Download as PDF, PPTX


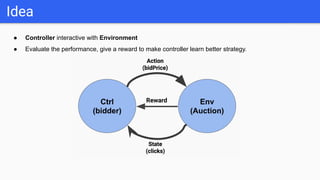



















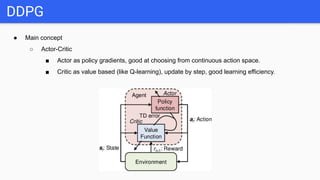
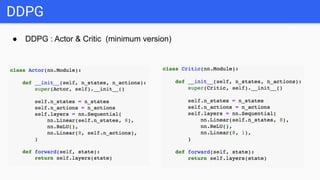


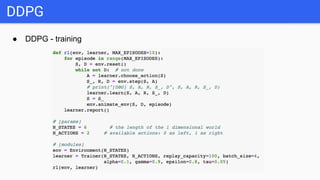




This document introduces several reinforcement learning frameworks: Q-learning uses a table to store state-action values and learns by updating the table based on rewards. Policy gradient directly learns the policy's parameters by maximizing expected rewards. Deep Q-learning uses neural networks to generalize across large state spaces. Deep deterministic policy gradient combines value-based and policy-based methods, using actor-critic networks for continuous control tasks. Code examples demonstrate Q-learning, policy gradient, deep Q-learning and DDPG algorithms.




































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
















