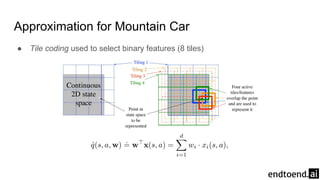
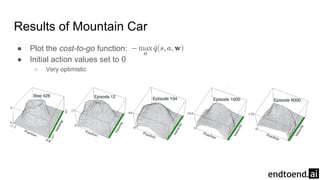
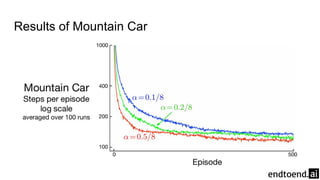
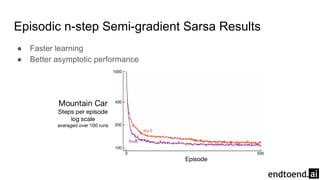
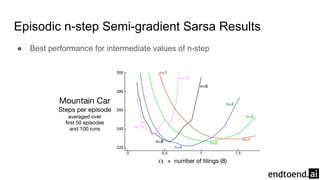
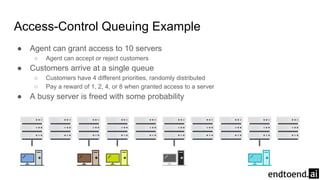
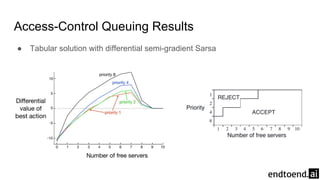
The document discusses on-policy control using approximate action values in reinforcement learning, focusing on episodic 1-step and n-step semi-gradient Sarsa methods. It details the application of these methods to the mountain car problem and an access-control queuing example, highlighting the benefits of using n-step updates for faster learning and better performance. Various techniques such as tile coding and differential return are introduced to enhance policy quality and learning efficiency.