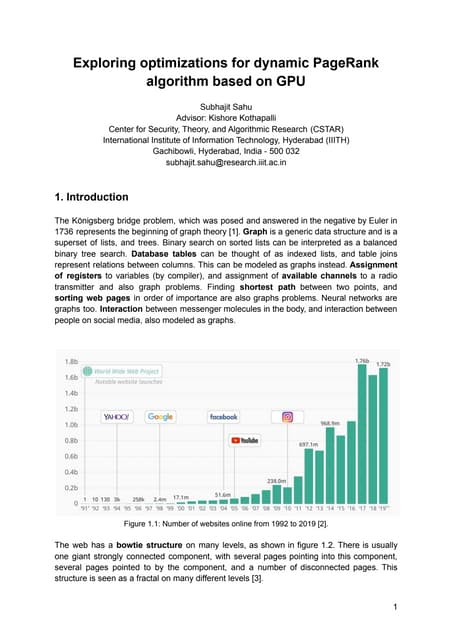
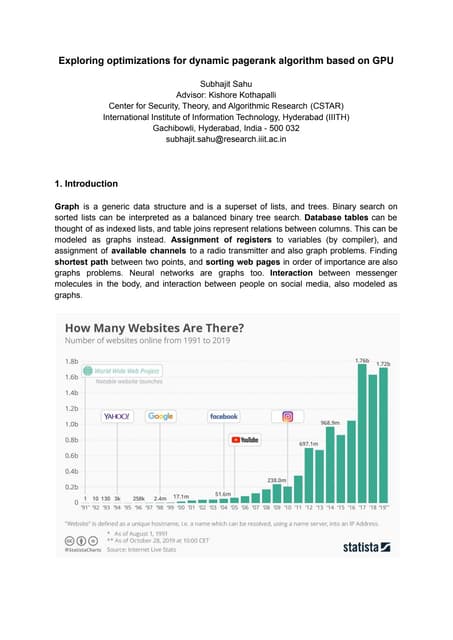
Downloaded 228 times













































![Q.E.D
Thanks for keeping up!
Question =>
Future[(Option[Response], Future[Question])]](https://image.slidesharecdn.com/mlandgraphx-141025103752-conversion-gate01/85/Machine-Learning-and-GraphX-46-320.jpg)

The document discusses using Apache Spark's GraphX library to analyze large graph datasets. It provides an overview of graph data structures and PageRank, describes how GraphX implements graph algorithms like PageRank using a Pregel-like approach, and demonstrates analyzing large street network graphs from OpenStreetMap data to compare cities based on normalized PageRank distributions.