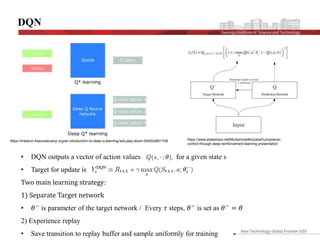
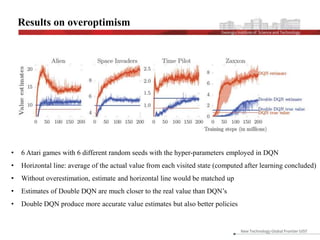
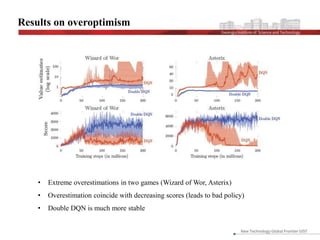
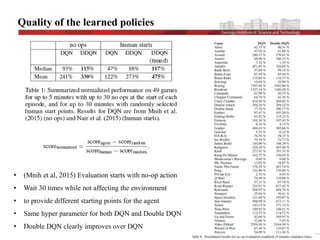
This document discusses the implementation and advantages of deep reinforcement learning using Double Q-Learning, as a solution to the overestimation problems faced by traditional Q-Learning and DQN in Atari games. It introduces the Double DQN algorithm, which reduces overestimation by decoupling action selection and evaluation within the framework of Q-learning, leading to improved performance and more accurate value estimates. The findings demonstrate that Double DQN produces more stable training outcomes and better overall policies compared to its predecessors, particularly in complex environments.