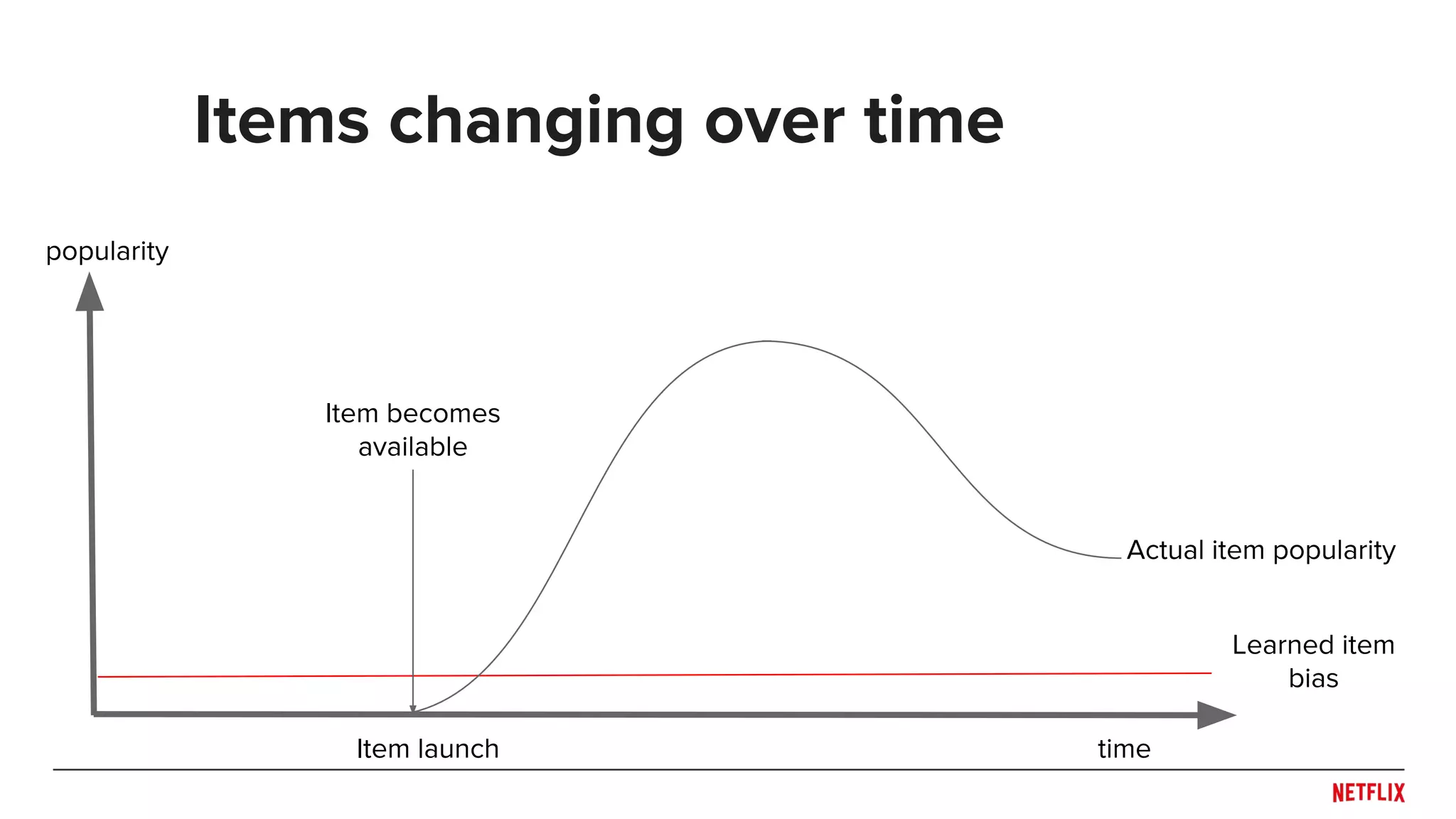
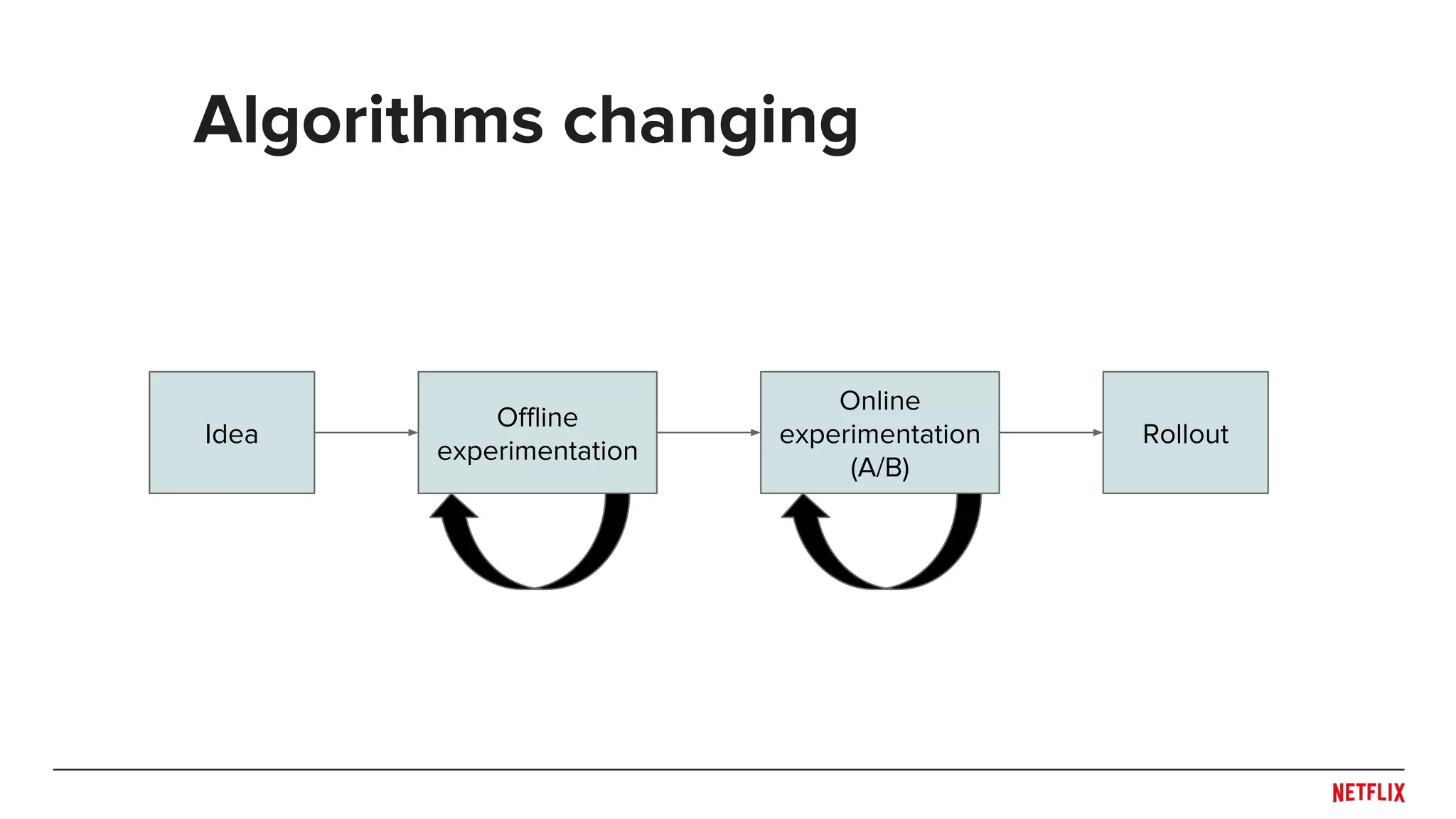
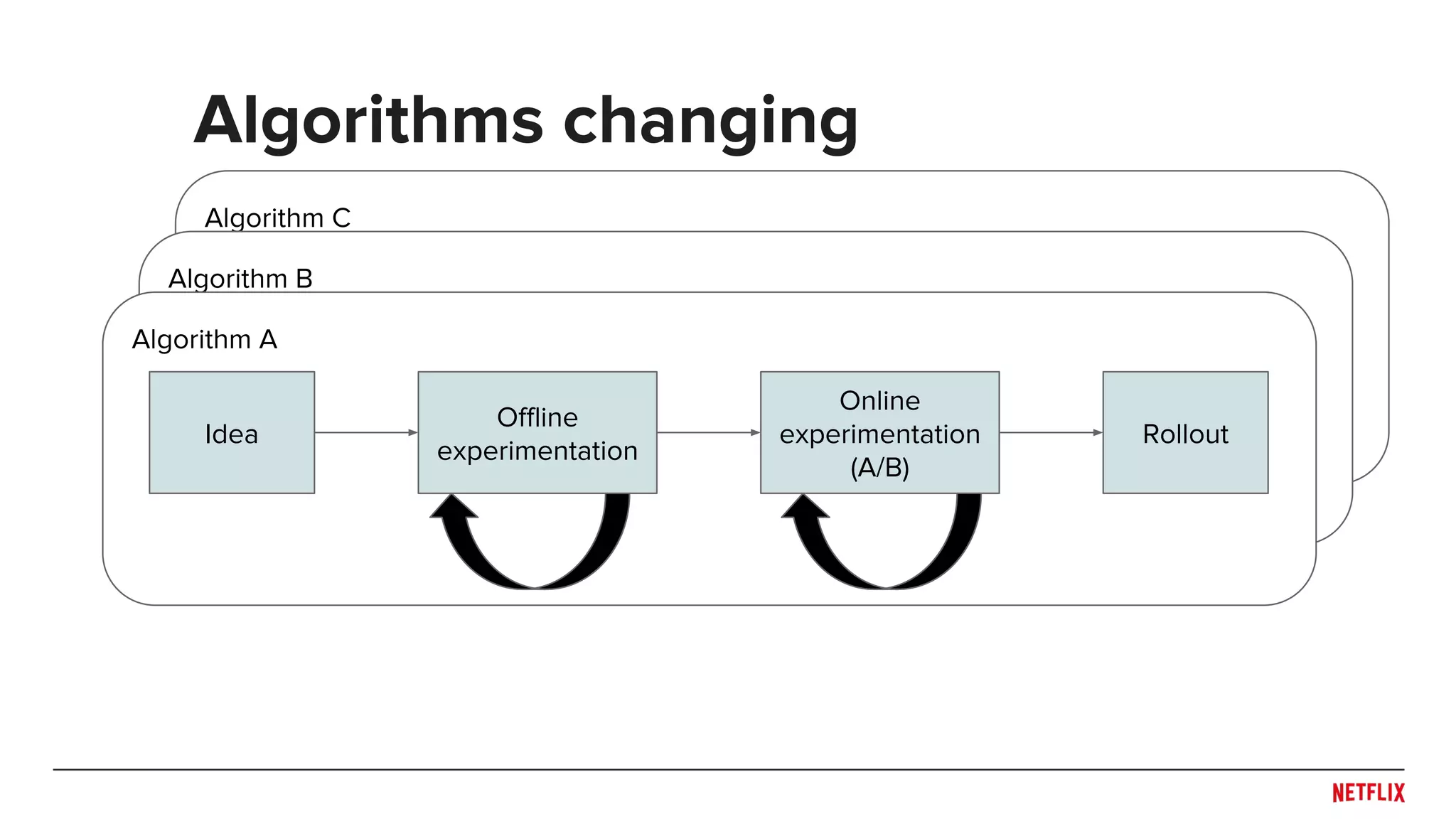
![● Be careful when splitting dataset
○ Don’t overfit the past
○ Predict the future
● Rule of thumb: Split across what you need to generalize
○ Time!
○ Users or Items?
● May need to train/test at multiple distinct time points to see
generalization across time (e.g. [Lathia et. al., 2009])
● Simulate system behaviors (e.g. training and publishing
delays) in evaluation pipeline
○ Helps capture trade-off between accuracy and responsiveness
Experiment design
Train
Time
Test](https://image.slidesharecdn.com/dejavu-170829135103/75/Deja-Vu-The-Importance-of-Time-and-Causality-in-Recommender-Systems-12-2048.jpg)


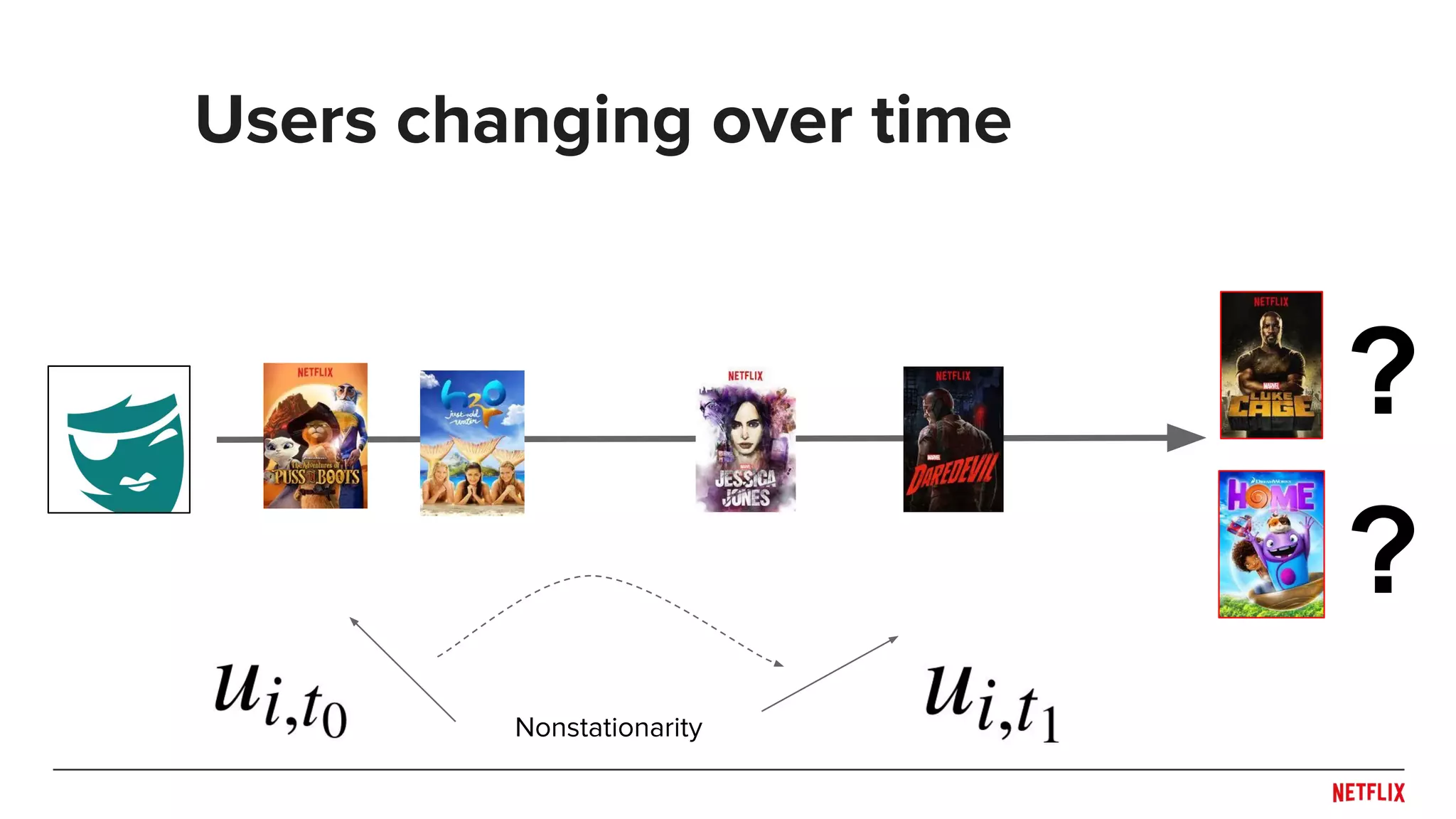
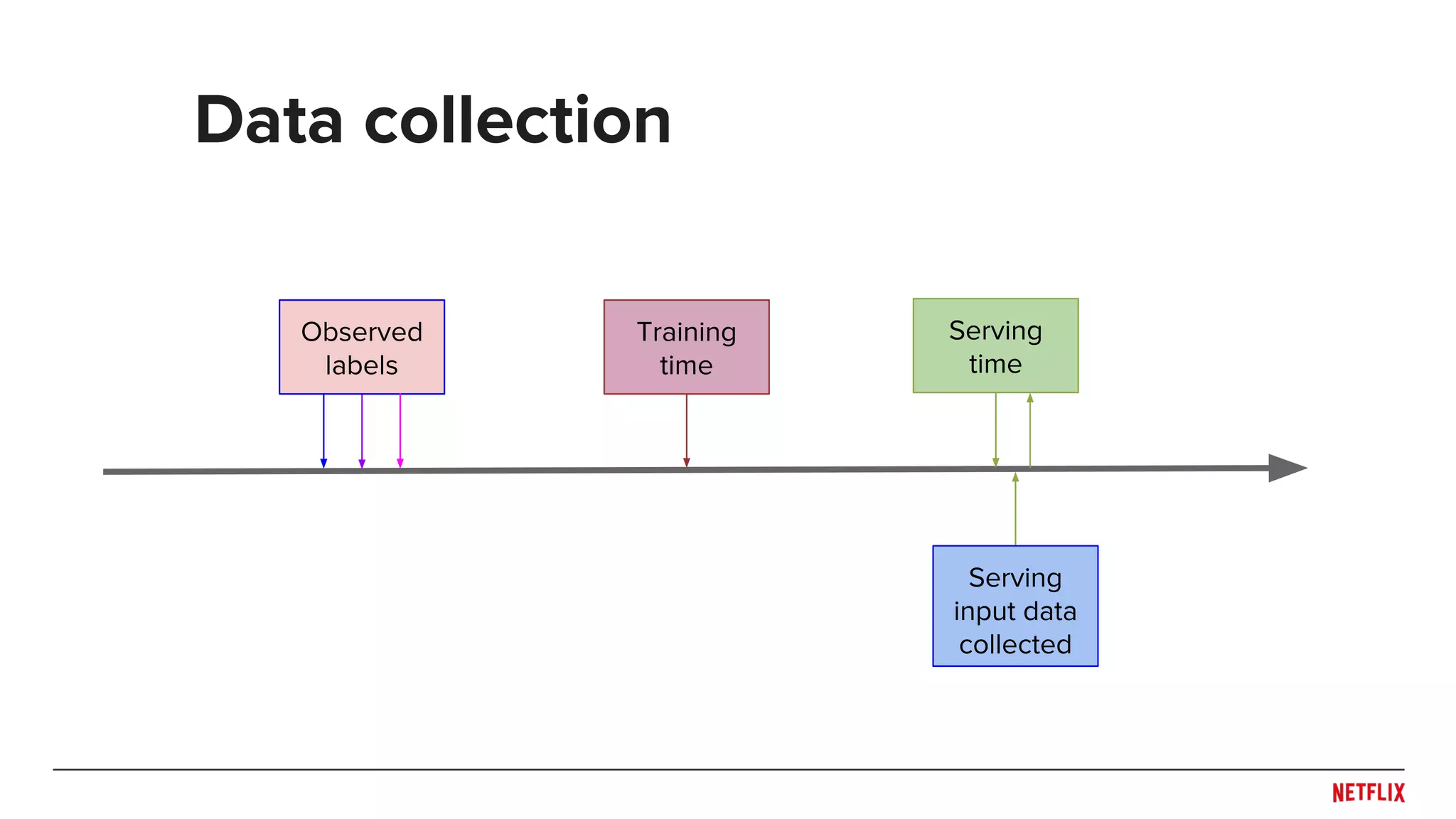
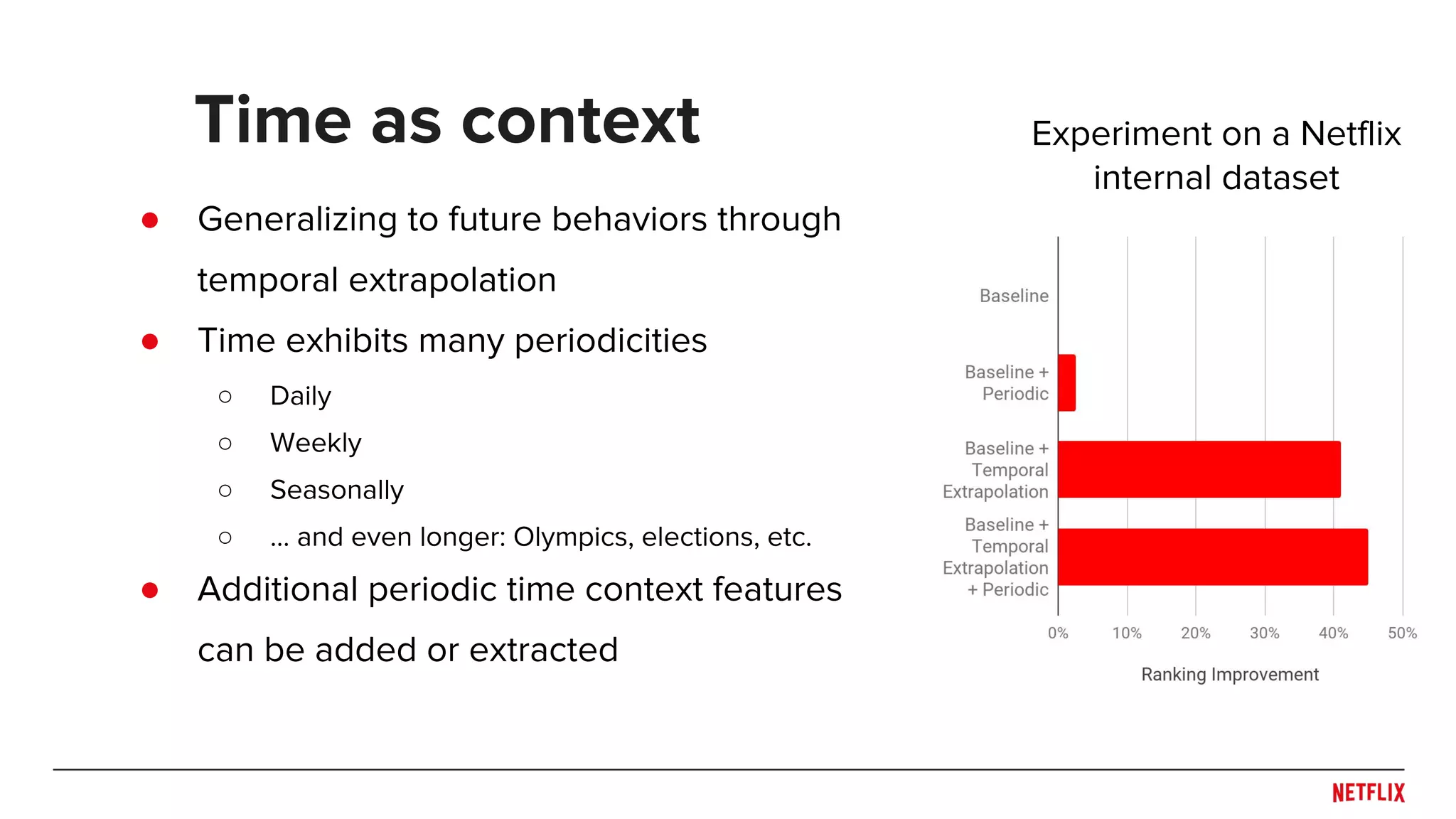
![● Aggregation
○ Decay functions (e.g. [Ding, Li, 2005])
○ Buckets (e.g. [Zimdars, Chickering, Meek, 2001])
● Extrapolation (e.g. [Koren, 2009])
● Sequences
○ Markov (e.g. [Rendle, et al., 2010])
○ Last N (e.g. [Shani, Heckerman, Brafman, 2005])
○ RNNs (e.g. [Hidasi et al., 2015])
● Features
○ Discretized (e.g. [Baltrunas, Amatriain, 2009])
○ Continuous (e.g. example age in [Covington et. al., 2016])
Some modeling approaches time](https://image.slidesharecdn.com/dejavu-170829135103/75/Deja-Vu-The-Importance-of-Time-and-Causality-in-Recommender-Systems-17-2048.jpg)





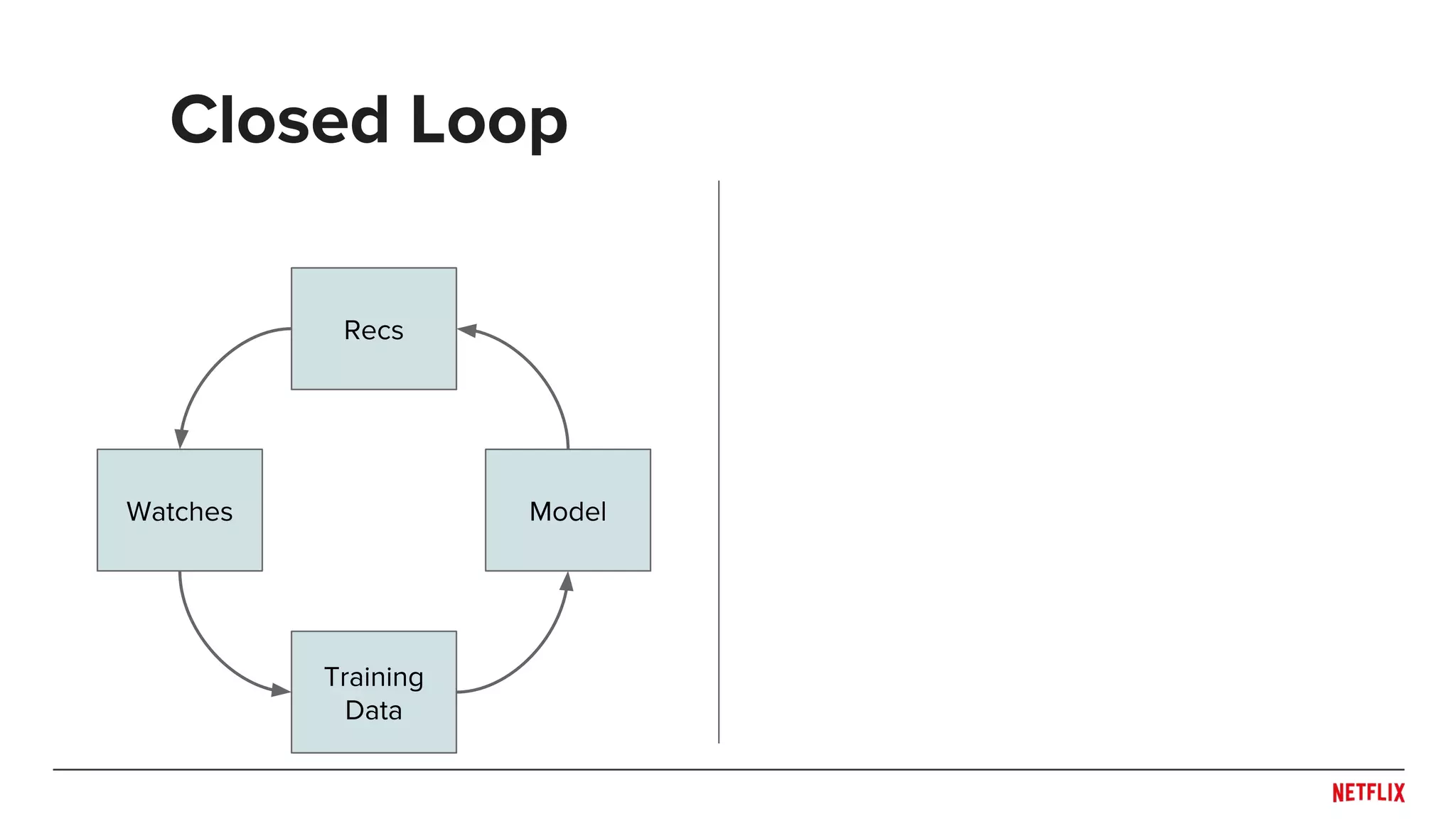
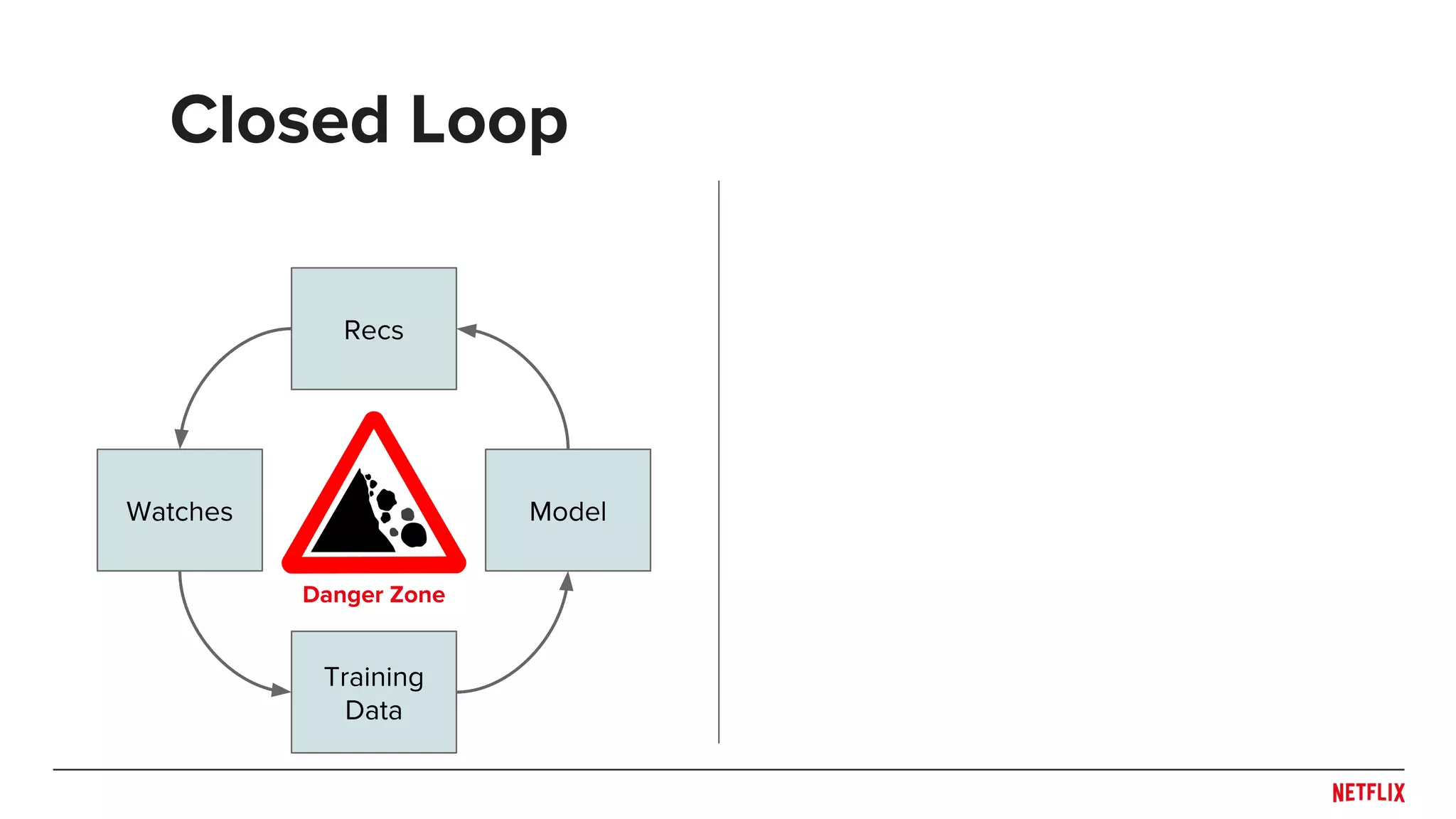
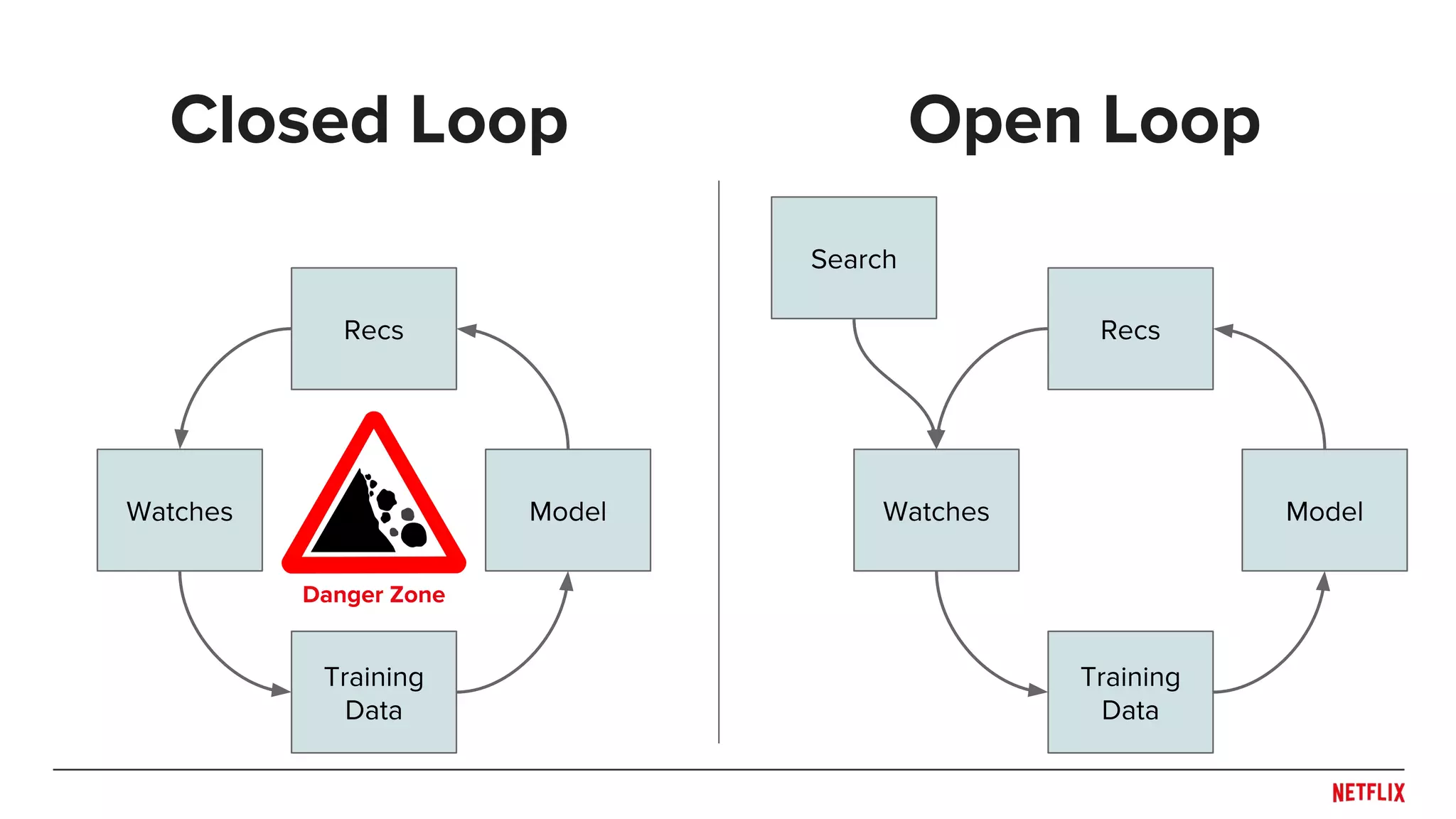
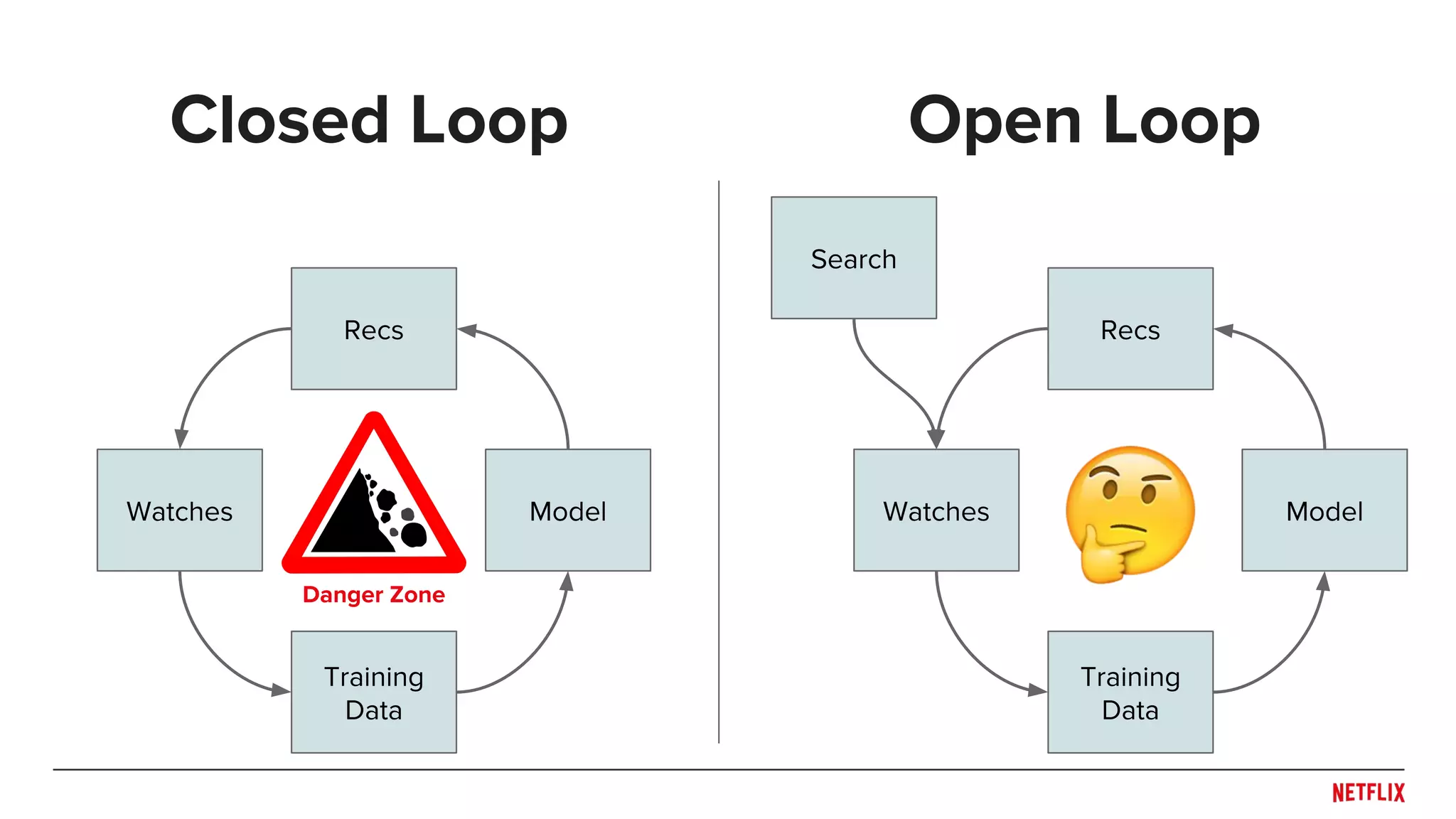
![Open vs. Closed Loops
[Based on Steck, 2013 with system as selector]
Watch when
rec
Probability
of rec
Watch when
not rec
Probability
of not rec](https://image.slidesharecdn.com/dejavu-170829135103/75/Deja-Vu-The-Importance-of-Time-and-Causality-in-Recommender-Systems-34-2048.jpg)
![Open vs. Closed Loops
[Based on Steck, 2013 with system as selector]
Watch when
rec
Probability
of rec
Watch when
not rec
Probability
of not rec
Closed loop: 0
Open loop: > 0](https://image.slidesharecdn.com/dejavu-170829135103/75/Deja-Vu-The-Importance-of-Time-and-Causality-in-Recommender-Systems-35-2048.jpg)
![Open vs. Closed Loops
[Based on Steck, 2013 with system as selector]
Watch when
rec
Probability
of rec
Watch when
not rec
Probability
of not rec
Closed loop: 0
Open loop: > 0
We have control
over this](https://image.slidesharecdn.com/dejavu-170829135103/75/Deja-Vu-The-Importance-of-Time-and-Causality-in-Recommender-Systems-36-2048.jpg)
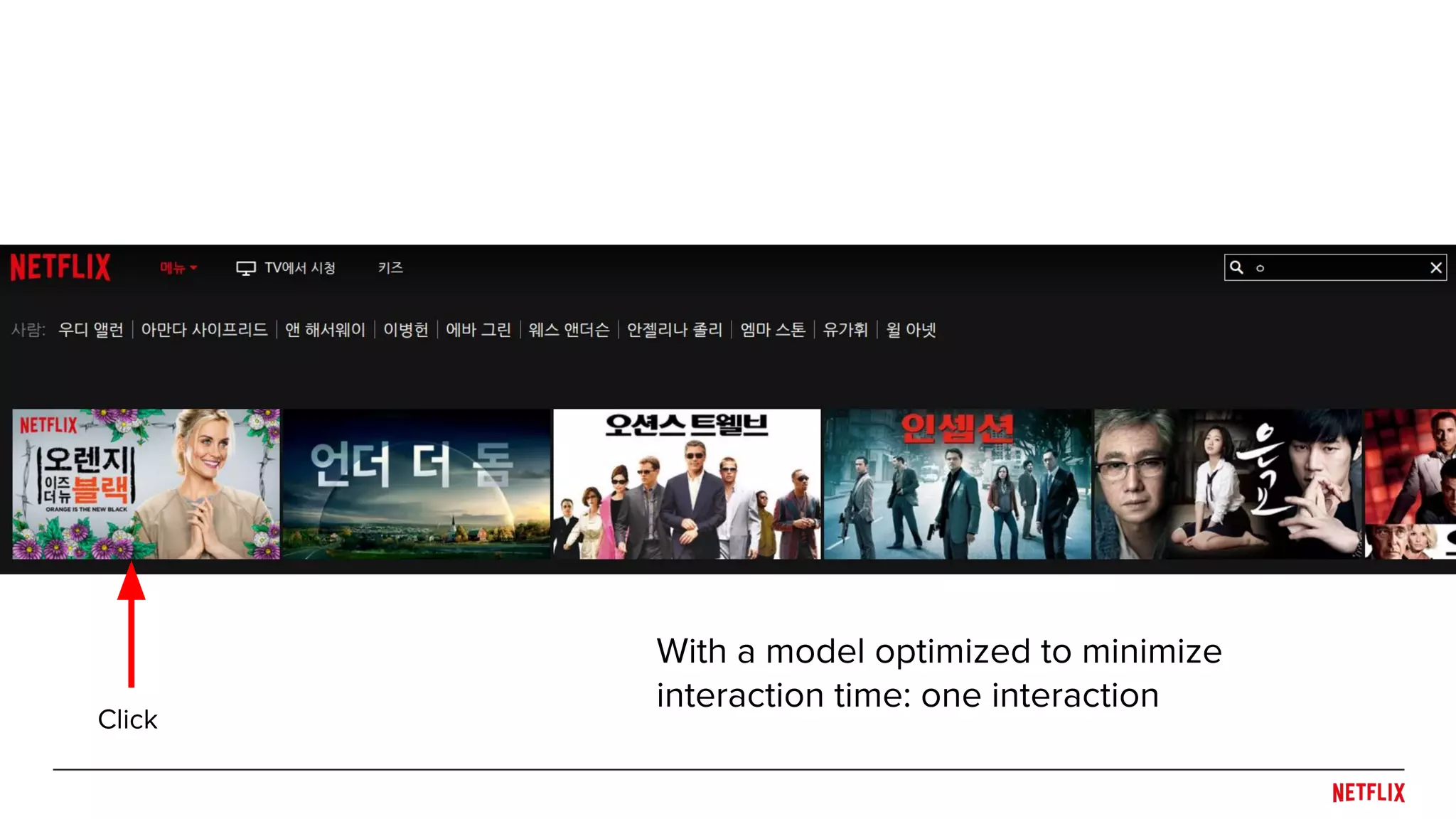
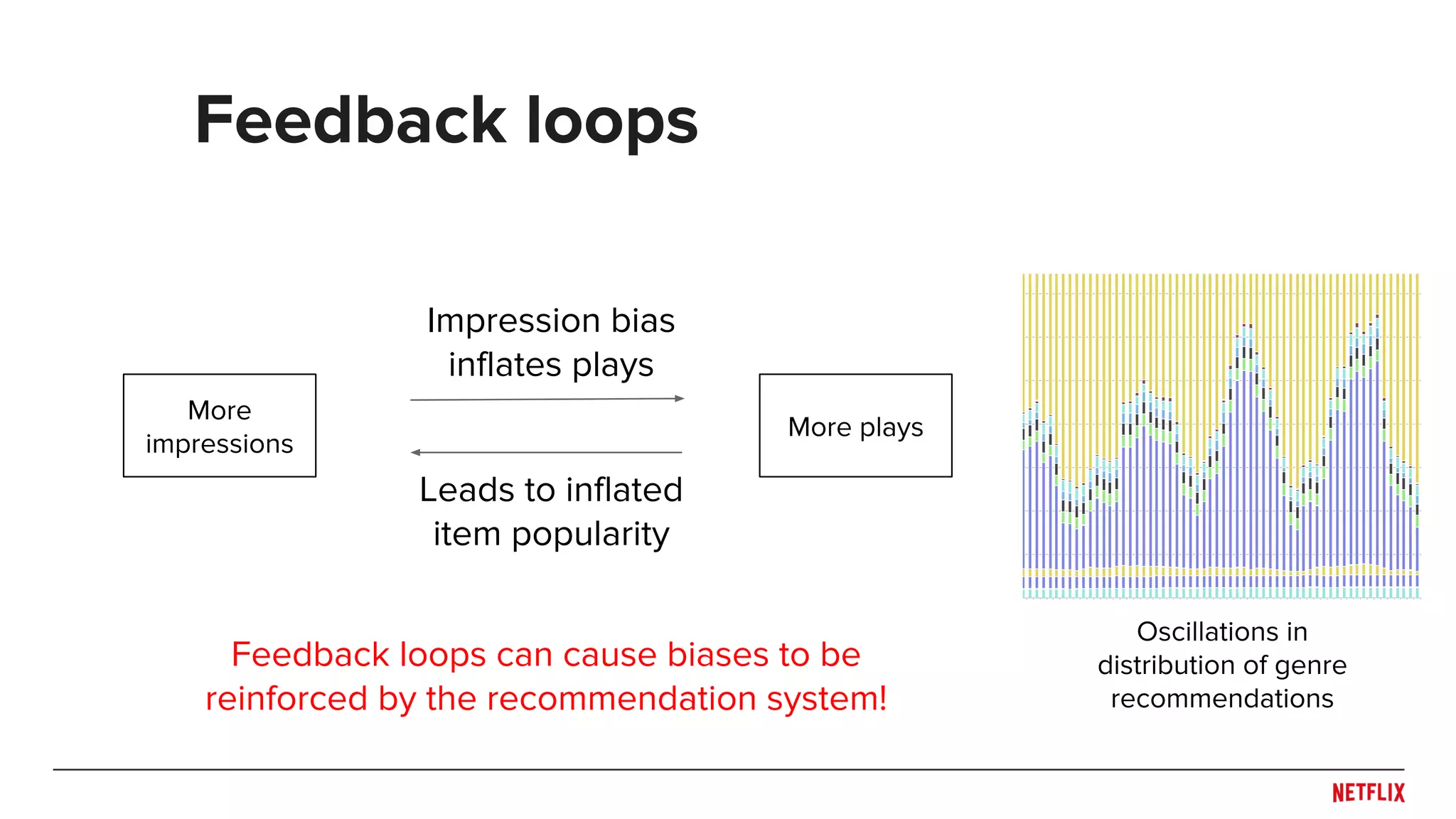
![● Maintain some controlled exploration to break
feedback loop and handle non-stationarities
● Explore with -greedy, Thompson Sampling, etc.
● Control to avoid significantly degrading user
experience
● Log as much as possible
○ Include counterfactuals: What maximal action
system wanted to do (e.g. [Bottou et al., 2013])
Controlled stochasticity
Explore
Explore](https://image.slidesharecdn.com/dejavu-170829135103/75/Deja-Vu-The-Importance-of-Time-and-Causality-in-Recommender-Systems-37-2048.jpg)
![Replay Metrics
Observed
reward
Existing
recommendation
algorithm (with
stochasticity)
Observed
reward
New recommendation
algorithm
[Li et al., 2011; Dudik, Langford, Li, 2014]
Simulate online metrics, offline!](https://image.slidesharecdn.com/dejavu-170829135103/75/Deja-Vu-The-Importance-of-Time-and-Causality-in-Recommender-Systems-38-2048.jpg)
![● Stochasticity opens the door to using causal inference
● Inverse Propensity Weighting
○ Reduce production bias by reweighting train and test data
○ Know probability of user receiving an impression
○ Doesn’t handle simultaneity and other endogeneity
● Covariate shift
○ Use explore data to estimate bias in other data
○ Use all data to train
● Instrumental variables for more general settings
Causality
[Schnabel et al., 2016; Liang, Charlin, Blei, 2016; Smola, 2011, Sugiyama, Kawanabe, 2012]](https://image.slidesharecdn.com/dejavu-170829135103/75/Deja-Vu-The-Importance-of-Time-and-Causality-in-Recommender-Systems-39-2048.jpg)
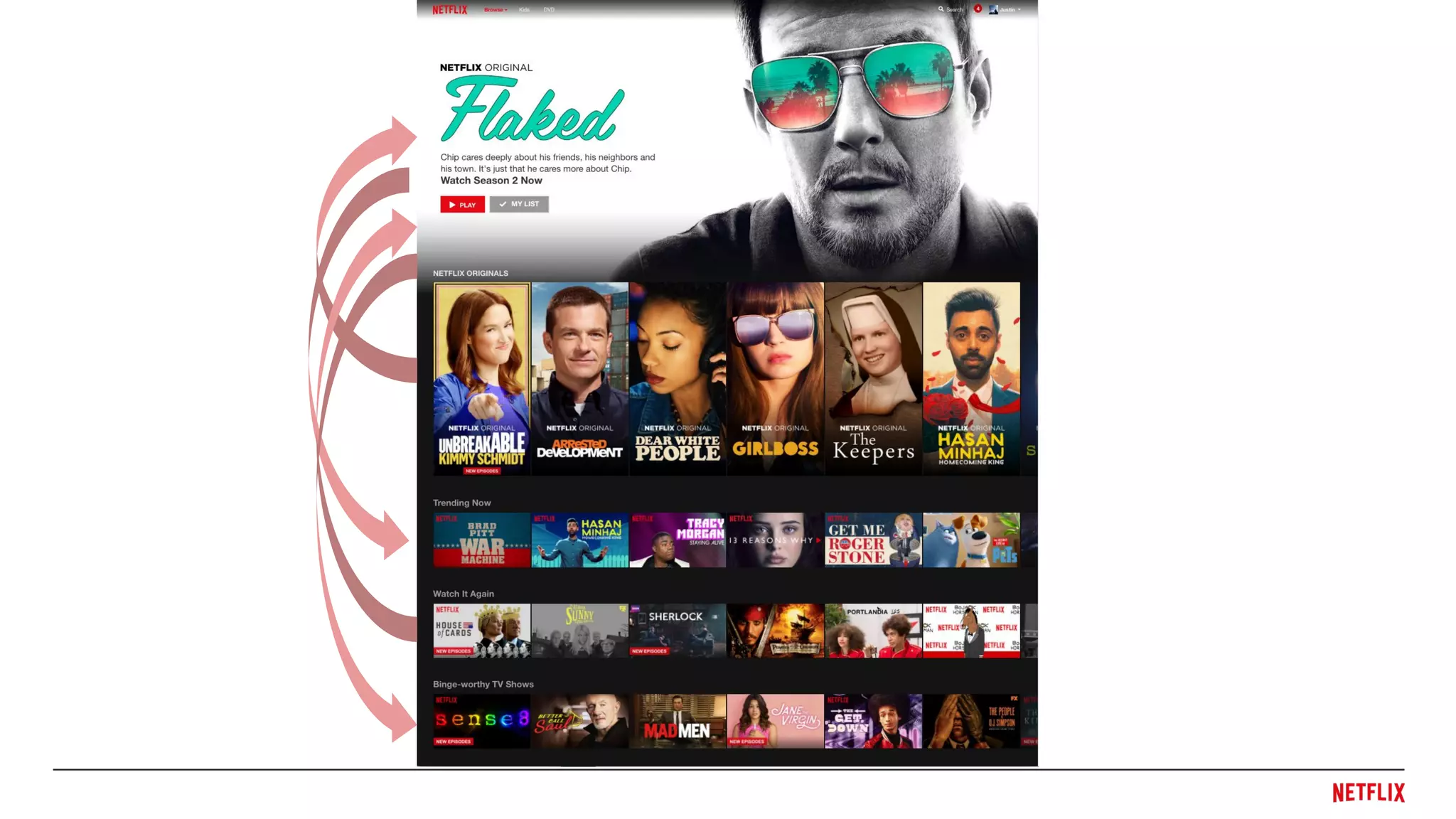
![● Most recommendations (and ML) models are correlational
○ These items are correlated with these types of users
● But we seek causal actions
○ Showing this item is rewarding for this user
● Our recommendation action should have an incremental
effect in reward: E[r(a)] - E[r(∅)]
○ Application-dependent choice of ∅
○ Sometimes it may be better not to provide a recommendation that
simply maximizes p(vi
|u)
○ May provide less obvious recommendations
Incrementality
p(vi
|∅) p(vi
|a)
Incremental
effect](https://image.slidesharecdn.com/dejavu-170829135103/75/Deja-Vu-The-Importance-of-Time-and-Causality-in-Recommender-Systems-40-2048.jpg)






This document discusses the importance of time and causality in recommender systems. It summarizes that (1) time and causality are critical aspects that must be considered in data collection, experiment design, algorithms, and system design. (2) Recommender systems operate within a feedback loop where the recommendations influence future user behavior and data, so effects like reinforcement of biases can occur. (3) Both offline and online experimentation are needed to properly evaluate systems and generalization over time.







































![Why [Mobile] [In-app] Programmatic? A Marketer's Guide](https://cdn.slidesharecdn.com/ss_thumbnails/mopub-mobile-programmatic-benefits-web-160805140554-thumbnail.jpg?width=640&height=640&fit=bounds)












![[UPDATE] Udacity webinar on Recommendation Systems](https://cdn.slidesharecdn.com/ss_thumbnails/udacitywebinar-190716143828-thumbnail.jpg?width=640&height=640&fit=bounds)











![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














