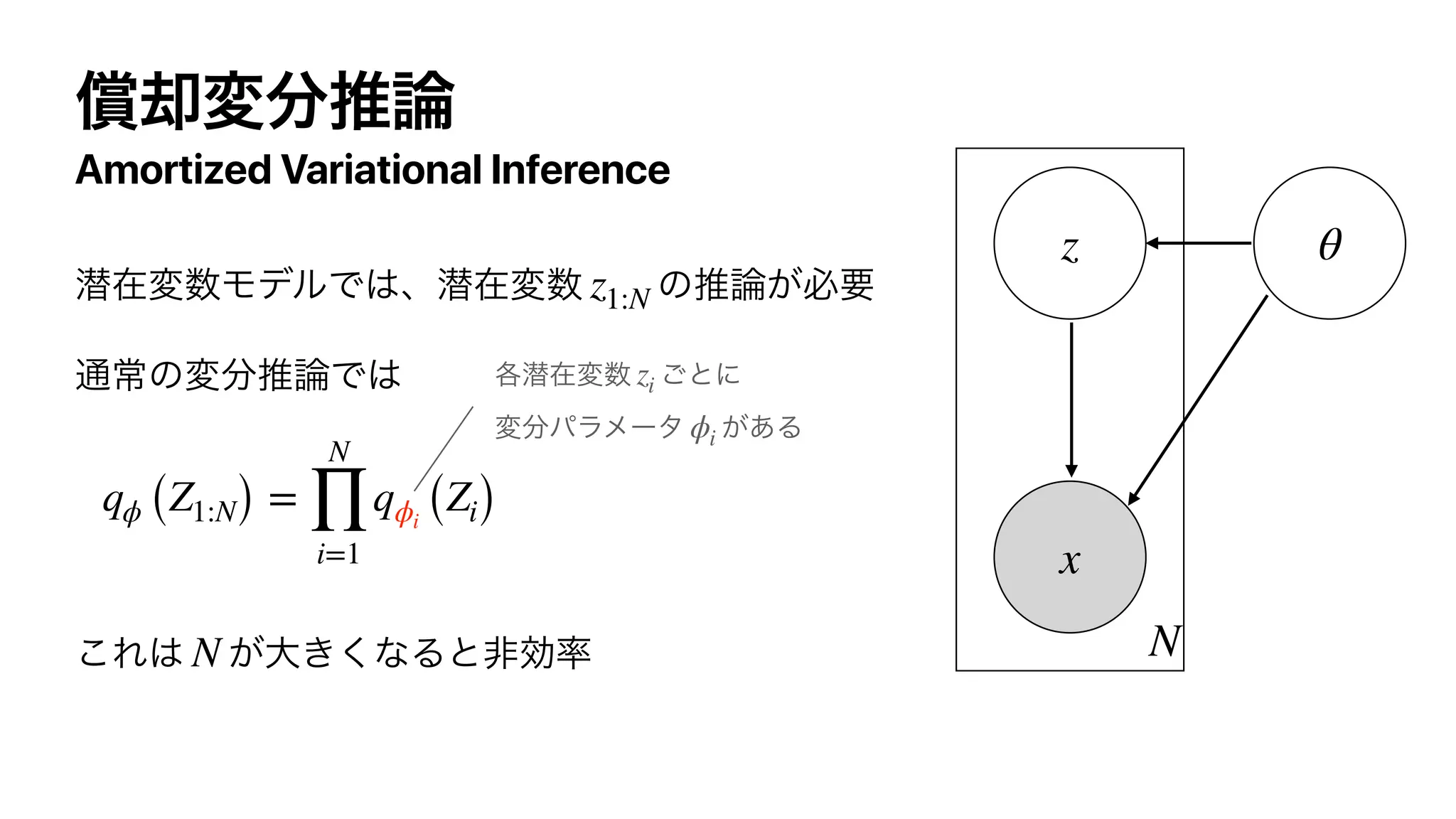
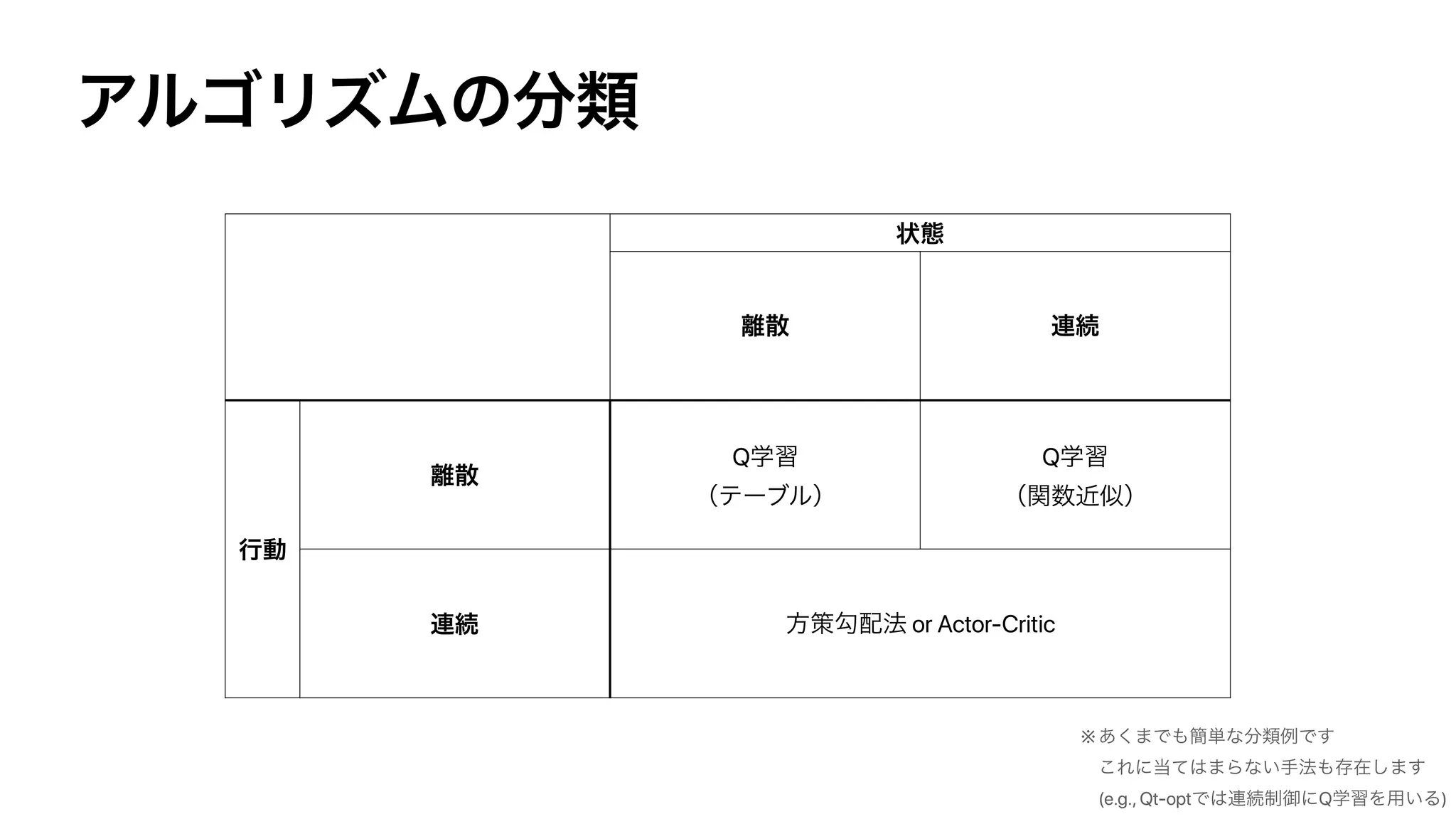
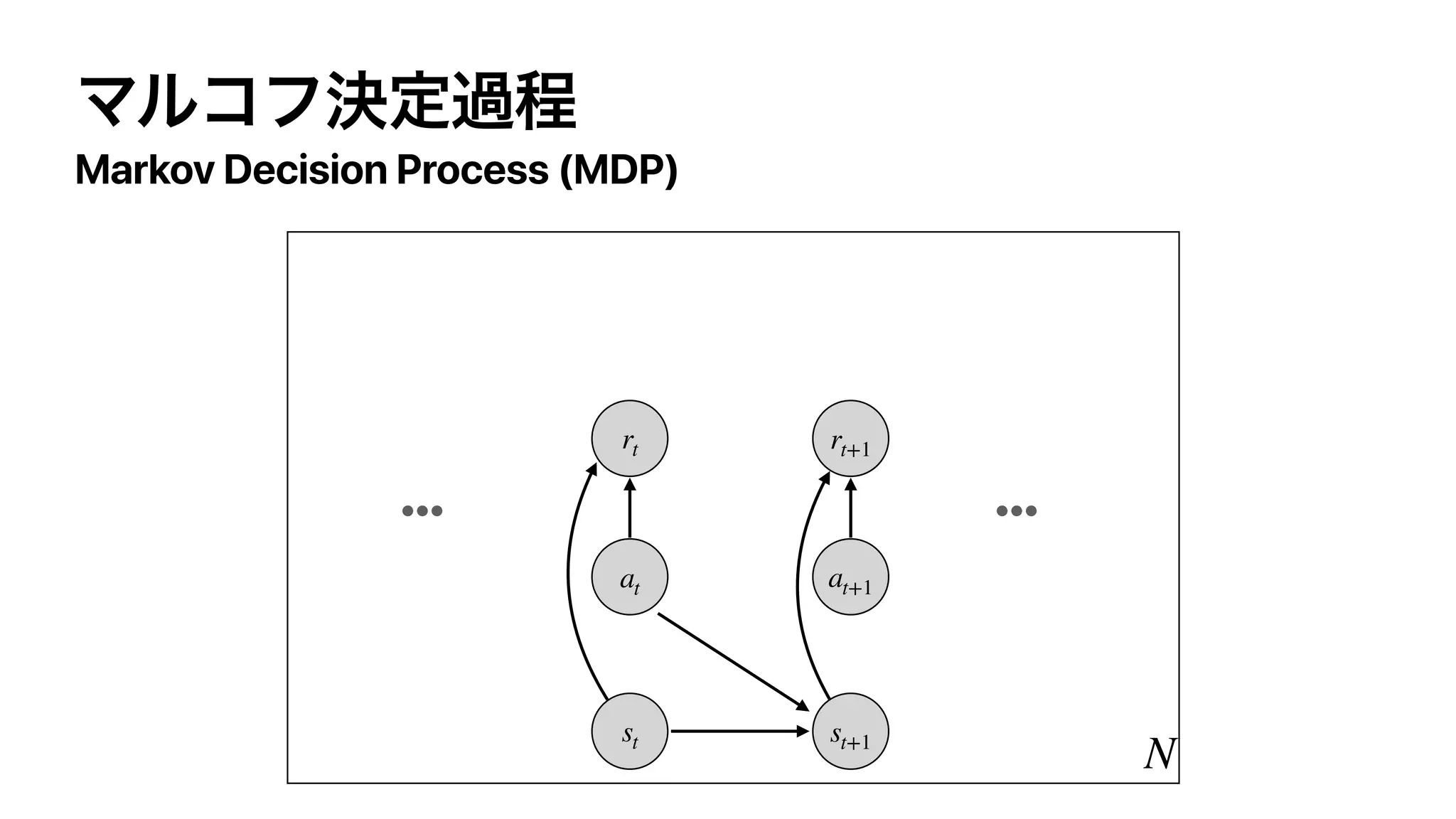
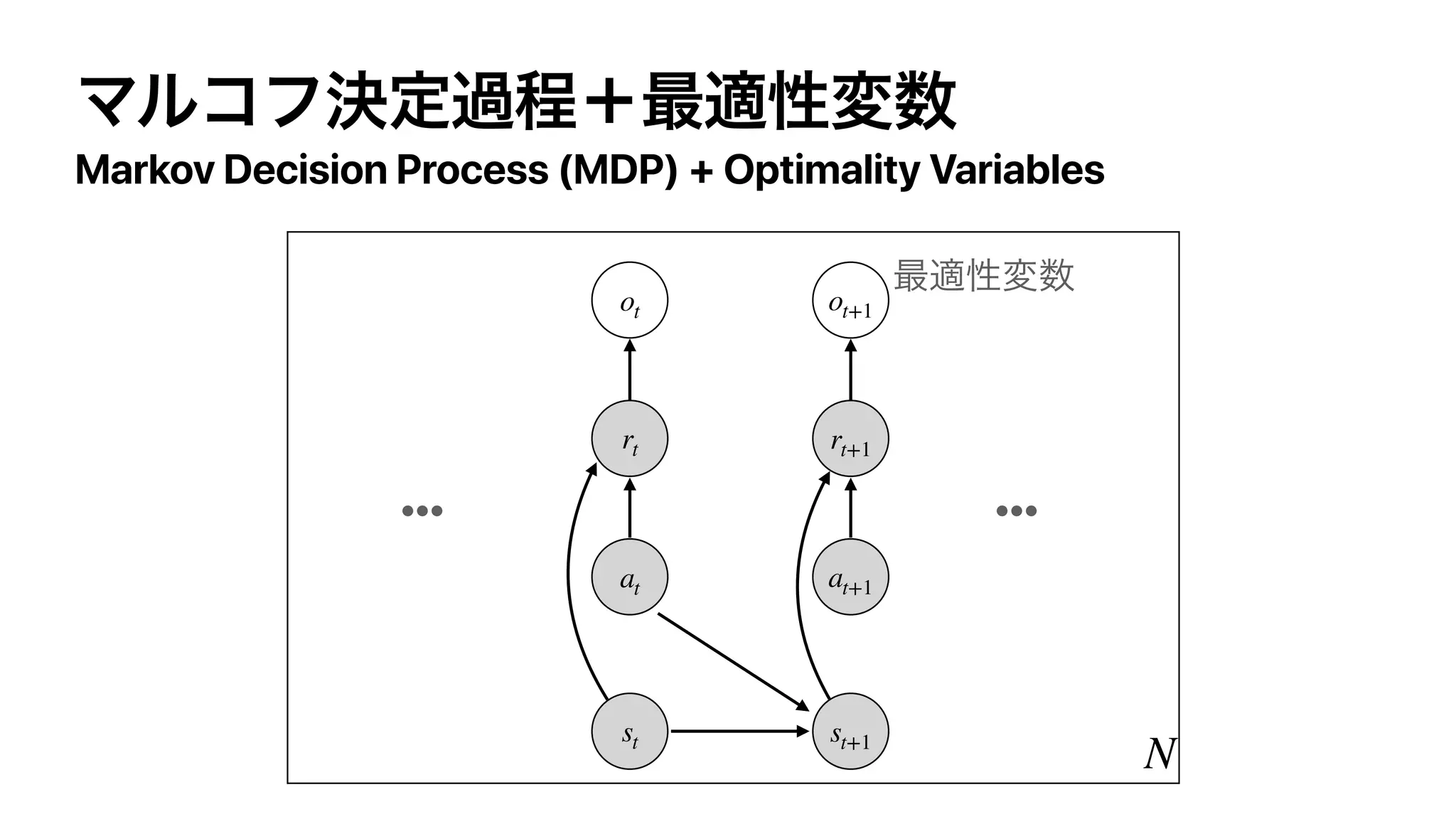
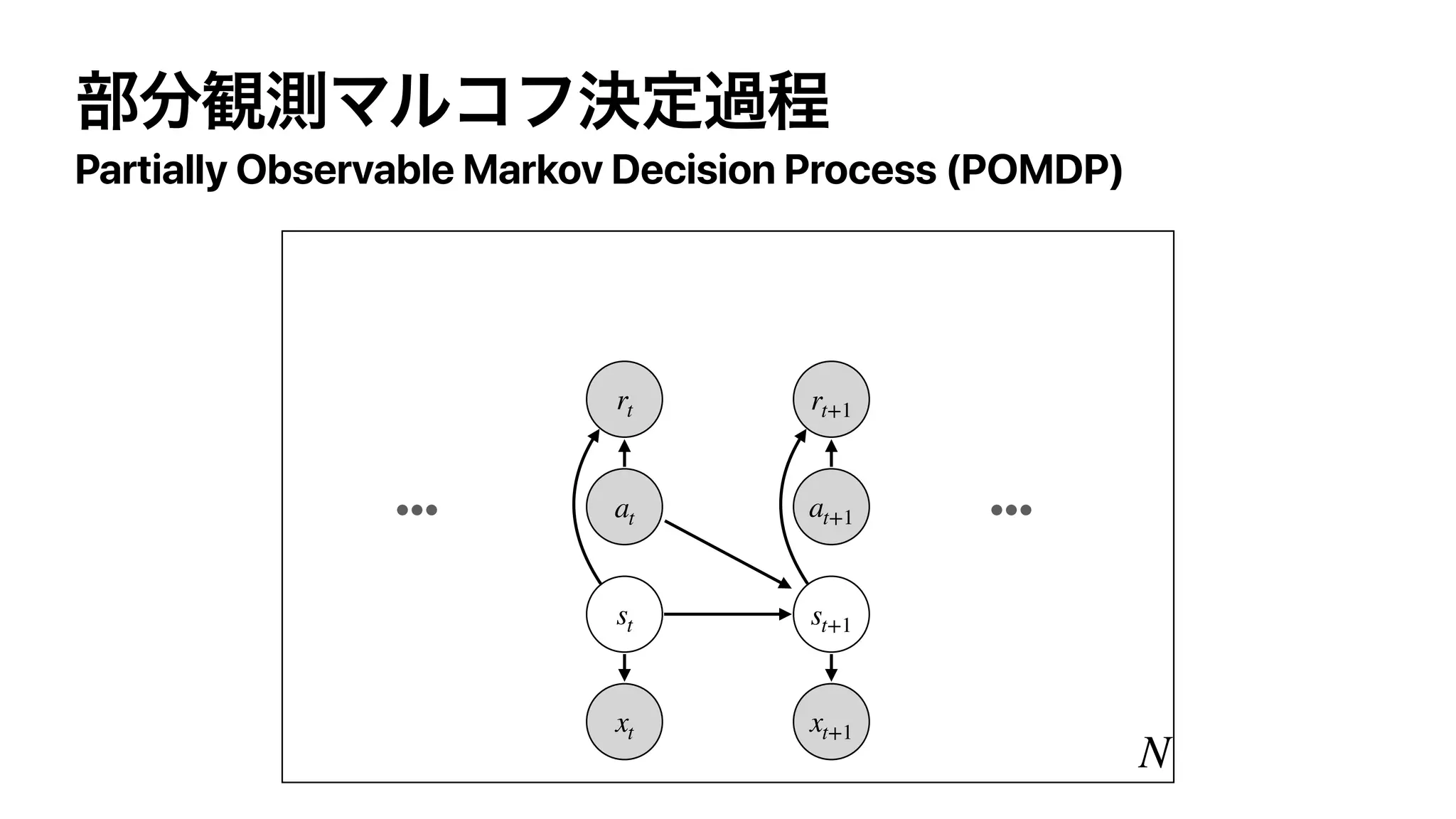
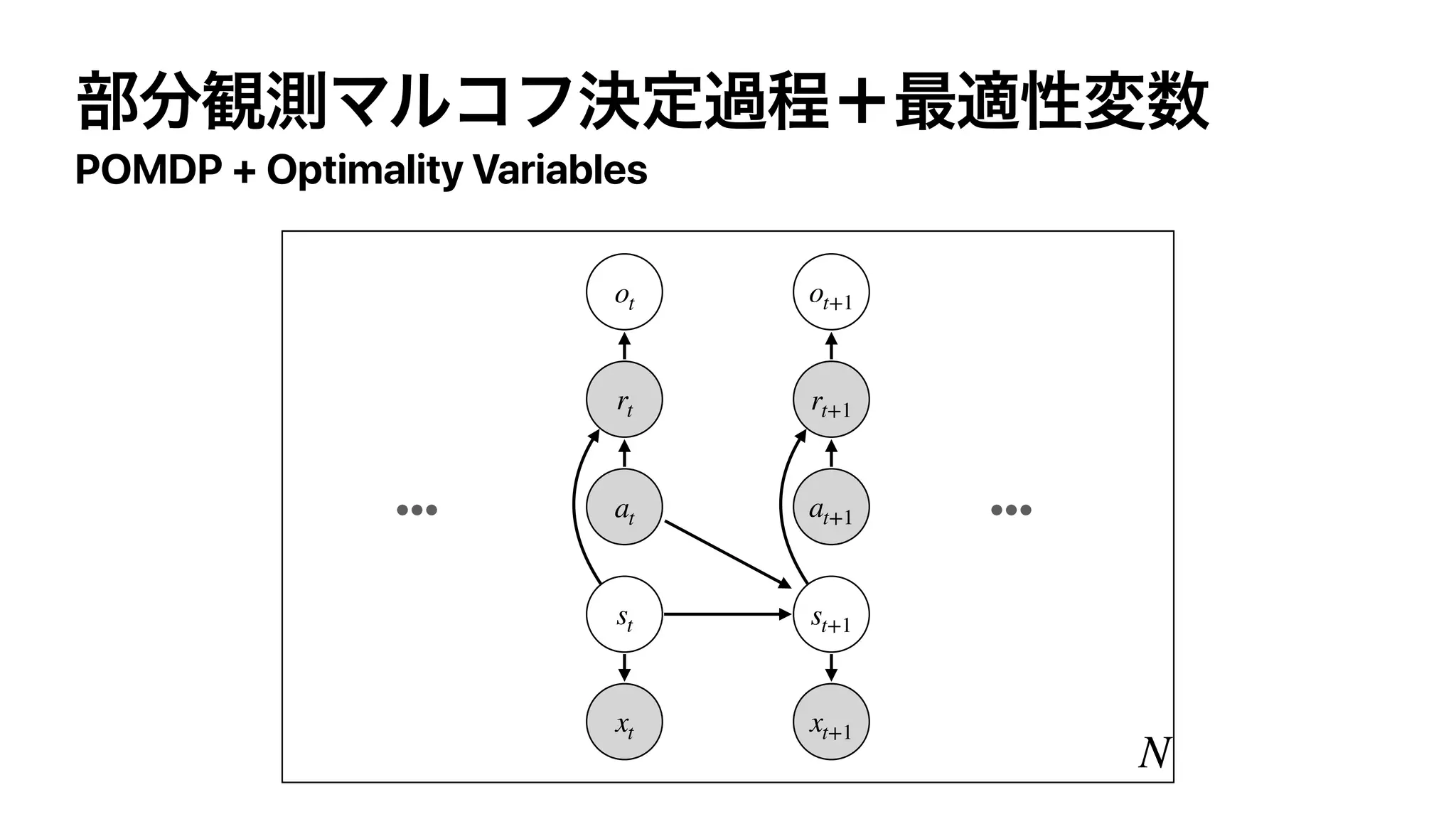
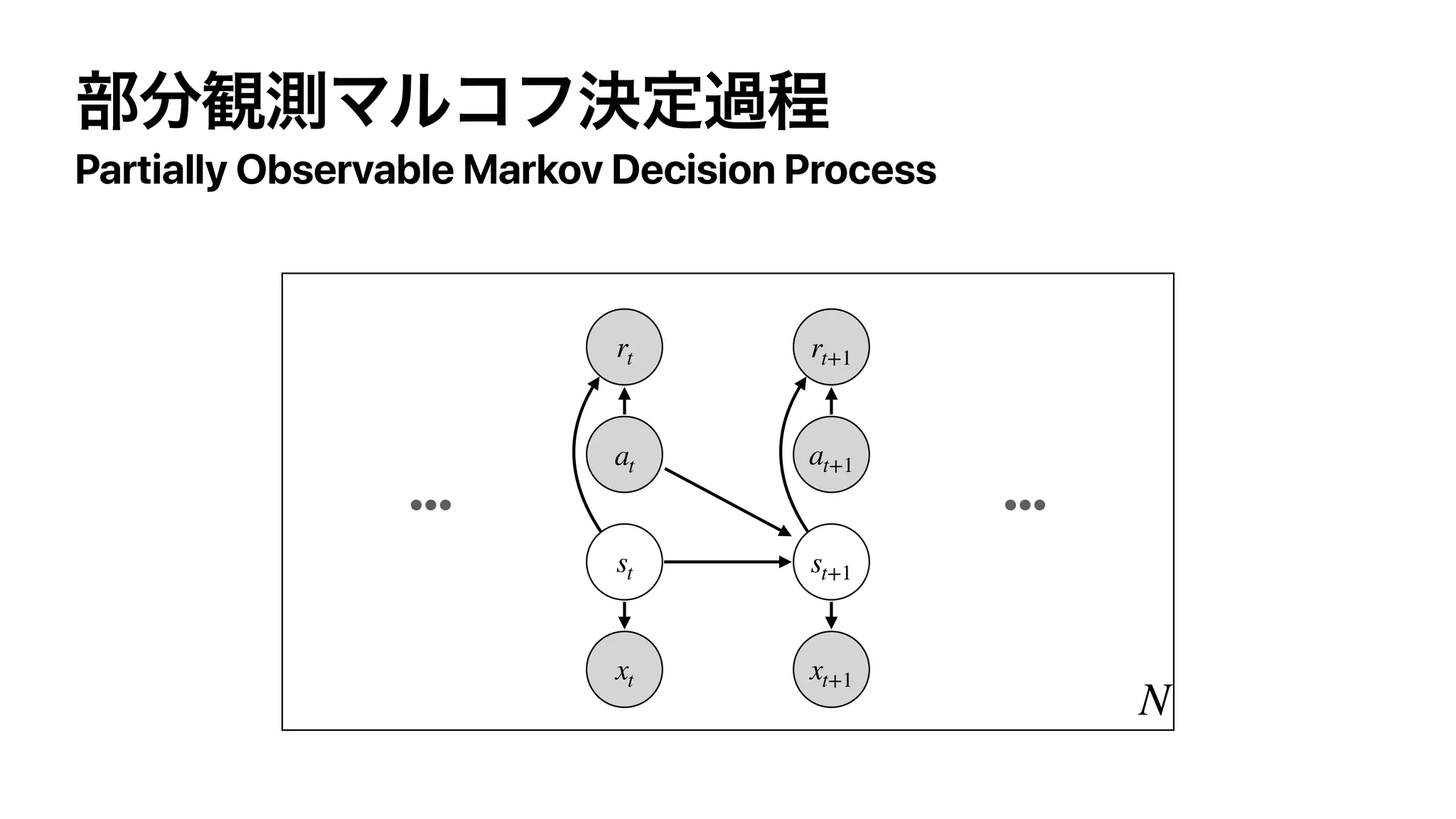
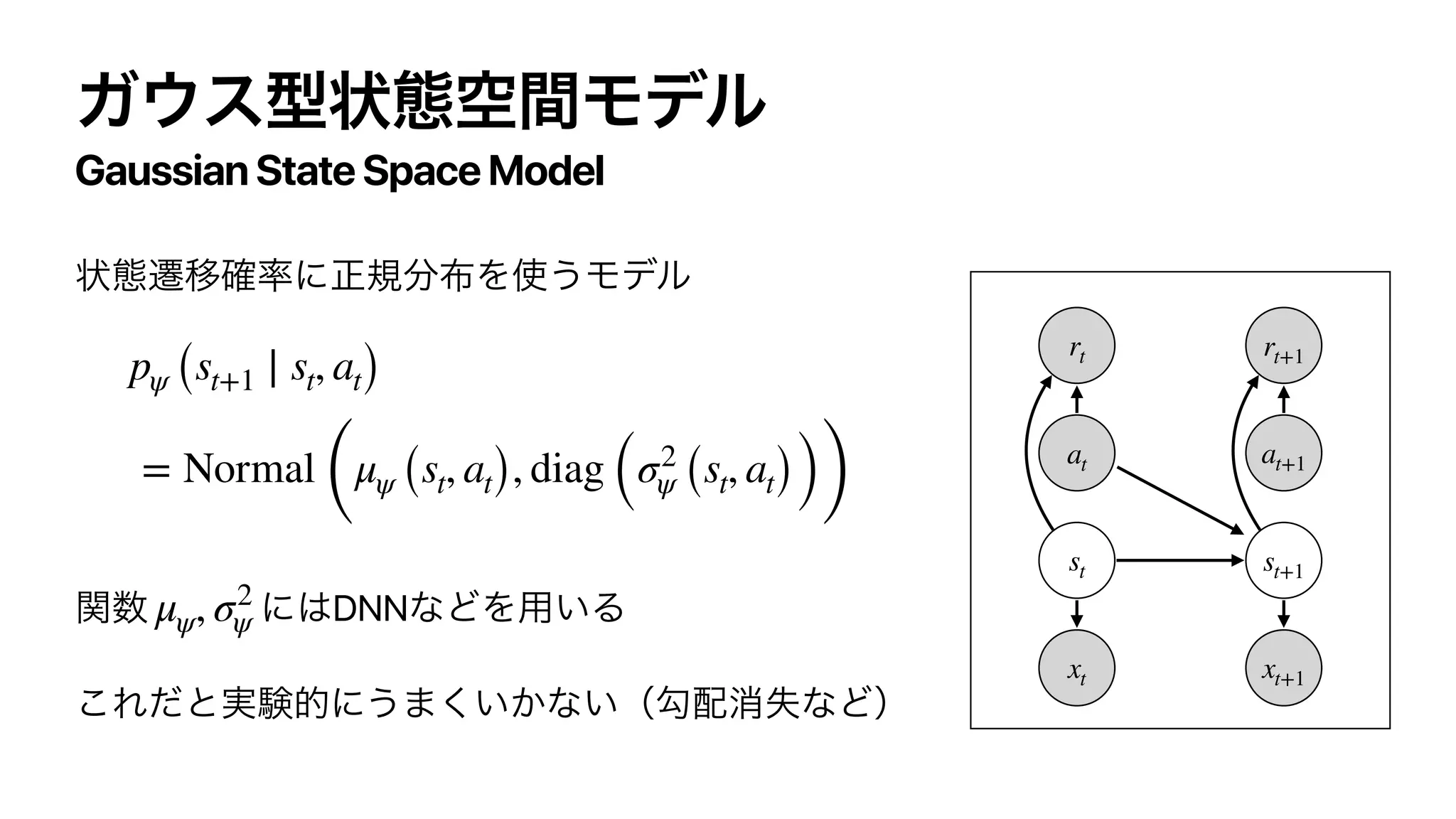
The document discusses control as inference in Markov decision processes (MDPs) and partially observable MDPs (POMDPs). It introduces optimality variables that represent whether a state-action pair is optimal or not. It formulates the optimal action-value function Q* and optimal value function V* in terms of these optimality variables and the reward and transition distributions. Q* is defined as the log probability of a state-action pair being optimal, and V* is defined as the log probability of a state being optimal. Bellman equations are derived relating Q* and V* to the reward and next state value.










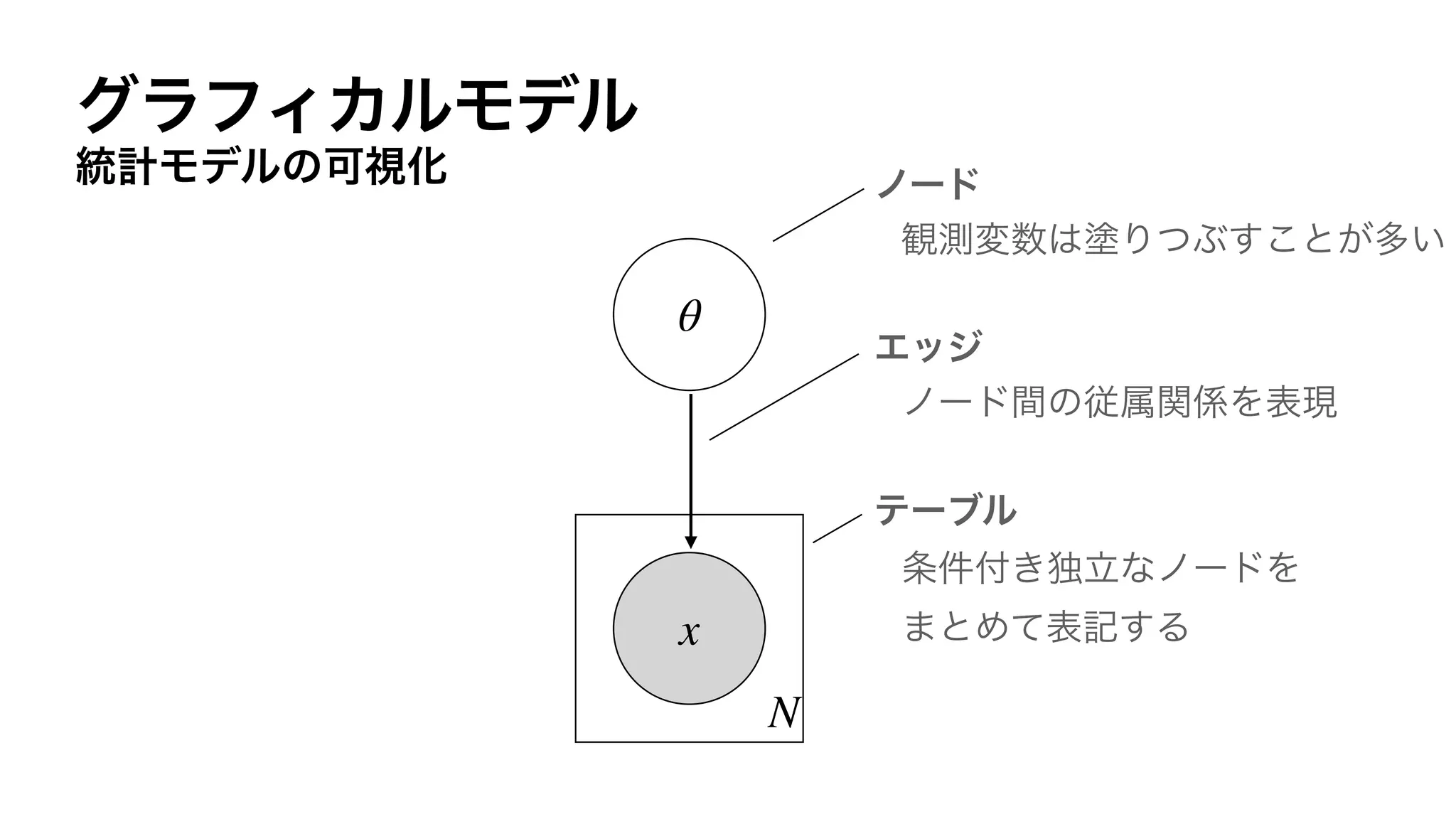
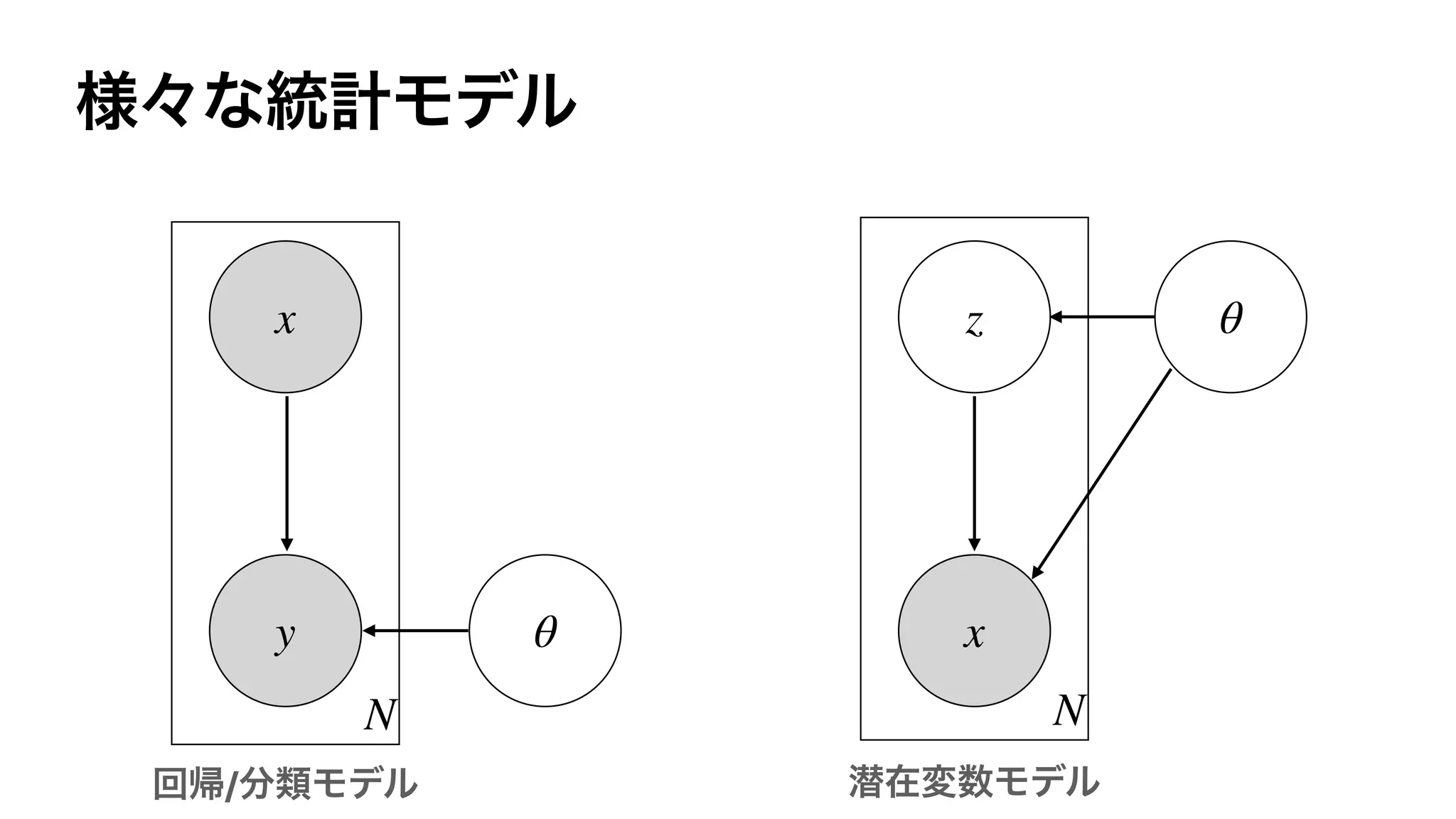
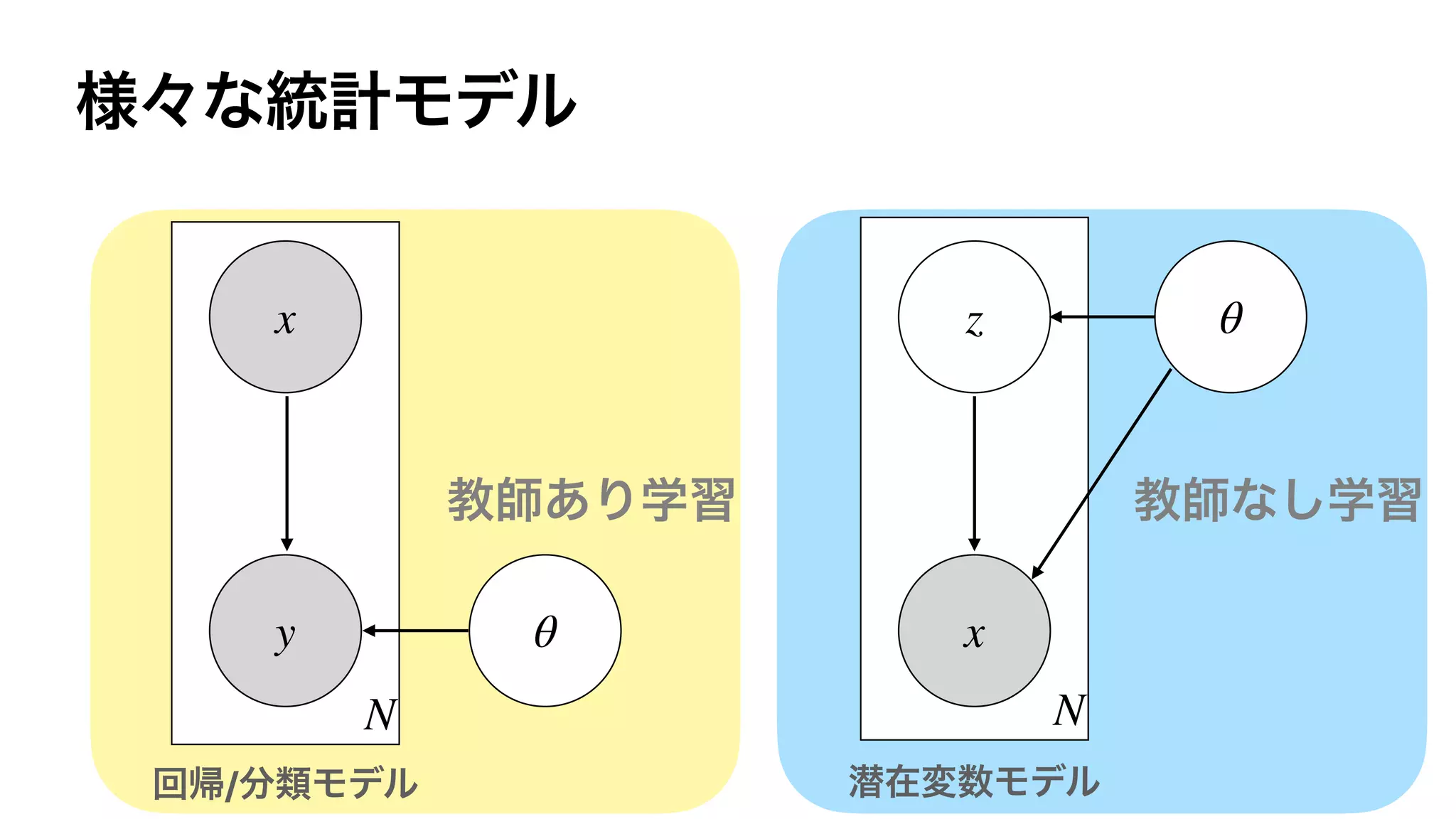
![DNN
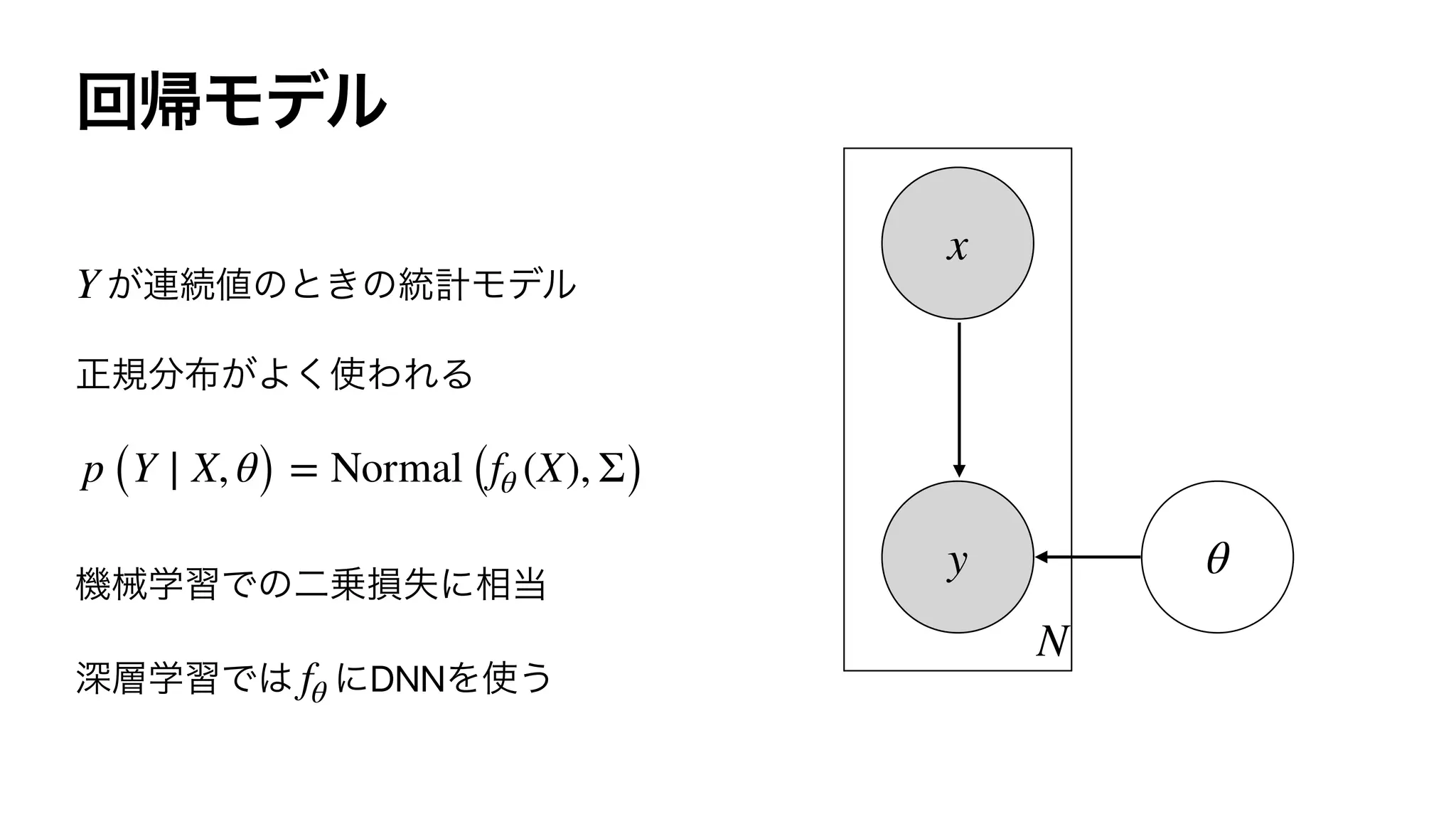
Y
p (Y = k ∣ X, θ) =
exp (fθ (X)[k])
∑
K
k′=1
exp (fθ (X)[k′])
fθ
N
x
y θ](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-20-2048.jpg)
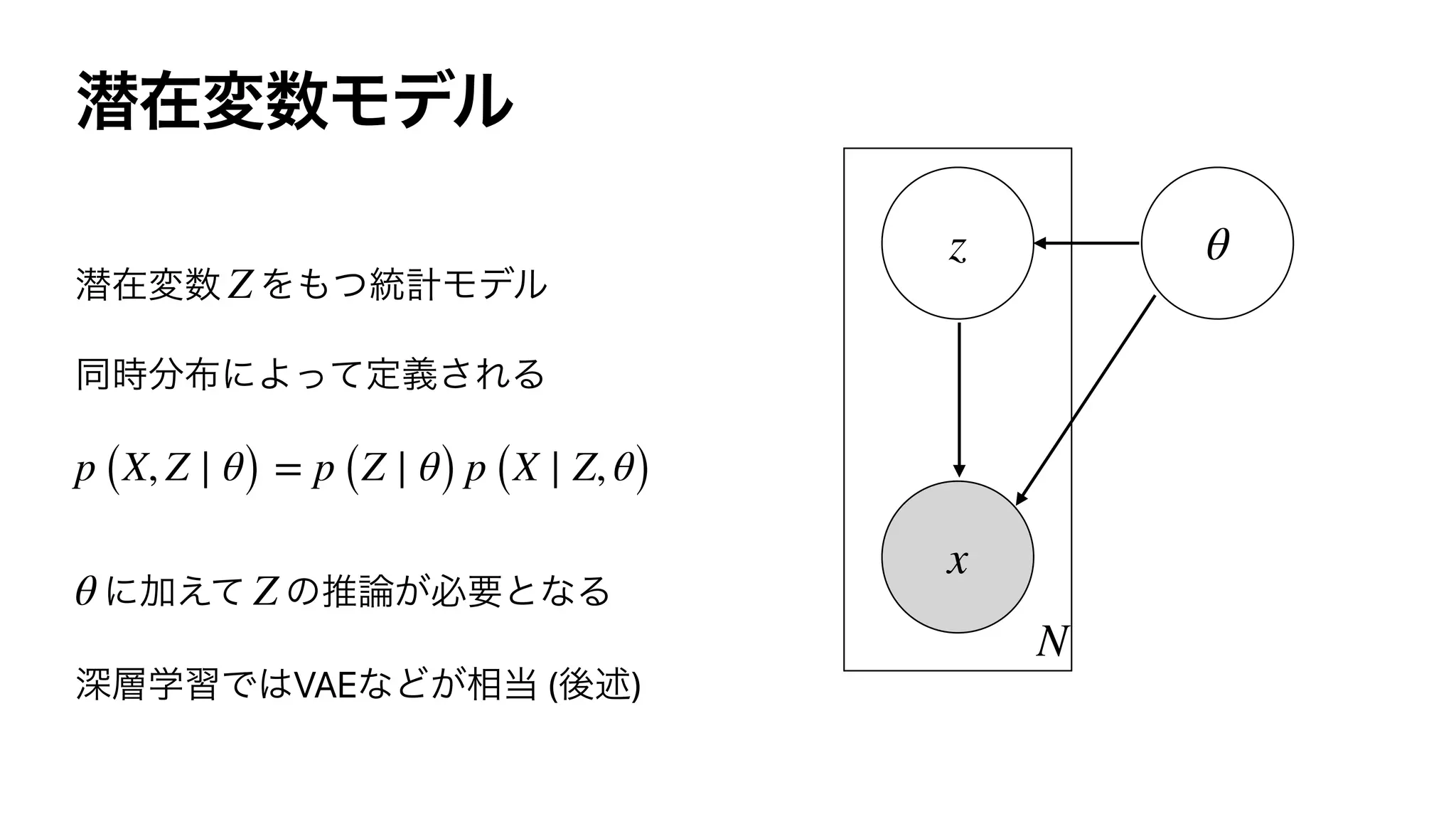



![Bayesian Inference
1
p (X ∣ x1, …, xN) = 𝔼p(θ ∣ X = x1, …, xN) [p (X ∣ θ)]](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-25-2048.jpg)
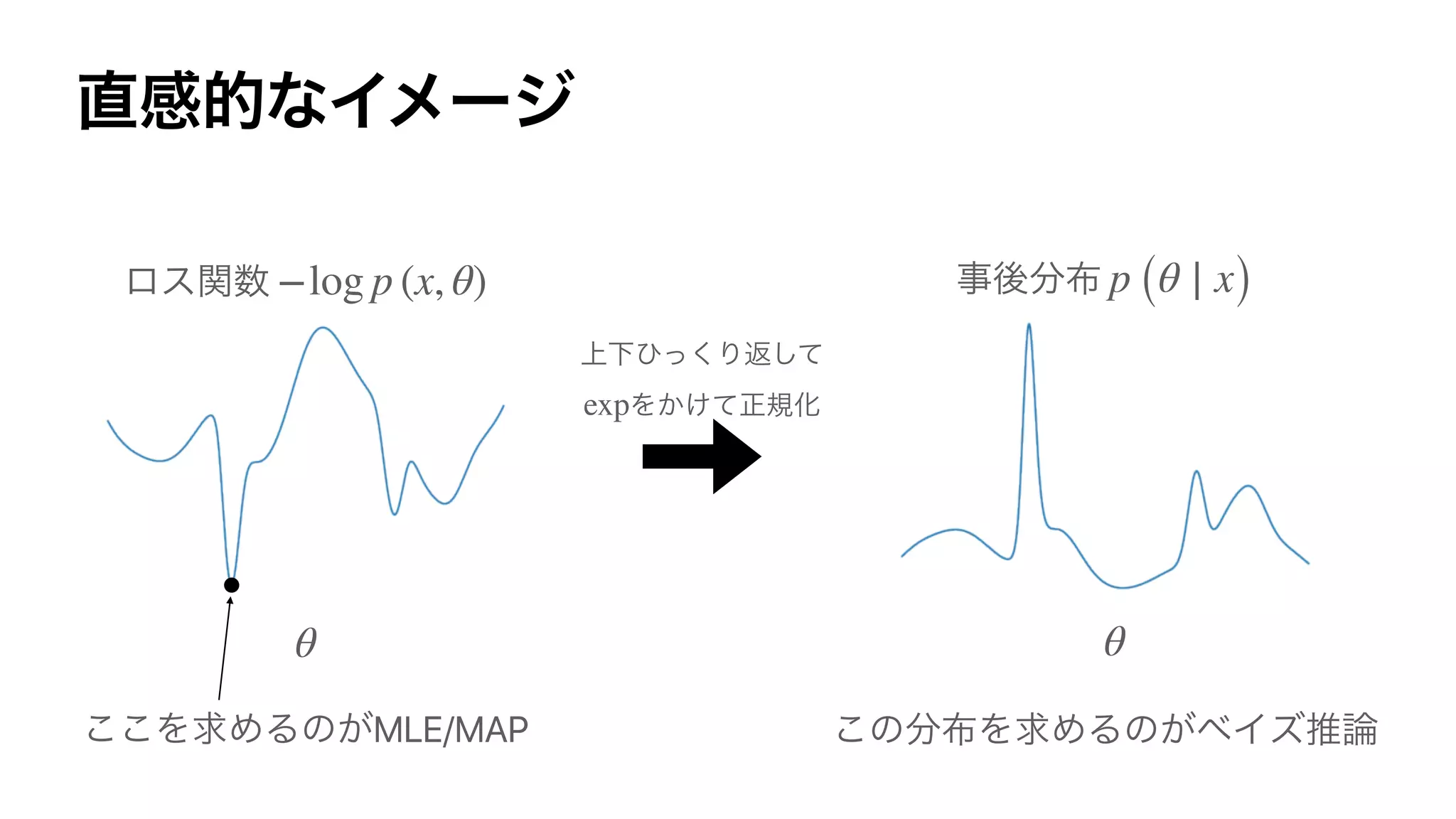






![Variational Inference
( )
KL (qϕ (θ) ∥ p (θ ∣ x)) =
∫
qϕ (θ) log
qϕ (θ)
p (θ ∣ x)
dΘ
= 𝔼qϕ
[
log
qϕ (θ)
p (x, θ) ]
+ log p (x)
log p (x) qϕ ℒϕ (x)
ℒϕ (x) ℒϕ (x) ≤ log p (x)
−ℒϕ (x)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-33-2048.jpg)
![Reparameterization Gradient
ℒϕ (x) ϕ
qϕ
∇ϕℒϕ (x) = − ∇ϕ 𝔼qϕ
[
log
qϕ (θ)
p (x, θ) ]](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-34-2048.jpg)
![Reparameterization Gradient
qϕ (θ) = Normal
(
μϕ, diag (σ2
ϕ))
𝔼qϕ
[
log
qϕ (θ)
p (x, θ) ]
= 𝔼p(ϵ) log
qϕ (θ)
p (x, θ)
θ=f(ϵ, ϕ)
p (ϵ) = Normal (0, I), f (ϵ, ϕ) = μϕ + σϕ ⊙ ϵ](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-35-2048.jpg)
![Reparameterization Gradient
∇ϕ 𝔼qϕ
[
log
qϕ (θ)
p (x, θ) ]
= 𝔼p(ϵ) ∇ϕlog
qϕ (θ)
p (x, θ)
Θ=f(ϵ, ϕ)
≈
1
L
L
∑
l=1
∇ϕlog
qϕ (θ)
p (x, θ)
θ=f(ϵ(l), ϕ)
ϵ(1)
, ⋯, ϵ(L)
∼ p (ϵ)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-36-2048.jpg)


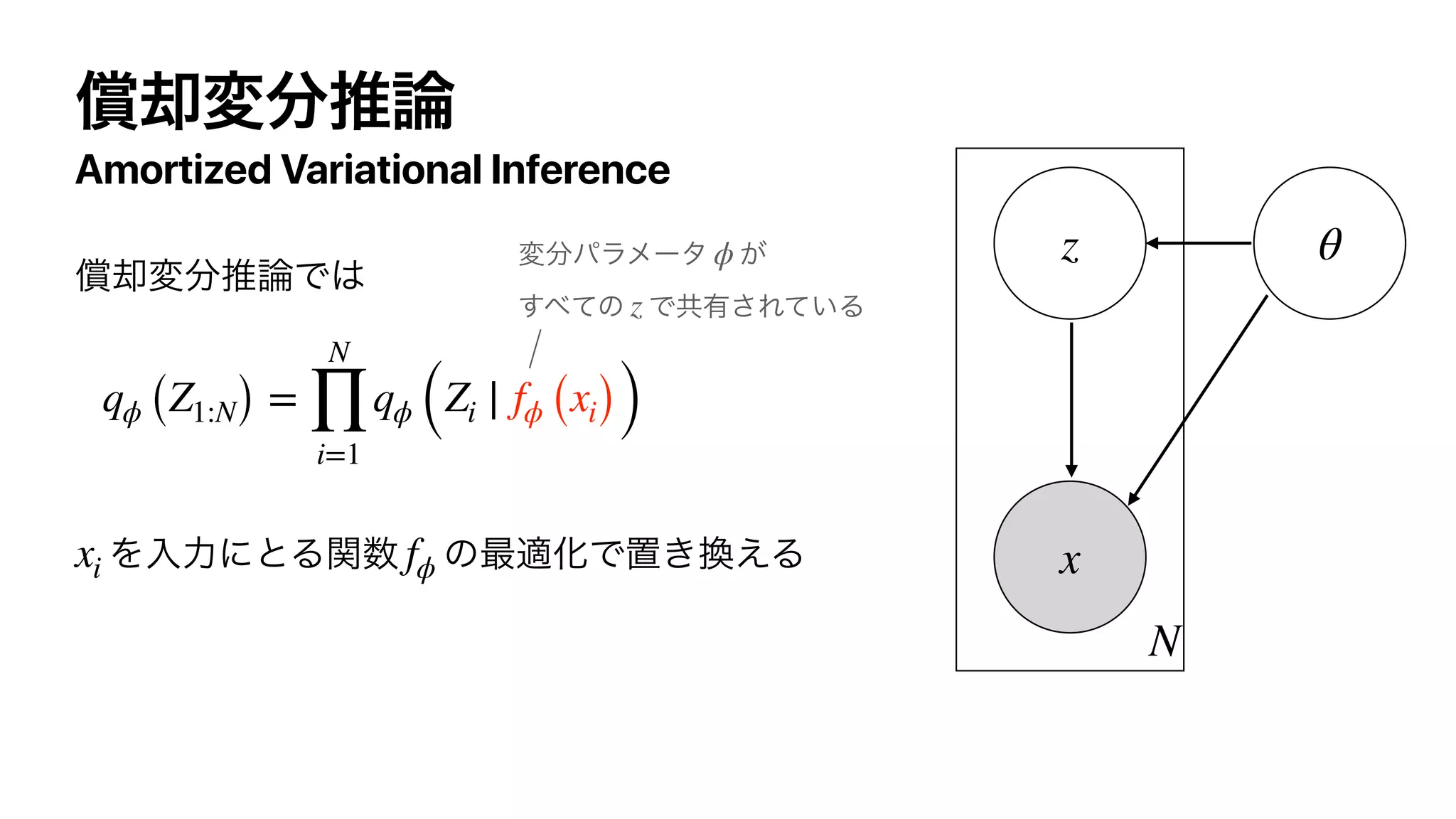
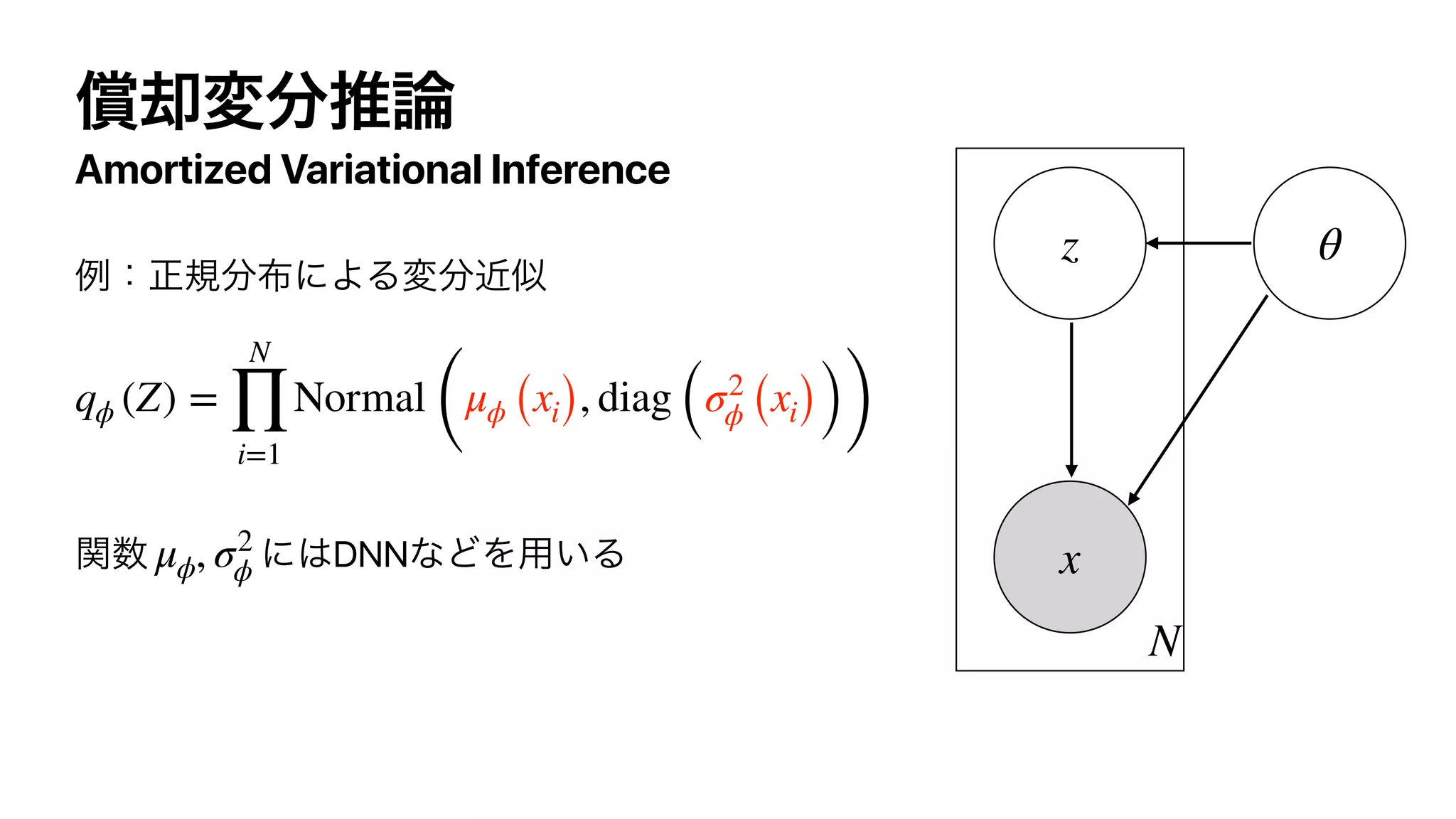
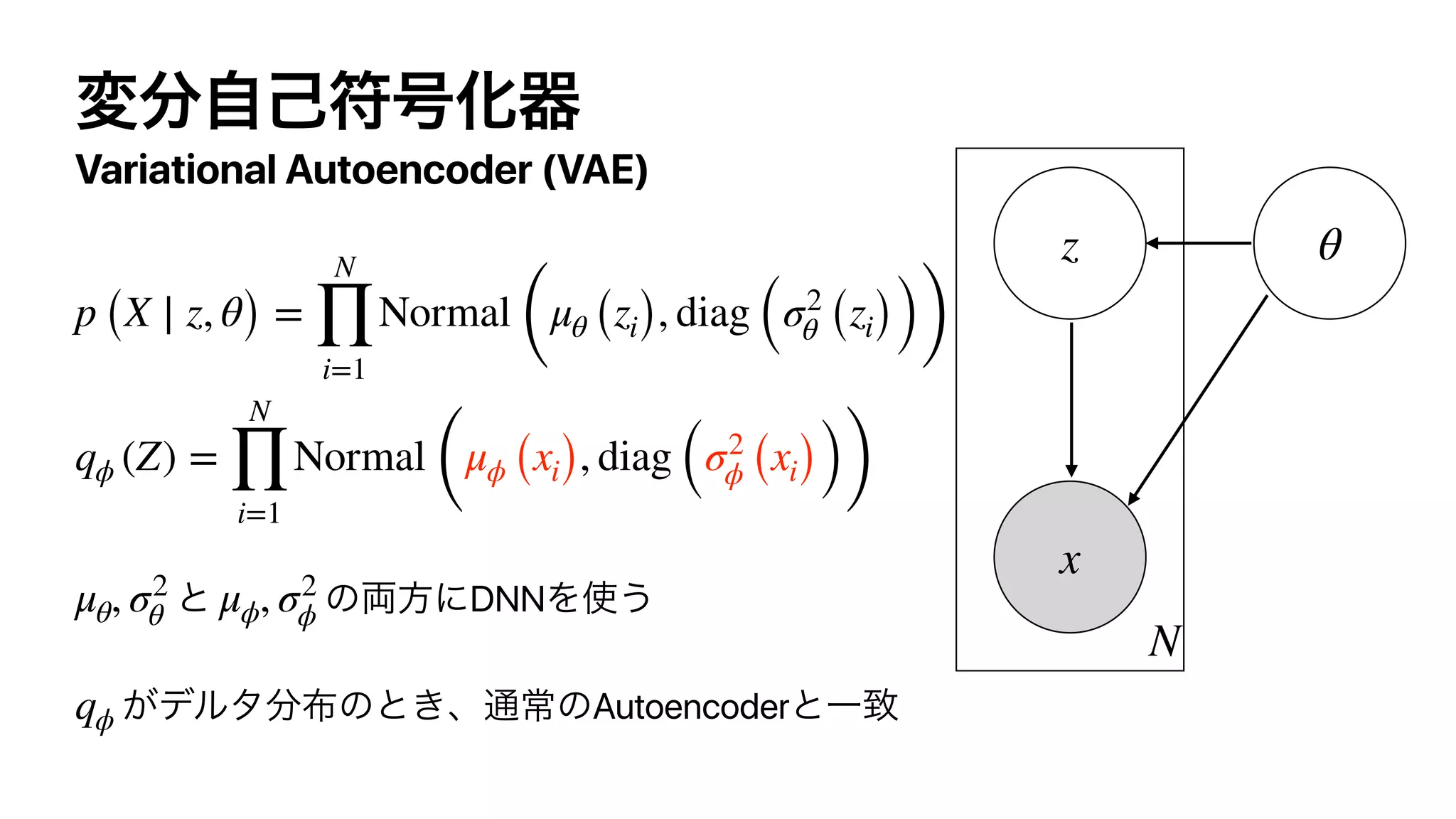











![Action-Value Function (Q-function)
st at π
Qπ
(st, at) = r (st, at) + 𝔼π
[
∞
∑
k=1
r (st+k, at+k)
]
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-55-2048.jpg)

![(State) Value Function
st π
Vπ
(st) = 𝔼π
[
∞
∑
k=0
r (st+k, at+k)
]
= 𝔼π [Qπ
(st, at)]
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-57-2048.jpg)

![Bellman Equation
Qπ
(st, at) = r (st, at) + Vπ
(st+1)
Vπ
(st) = 𝔼π [r (st, at)] + Vπ
(st+1)
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-59-2048.jpg)


![Q
Q-learning
(greedy )
Q (st, at) ← Q (st, at) + η
[
r (st, at) + max
a
Q (st+1, a) − Q (st, at)]
π (s) = argmax
a
Q (s, a)
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-62-2048.jpg)
![Q +
Q-learning + Function Approximation
(e.g., )
DNN (e.g., DQN)
Qθ
θ ← θ − η∇θ 𝔼
[
r (st, at) + max
a
Qθ (st+1, a) − Qθ (st, at)
2
]
Qθ
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-63-2048.jpg)

![Policy Gradient (REINFORCE)
θ
ϕ ← ϕ + η∇ϕ 𝔼πϕ
[
T
∑
t=1
r (st, at)
]
∇ϕ 𝔼πϕ
[
T
∑
t=1
r (st, at)
]
= 𝔼πϕ
[
T
∑
t=1
r (st, at)
T
∑
t=1
∇ϕlog πϕ (at ∣ st)
]
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-65-2048.jpg)
![Actor-Critic
Q
πϕ
θ
πϕ
ϕ ← ϕ + ηϕ ∇ϕ 𝔼πϕ [Q
πϕ
θ
(s, a)]
θ ← θ − ηθ ∇θ 𝔼
[
r (st, at) + V
πϕ
θ (st+1) − Q
πϕ
θ (st, at)
2]
V
πϕ
θ
(s) = 𝔼πϕ [Q
πϕ
θ
(s, a)]
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-66-2048.jpg)



![Soft Actor-Critic
Actor-Critic
ϕ ← ϕ + ηϕϕ
∇ϕ 𝔼πϕ [Q
πϕ
θ
(s, a)−log πϕ (a ∣ s)]
θ ← θ − ηθ ∇θ 𝔼
[
r (st, at) + V
πϕ
θ (st+1) − Q
πϕ
θ (st, at)
2]
V
πϕ
θ
(s) = 𝔼π [Q
πϕ
θ
(s, a)−log πϕ (at ∣ st)]
※
https://arxiv.org/abs/1801.01290](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-71-2048.jpg)
![Soft Actor-Critic
Actor-Critic
➡ Actor-Critic on-policy
πϕ 𝔼πϕ [Q
πϕ
θ (st, at)]
πϕ](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-72-2048.jpg)
![Soft Actor-Critic
SAC
KL divergence
➡ SAC off-policy
𝔼πϕ [Q
πϕ
θ
(s, a)−log πϕ (a ∣ s)]
πϕ ̂π (a ∣ s) ∝ exp (Qπ
ϕ (s, a))
KL (πϕ ∥ ̂π) = − 𝔼πϕ [Q
πϕ
θ
(s, a)−log πϕ (a ∣ s)] + log
∫
exp (Q
πϕ
θ
(s, a)) da](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-73-2048.jpg)








![Q* (st, at) = log p (o≥t ∣ st, at), V* (st) = log p (o≥t ∣ st)
Q* (st, at) = log p (ot ∣ st, at) + log p (o≥t+1 ∣ st, at)
= r (st, at) + log
∫
p (st+1 ∣ st, at) p (o≥t+1 ∣ st+1) dst+1
= r (st, at) + log 𝔼p(st+1 ∣ st, at) [
exp (V* (st+1))]
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-84-2048.jpg)
![i.e.,
Q* (st, at) = r (st, at) + log 𝔼p(st+1 ∣ st, at) [
exp (V* (st+1))]
p (st+1 ∣ st, at) = δ (st+1 − f (st, at))
Q* (st, at) = r (st, at) + V* (st+1)
V* (s) = log
∫
exp (Q* (s, a)) da ≠ max Q* (s, a)
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-85-2048.jpg)
![p (s1:T, a1:T ∣ o1:T) p (at ∣ st, o≥t)
Q* (st, at) = log p (o≥t ∣ st, at),
V* (st) = log p (o≥t ∣ st)
Q* (st, at) = r (st, at) + log 𝔼p(st+1 ∣ st, at) [
exp (V* (st+1))]
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-86-2048.jpg)




![KL divergenceqϕ (s1:T, a1:T) p (s1:T, a1:T ∣ o1:T)
KL (qϕ (s1:T, a1:T) ∥ p (s1:T, a1:T ∣ o1:T))
= 𝔼qϕ
[
log
qϕ (s1:T, a1:T)
p (s1:T, a1:T ∣ o1:T) ]
= 𝔼qϕ
[
T
∑
t=1
log πϕ (at ∣ st) − r (st, at)
]
+ log p (o1:T)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-91-2048.jpg)
![∇ϕ 𝔼qϕ
[
T
∑
t=1
r (st, at)
]
= 𝔼qϕ
[
T
∑
t=1
r (st, at)∇ϕlog qϕ (s1:T, a1:T)
]
= 𝔼qϕ
[
T
∑
t=1
r (st, at)
T
∑
t=1
∇ϕlog πϕ (at ∣ st)
]](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-92-2048.jpg)
![➡
𝔼qϕ
[
T
∑
t=1
log πϕ (at ∣ st) − r (st, at)
]](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-93-2048.jpg)





![KL divergenceπϕ (at ∣ st) p (at ∣ st, o≥t)
KL (πϕ (at ∣ st) ∥ p (at ∣ st, o≥t))
= 𝔼πϕ
[
log
πϕ (at ∣ st)
p (at ∣ st, o≥t)]
= 𝔼πϕ [log πϕ (at ∣ st) − Q* (st, at)] + V* (st)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-99-2048.jpg)
![KL (πϕ (at ∣ st) ∥ p (at ∣ st, o≥t))
= 𝔼πϕ [log πϕ (at ∣ st)−Q* (st, at)] + V* (st)
Q* (st, at)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-100-2048.jpg)
![Q* (st, at) = r (st, at) + log 𝔼p(st+1 ∣ st, at) [
exp (V* (st+1))]
V* (s) = log
∫
exp (Q* (s, a)) da
V*
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-101-2048.jpg)
![1.
Soft Q-learning
V* (s) = log 𝔼πϕ
[
exp (Q* (s, a))
πϕ (a ∣ s) ]
≈ log
1
L
L
∑
l=1
exp (Q* (s, a(l)
))
πϕ (a(l) ∣ s)
a1, …aL ∼ πϕ (a ∣ s)
L → ∞ V* (s)
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-102-2048.jpg)
![2.
Q* (st, at) = r (st, at) + log 𝔼p(st+1 ∣ st, at) [
exp (V* (st+1))]
≥ r (st, at) + log 𝔼p(st+1 ∣ st, at) [
exp (Vπϕ
(st+1))]
= Qπϕ
(st, at)
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-103-2048.jpg)
![2.
V*(s) = log 𝔼πϕ
[
exp (Q*(s, a))
πϕ(a ∣ s) ]
≥ 𝔼πϕ [Q*(s, a) − log πϕ(a ∣ s)]
≥ 𝔼πϕ [Qπϕ(s, a) − log πϕ(a ∣ s)]
= Vπϕ(s)
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-104-2048.jpg)

![Qπϕ Q
πϕ
θ
θ ← θ − ηθ ∇θ 𝔼
[
r (st, at) + V
πϕ
θ (st+1) − Q
πϕ
θ (st, at)
2]
V
πϕ
θ
(s) = 𝔼πϕ [Q
πϕ
θ
(s, a) − log πϕ (a ∣ s)]
V
πϕ
θ
πϕ
※](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-106-2048.jpg)
![Soft Actor-Critic
πϕ (at, st) ̂π (a ∣ s) ∝ exp (Q
πϕ
θ
(s, a))
KL (πϕ (at ∣ st) ∥ ̂π (at ∣ st))
= 𝔼πϕ [log πϕ (at ∣ st) − Q
πϕ
θ (st, at)] + log
∫
exp (Q
πϕ
θ
(s, a)) da](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-107-2048.jpg)







![KL divergence
KL (qϕ (s≤t, at ∣ x≤t, a<t) ∥ p (s≤t, at ∣ x≤t, a<t, o≥t))
= 𝔼qϕ
[
log
qϕ (s≤t, at ∣ x≤t, a<t)
p (s≤t, at ∣ x≤t, a<t, o≥t)]
= 𝔼qϕ
[
log πϕ (at ∣ st) + log
qϕ (s1 ∣ x1)
p (x1, s1)
+
t
∑
τ=1
log
qϕ (sτ+1 ∣ xτ+1, sτ, aτ)
p (xτ+1, sτ+1 ∣ sτ, aτ)
− Q* (st, at)
]
+log p (x≤t ∣ a<t) + V* (st)
−ℒϕ (x≤t, a<t, o≥t)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-118-2048.jpg)
![KL divergence
KL (qϕ (s≤t, at ∣ x≤t, a<t) ∥ p (s≤t, at ∣ x≤t, a<t, o≥t))
= 𝔼qϕ
[
log
qϕ (s≤t, at ∣ x≤t, a<t)
p (s≤t, at ∣ x≤t, a<t, o≥t)]
= 𝔼qϕ
[
log πϕ (at ∣ st) + log
qϕ (s1 ∣ x1)
p (x1, s1)
+
t
∑
τ=1
log
qϕ (sτ+1 ∣ xτ+1, sτ, aτ)
p (xτ+1, sτ+1 ∣ sτ, aτ)
− Q* (st, at)
]
+log p (x≤t ∣ a<t) + V* (st)
−ℒϕ (x≤t, a<t, o≥t)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-119-2048.jpg)
![KL divergence
KL (qϕ (s≤t, at ∣ x≤t, a<t) ∥ pψ (s≤t, at ∣ x≤t, a<t, o≥t))
= 𝔼qϕ
[
log
qϕ (s≤t, at ∣ x≤t, a<t)
pψ (s≤t, at ∣ x≤t, a<t, o≥t) ]
= 𝔼qϕ
[
log πϕ (at ∣ st) + log
qϕ (s1 ∣ x1)
pψ (x1, s1)
+
t
∑
τ=1
log
qϕ (sτ+1 ∣ xτ+1, sτ, aτ)
pψ (xτ+1, sτ+1 ∣ sτ, aτ)
− Q* (st, at)
]
+log pψ (x≤t ∣ a<t) + V* (st)
➡
−ℒϕ,ψ (x≤t, a<t, o≥t)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-120-2048.jpg)


![SAC
Q* (st, at) ≥ r (st, at) + log 𝔼p(st+1 ∣ st, at) [
exp (Vπϕ
(st+1))]
= Qπϕ
(st, at) ≈ Q
πϕ
θ (st, at)
V*(s) ≥ 𝔼πϕ [Qπϕ(s, a) − log πϕ(a ∣ s)]
= Vπϕ(s) ≈ V
πϕ
θ
(s)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-123-2048.jpg)
![Stochastic Latent Actor-Critic (SLAC)
̂θ = argmin 𝔼
[
r (st, at) + V
πϕ
θ (st+1) − Q
πϕ
θ (st, at)
2]
̂ϕ, ̂ψ = argmax
ϕ,ψ
ℒϕ,ψ (x≤t, a<t, o≥t)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-124-2048.jpg)









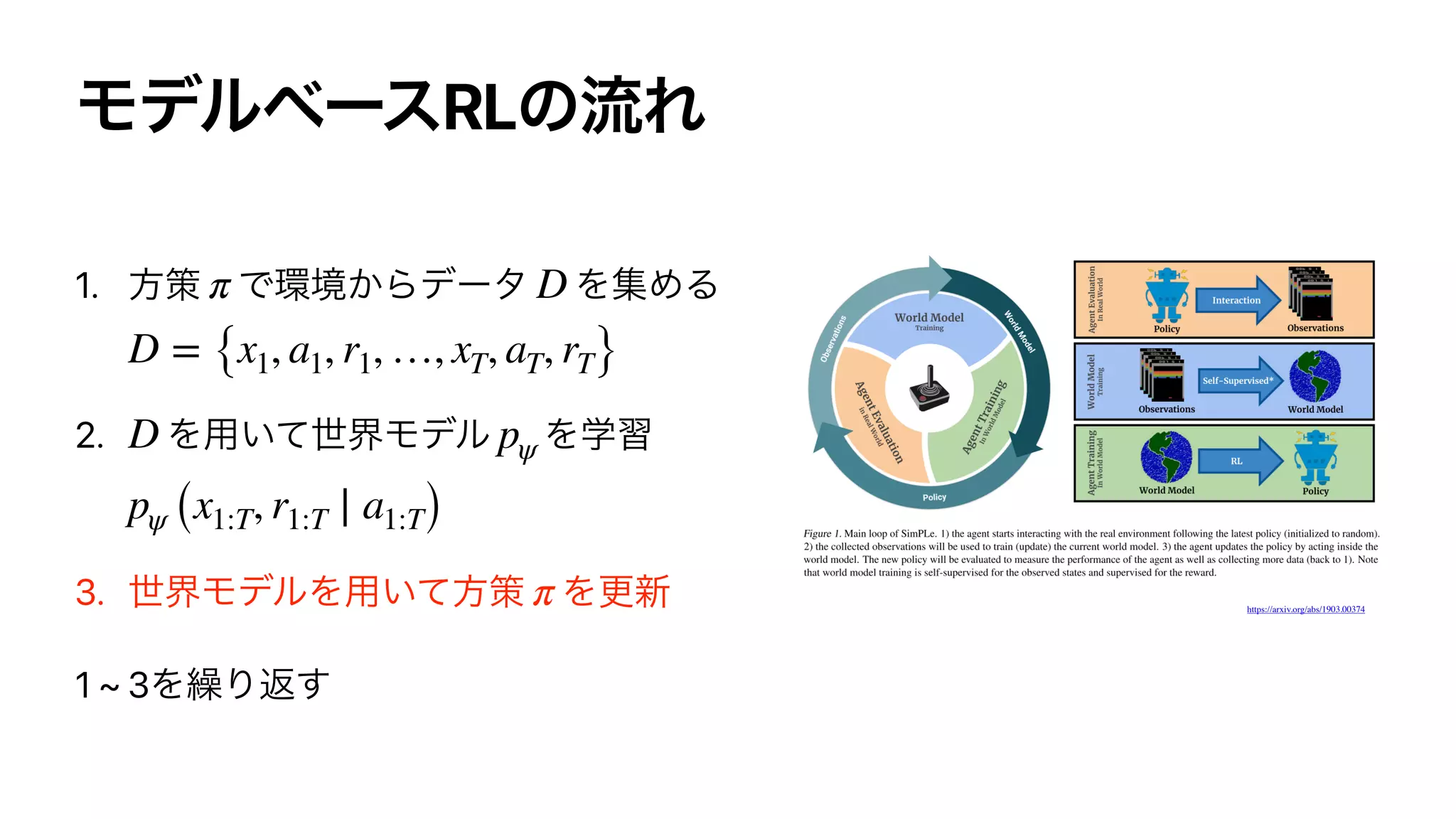
![log pψ (x1:T, r1:T ∣ a1:T)
= log
∫
p (s1)
T
∏
t=1
pψ (st+1 ∣ st, at) pψ (rt ∣ st, at) pψ (xt ∣ st) ds1:T
= log 𝔼qϕ
[
pψ (s1)
qϕ (s1 ∣ x1)
T
∏
t=1
pψ (st+1 ∣ st, at) pψ (rt ∣ st, at) pψ (xt ∣ st)
qϕ (st+1 ∣ xt+1, rt, st, at) ]
≥ 𝔼qϕ
[
log
pψ (s1)
qϕ (s1 ∣ x1)
+
T
∑
t=1
log
pψ (st+1 ∣ st, at) pψ (rt ∣ st, at) pψ (xt ∣ st)
qϕ (st+1 ∣ xt+1, rt, st, at) ]
= ℒϕ,ψ (x1:T, r1:T, a1:T)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-137-2048.jpg)



![1. (Model Predictive Control,MPC)
1.
2.
3.
a(1)
t:T
, a(2)
t:T
, ⋯, a(K)
t:T
R (a(k)
t:T ) = 𝔼pψ
[
T
∑
τ=t
rψ (sτ, a(k)
τ )]
at = a
̂k
t
(
̂k = argmax
k
R (a(k)
t:T ))](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-142-2048.jpg)

![2.
ϕ ← ϕ + η∇ϕ 𝔼pψ,πϕ
[
T
∑
t=1
rψ (st, at)
]](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-144-2048.jpg)
![2.
rψ
∇ϕ 𝔼pψ,πϕ
[
T
∑
t=1
rψ (st, at)
]
= 𝔼p(ϵ)
[
T
∑
t=1
∇ϕrψ (st = fψ (st−1, at−1, ϵ), at = fϕ (st, ϵ))]](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-145-2048.jpg)
![2.
∇ϕ 𝔼pψ,πϕ
[
T
∑
t=1
rψ (st, at)
]
= 𝔼pψ,πϕ
[
T
∑
t=1
rψ (st, at)
T
∑
t=1
∇ϕlog πϕ (at ∣ st)
]](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-146-2048.jpg)
![3.Actor-Critic
ϕ ← ϕ + ηϕ ∇ϕ 𝔼pψ,πϕ [V
πϕ
θ
(s)]
θ ← θ − ηθ ∇θ 𝔼pψ,πϕ [
rψ (st, at) + V
πϕ
θ (st+1) − Q
πϕ
θ (st, at)
2]
V
πϕ
θ
(s) = 𝔼πϕ [Q
πϕ
θ
(s, a)]](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-147-2048.jpg)

![World Models
[Ha and Schmidhuber,2018]
VAE + MDN-RNN
CMA-ES
https://www.slideshare.net/masa_s/ss-97848402
https://arxiv.org/abs/1803.10122
https://worldmodels.github.io/](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-149-2048.jpg)
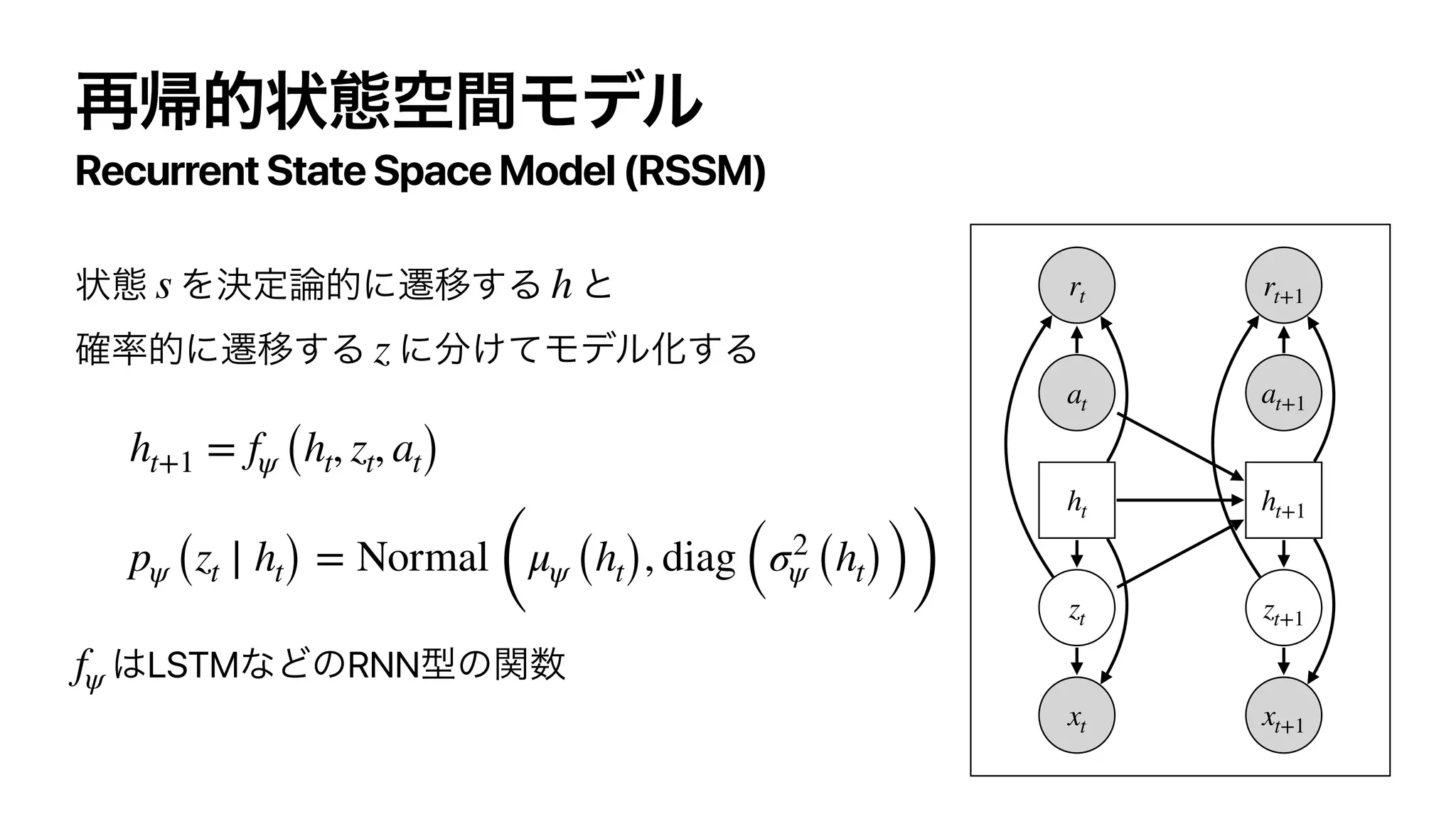
![[Hafner,et al.,2019]
Recurrent State Space Model ( )
CEM
PlaNet
DM Control Suite
https://arxiv.org/abs/1811.04551
https://planetrl.github.io/](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-150-2048.jpg)
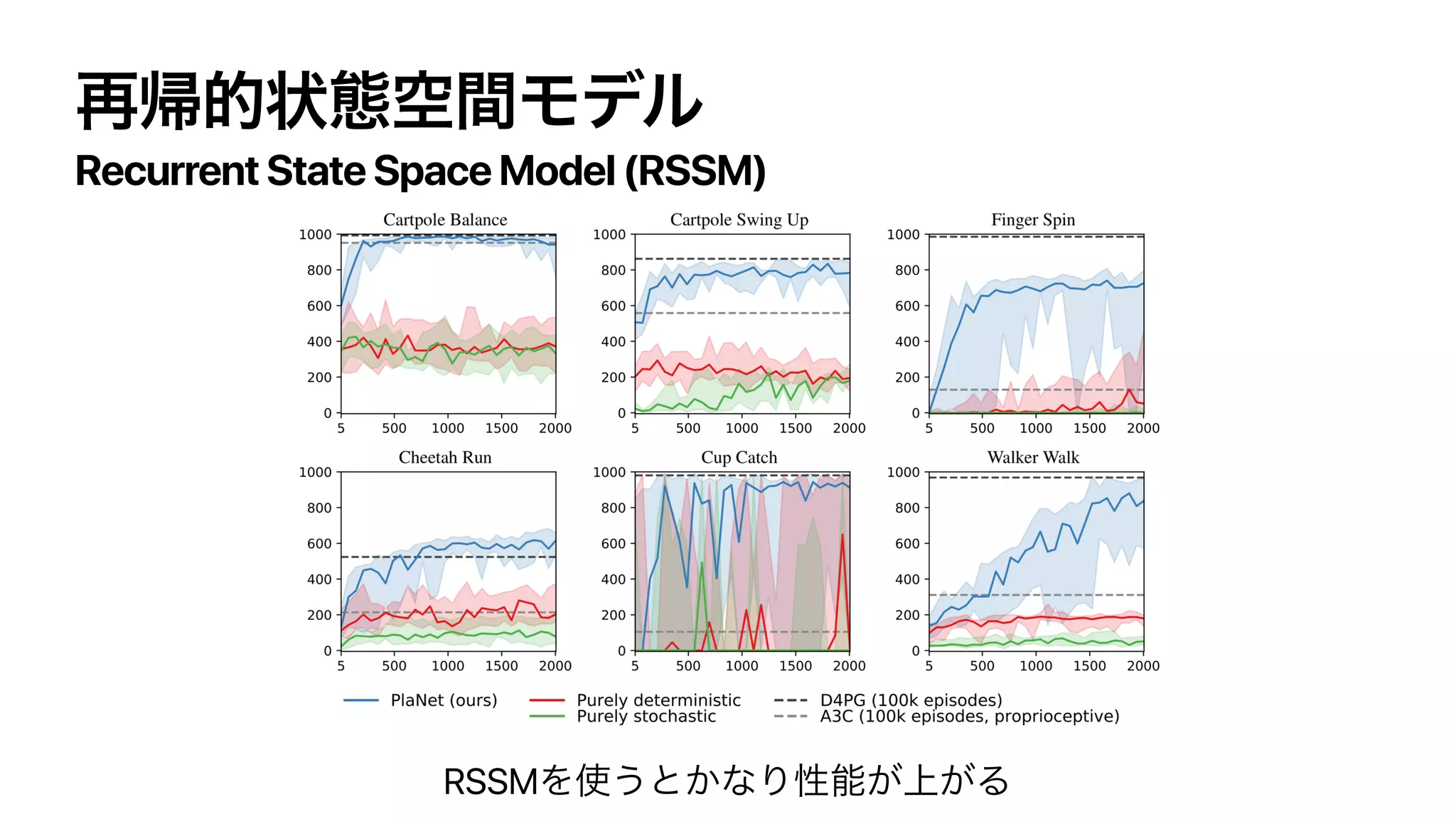
![[Hafner,et al.,2019]
PlaNet
Actor-Critic
( )
PlaNet
λ
Dreamer
https://arxiv.org/abs/1912.01603
https://ai.googleblog.com/2020/03/introducing-dreamer-scalable.html](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-154-2048.jpg)
![Vπ
(st) = 𝔼π [r (st, at)] + Vπ
(st+1)
n
Vπ
n (st) = 𝔼π
[
n−1
∑
k=1
r (st+k, at+k)
]
+ Vπ
(st+n)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-155-2048.jpg)
![2
Vπ
n (st) = 𝔼π
[
n−1
∑
k=1
r (st+k, at+k)
]
+ Vπ
(st+n)
n = 1,…, ∞
¯Vπ
(st, λ) = (1 − λ)
∞
∑
n=1
λn−1
Vπ
n (st)
λ](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-156-2048.jpg)
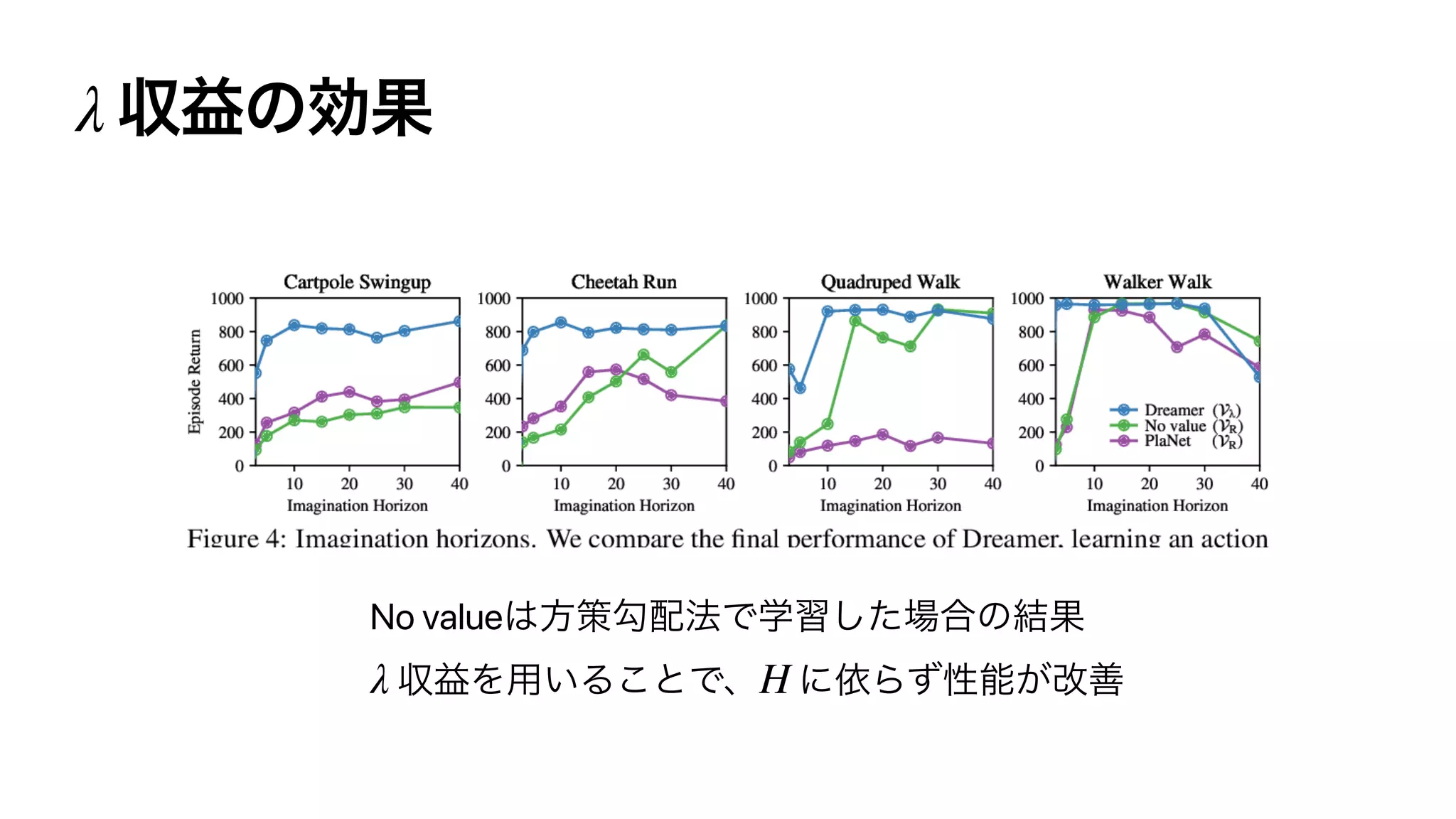
![Dreamer λ
θ ← θ − ηθ ∇θ 𝔼pψ,πϕ [
V
πϕ
θ (st) − ¯Vπ
(st, λ)
2]
H
¯Vπ
(st, λ) ≈ (1 − λ)
H−1
∑
n=1
λn−1
Vπ
n (st) + λH−1
Vπ
H (st)](https://image.slidesharecdn.com/rlss5slideshare-200829051309/75/Control-as-Inference-157-2048.jpg)






![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
