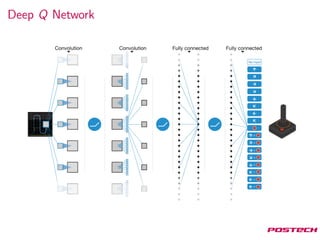
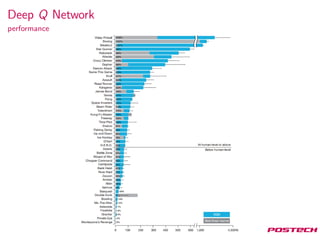
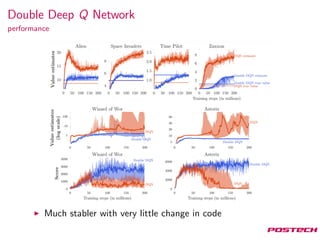
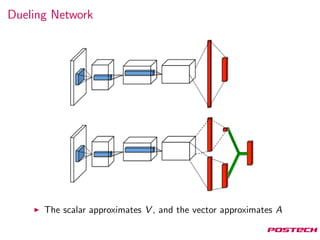
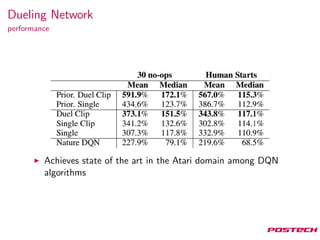
This document summarizes reinforcement learning algorithms like Deep Q-Network (DQN), Double DQN, prioritized experience replay, and the Dueling Network architecture. DQN uses a deep neural network to estimate the Q-function and select actions greedily during training. Double DQN decouples action selection from evaluation to reduce overestimation. Prioritized replay improves sampling to focus on surprising transitions. The Dueling Network separately estimates the state value and state-dependent action advantages to better determine the optimal action. It achieves state-of-the-art performance on Atari games by implicitly splitting credit assignment between choosing now versus later actions.







![Mathematical formulations
Q-Value
Gt =
∞
i=0
γk
rt+i+1
Definition
The action-value (Q-value) function Qπ(s, a) is the expectation of
Gt under taking action a, and then following policy π afterwards
Qπ(s, a) = Eπ[Gt|St = s, At = a, At+i = π(St+i )∀i ∈ N]
”How good is action a in state s?”](https://image.slidesharecdn.com/20161011-170925075728/85/Dueling-Network-Architectures-for-Deep-Reinforcement-Learning-9-320.jpg)