Downloaded 11 times






This document discusses Deep Deterministic Policy Gradient (DDPG), a reinforcement learning algorithm for problems with continuous state and action spaces. DDPG uses an actor-critic method with experience replay and soft target updates to learn a policy in an off-policy manner. It demonstrates how DDPG can be used to train an agent to drive a vehicle in a simulator by designing a reward function, but notes that designing effective rewards, avoiding local optima, instability, and data requirements are challenges for DDPG.
Introduces Deep Deterministic Policy Gradient (DDPG), a method in reinforcement learning.
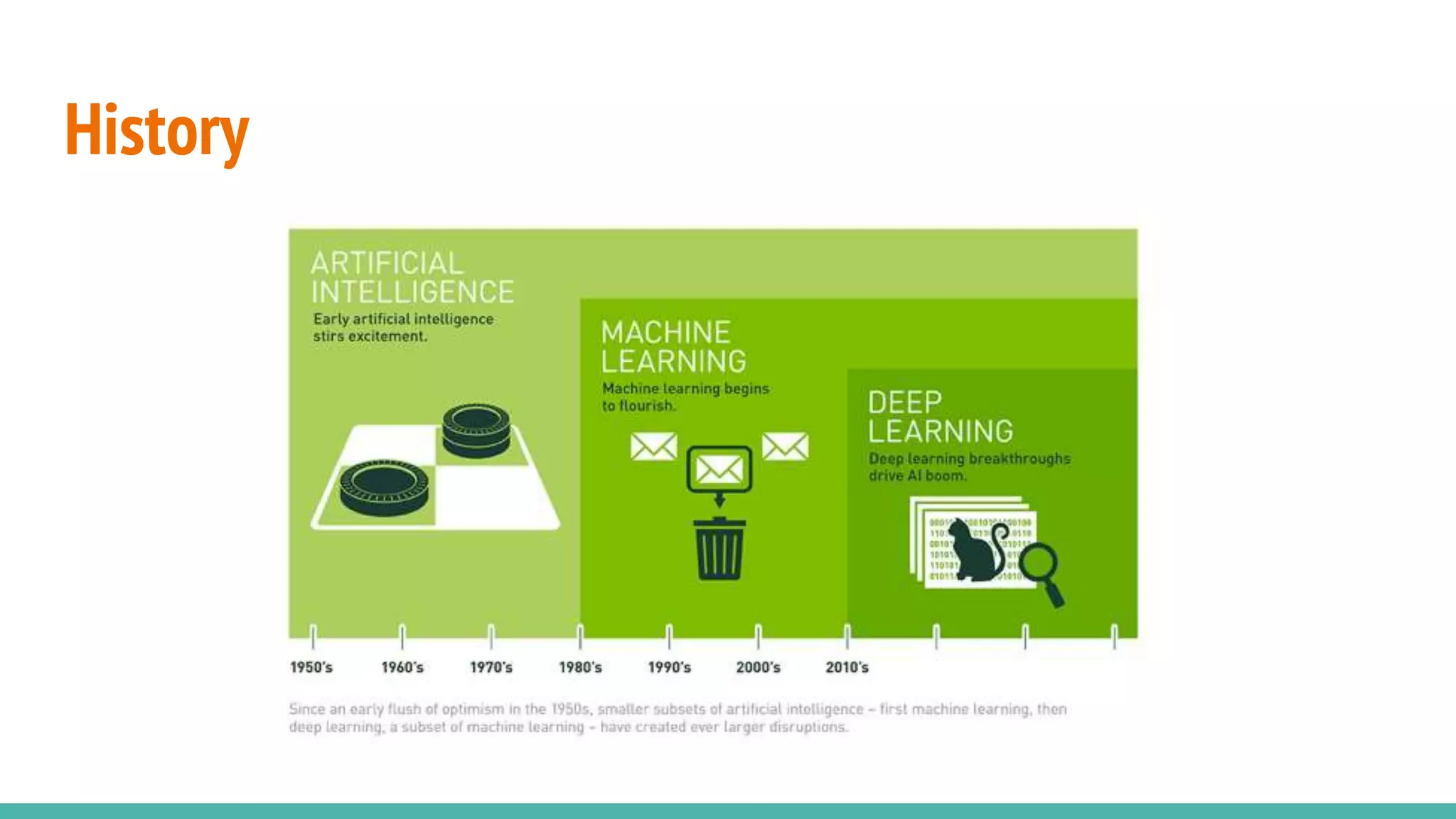
Discusses the historical background of reinforcement learning methods.
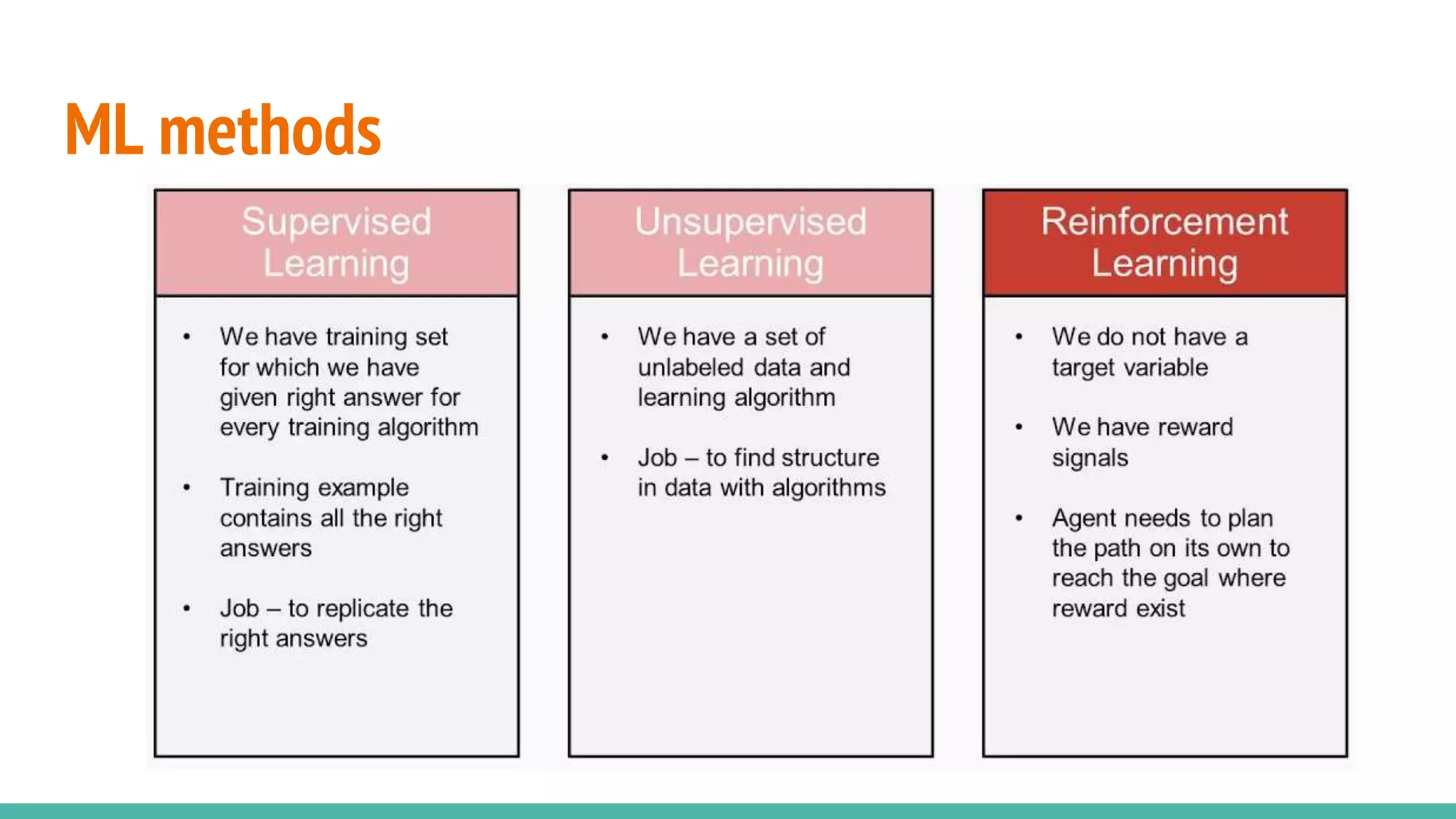
Covers various machine learning methods relevant to DDPG and its application.
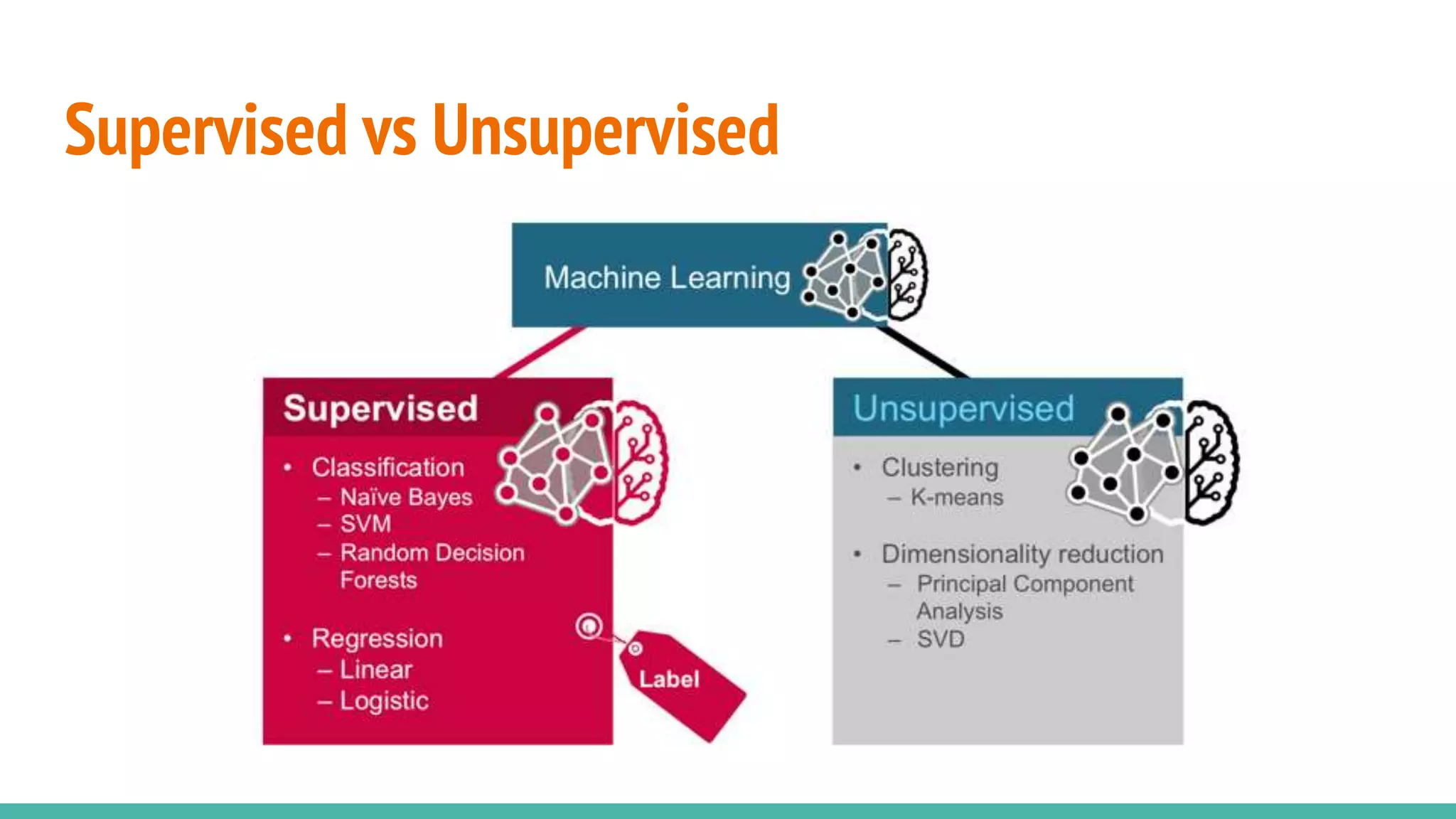
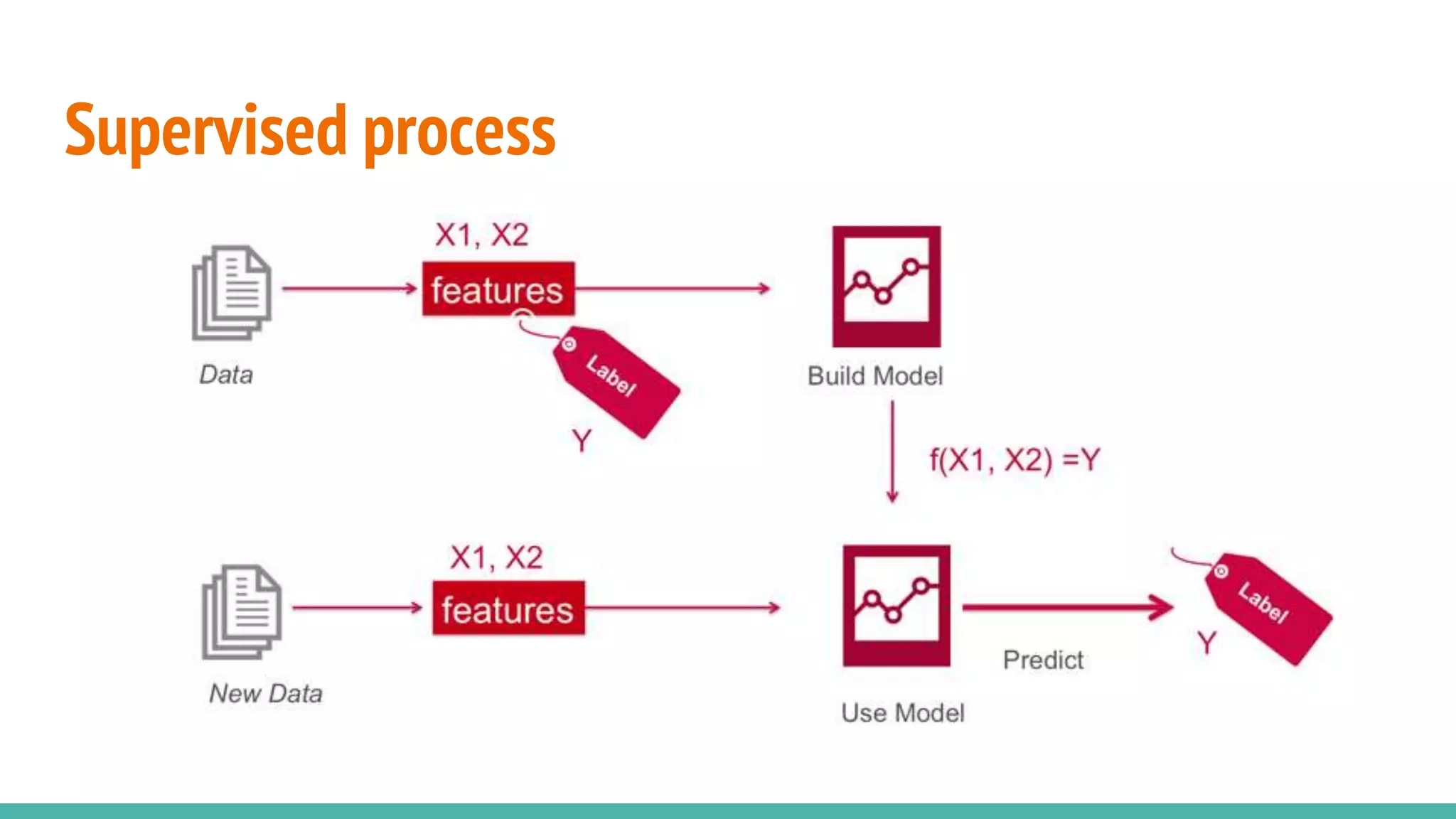
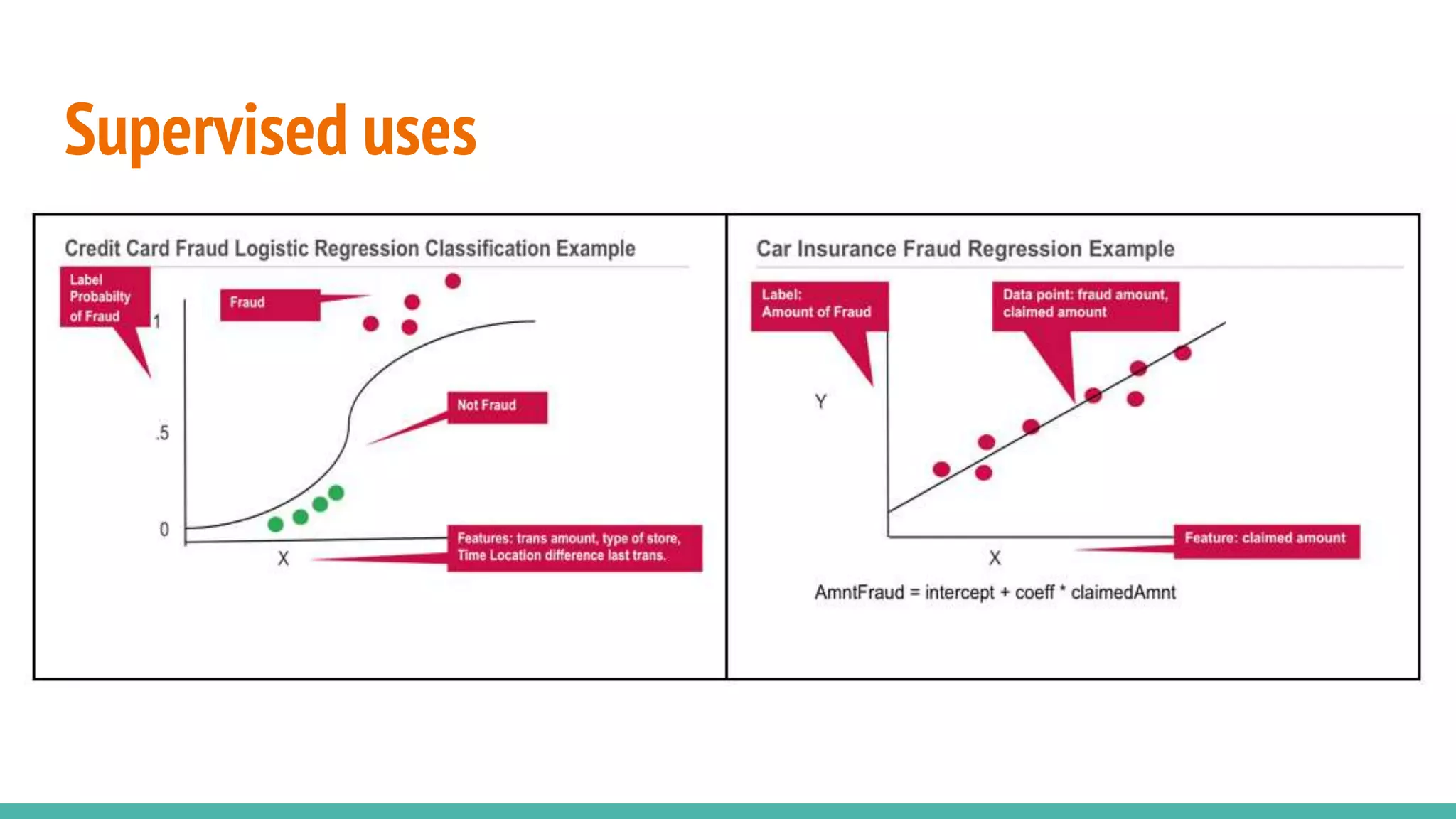
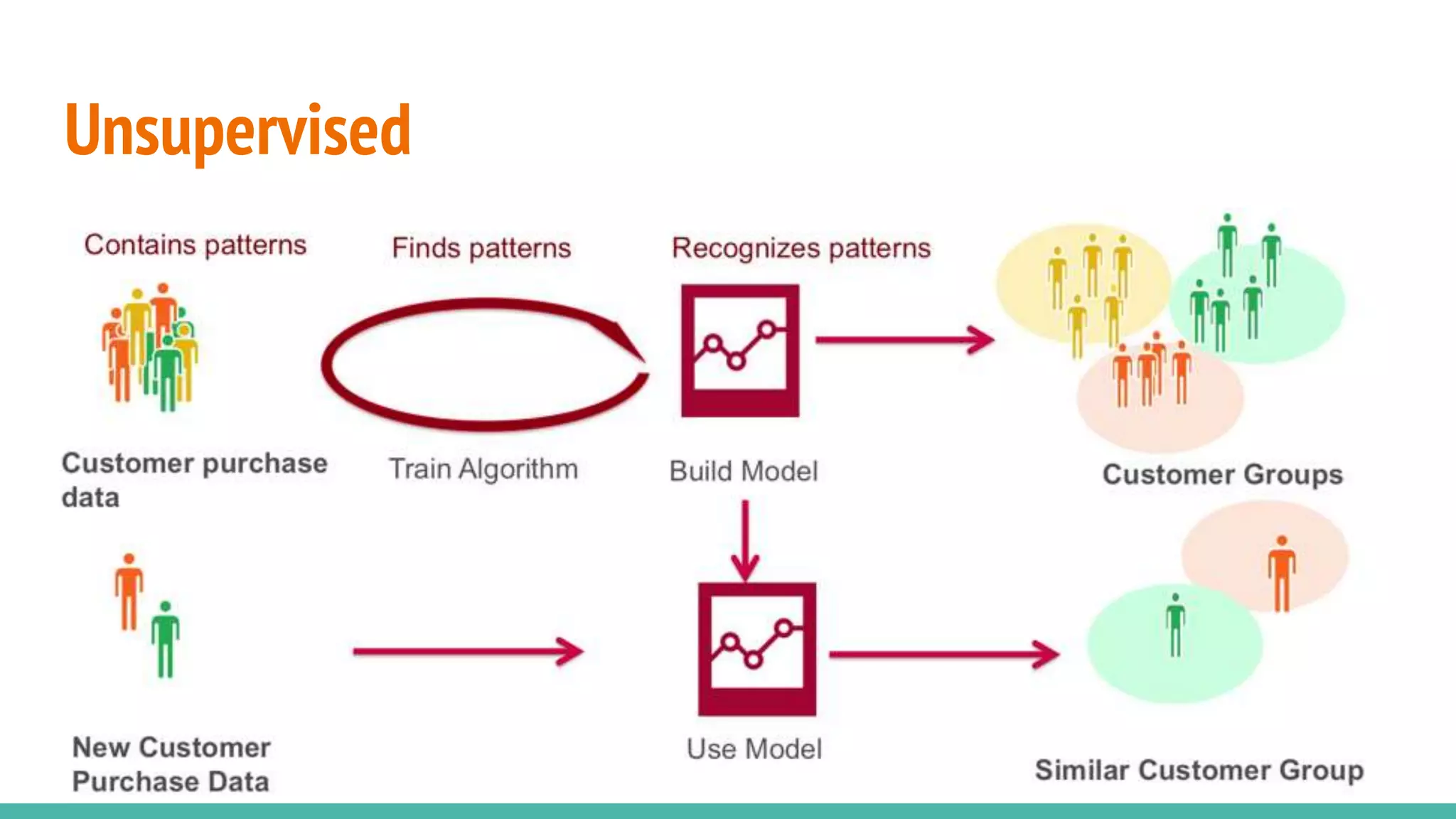
Differentiates between supervised and unsupervised learning approaches in machine learning.
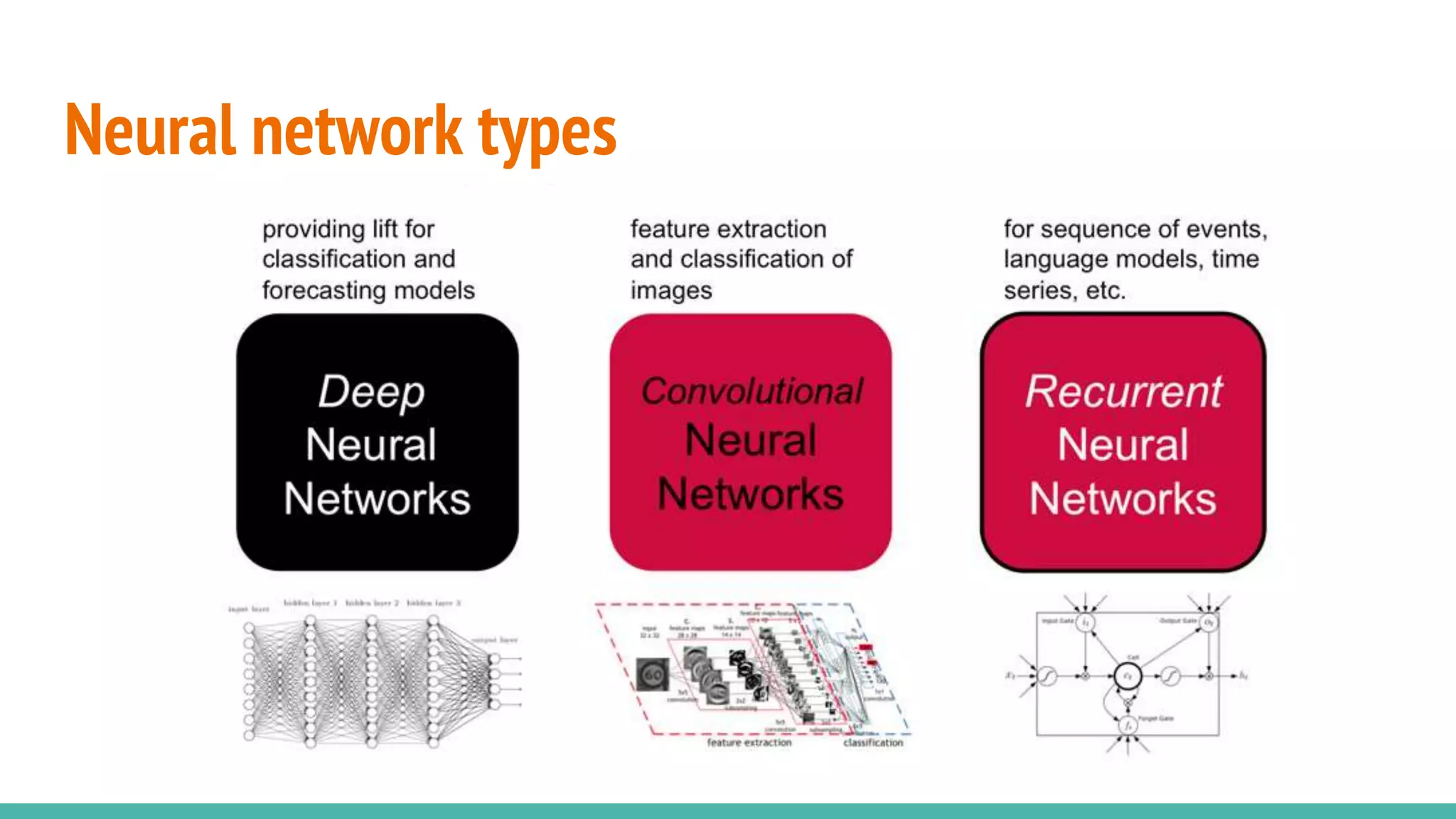
Explores different types of neural networks and their functions in learning models.
Discusses the gradient descent optimization method used in training models.
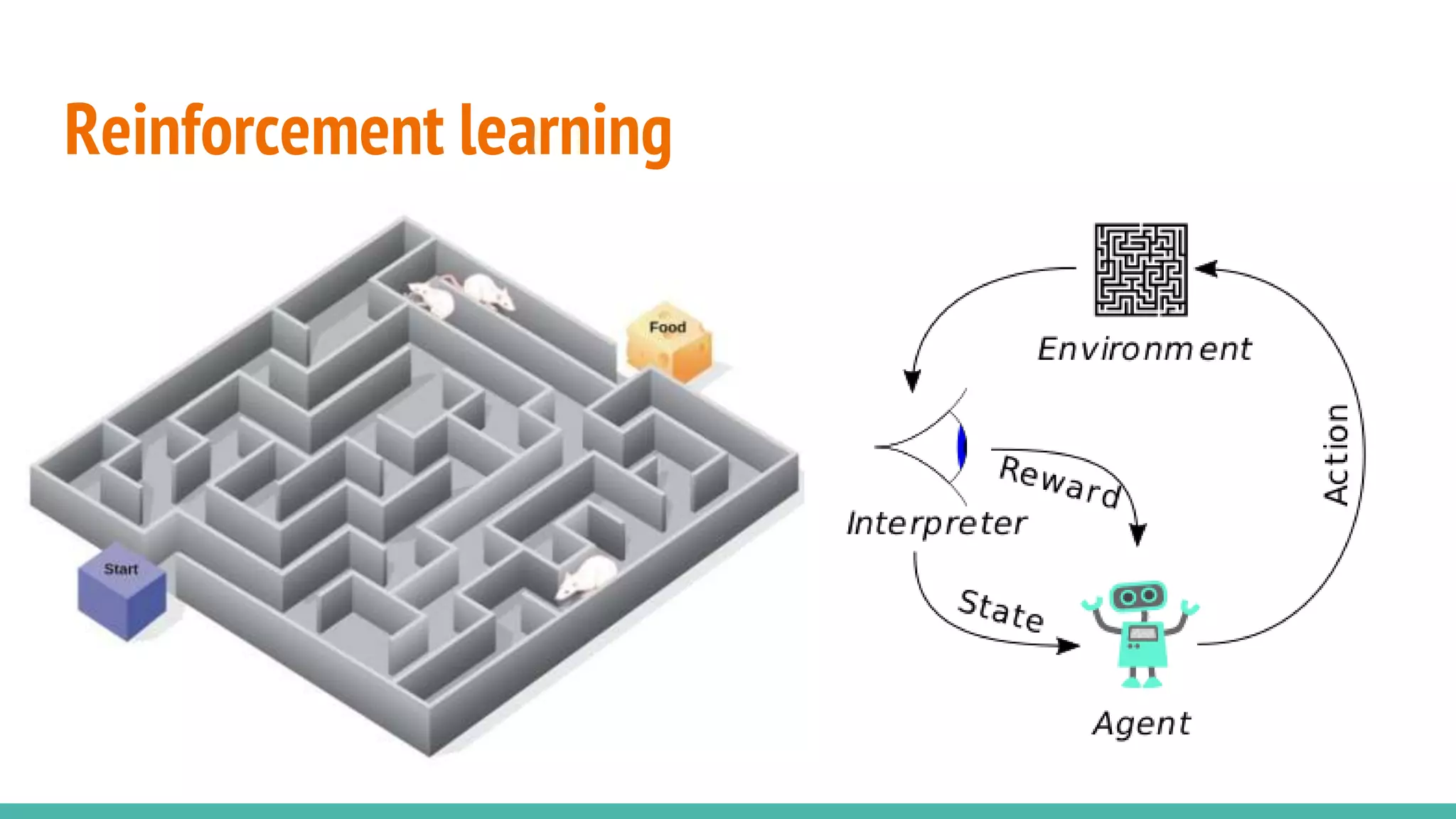
Introduces key concepts of reinforcement learning, setting the stage for advanced discussions.
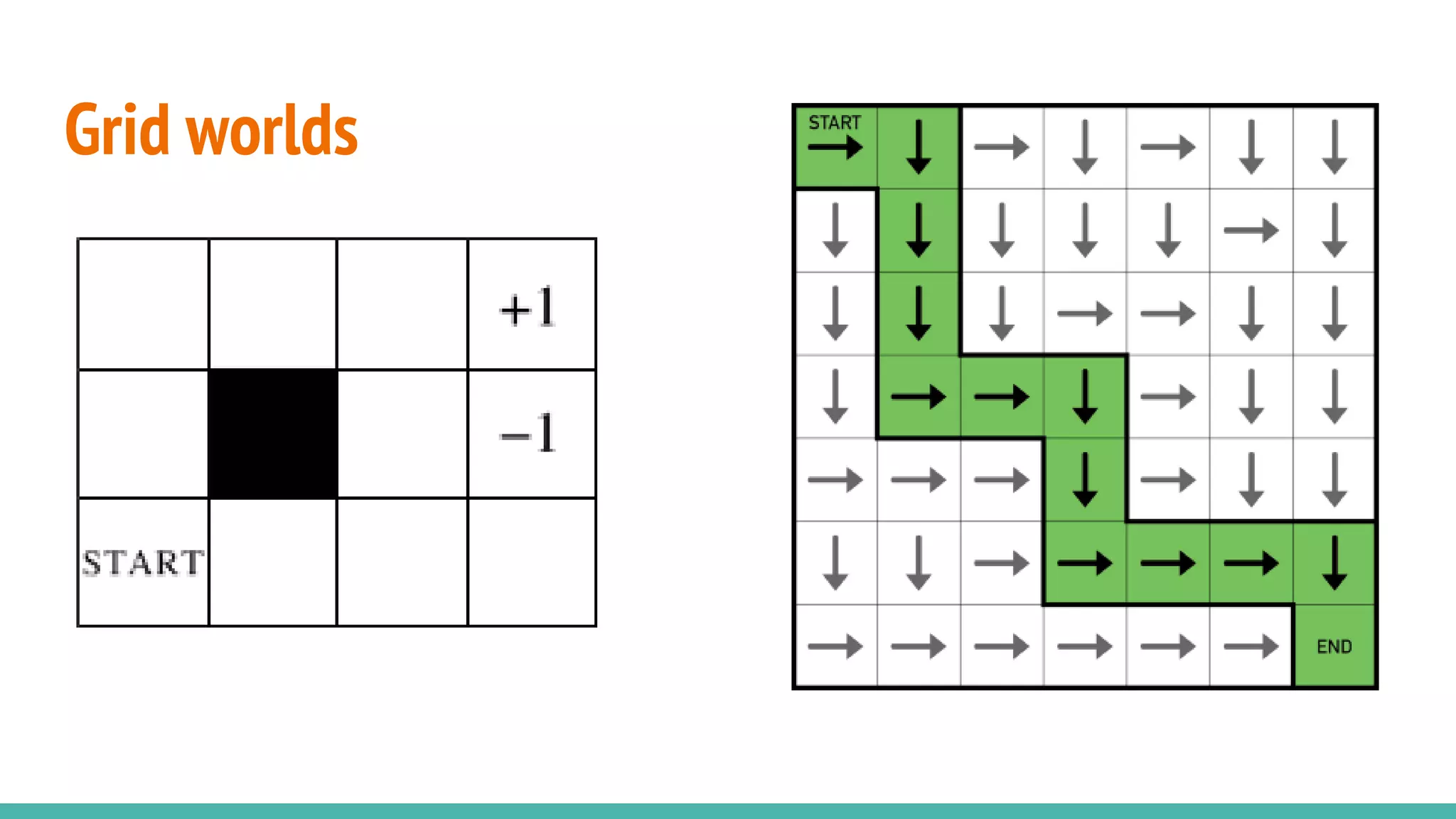
Discusses the concept of grid worlds as environments used in reinforcement learning.
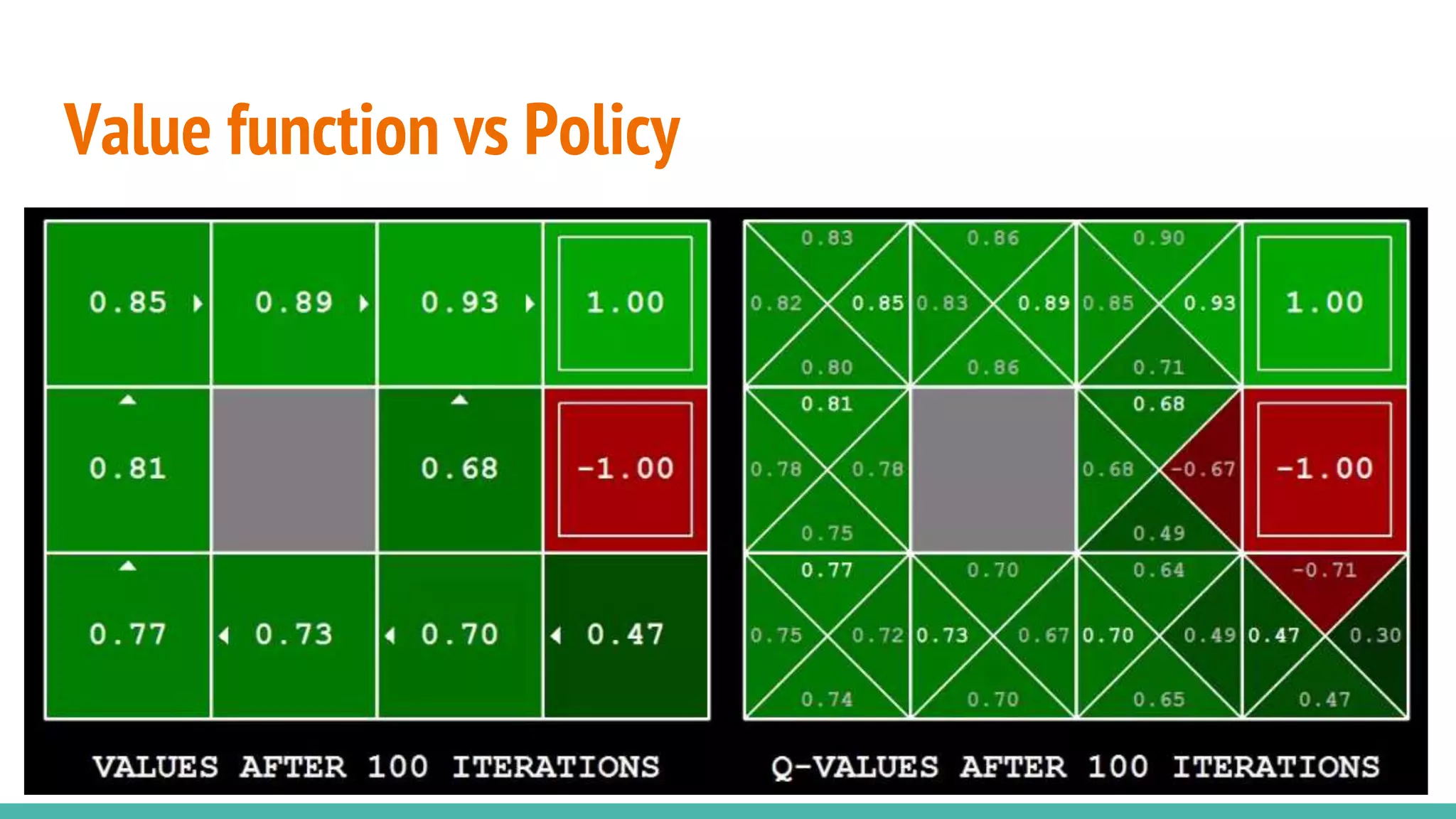
Explains the distinction and relationship between value functions and policies in RL.
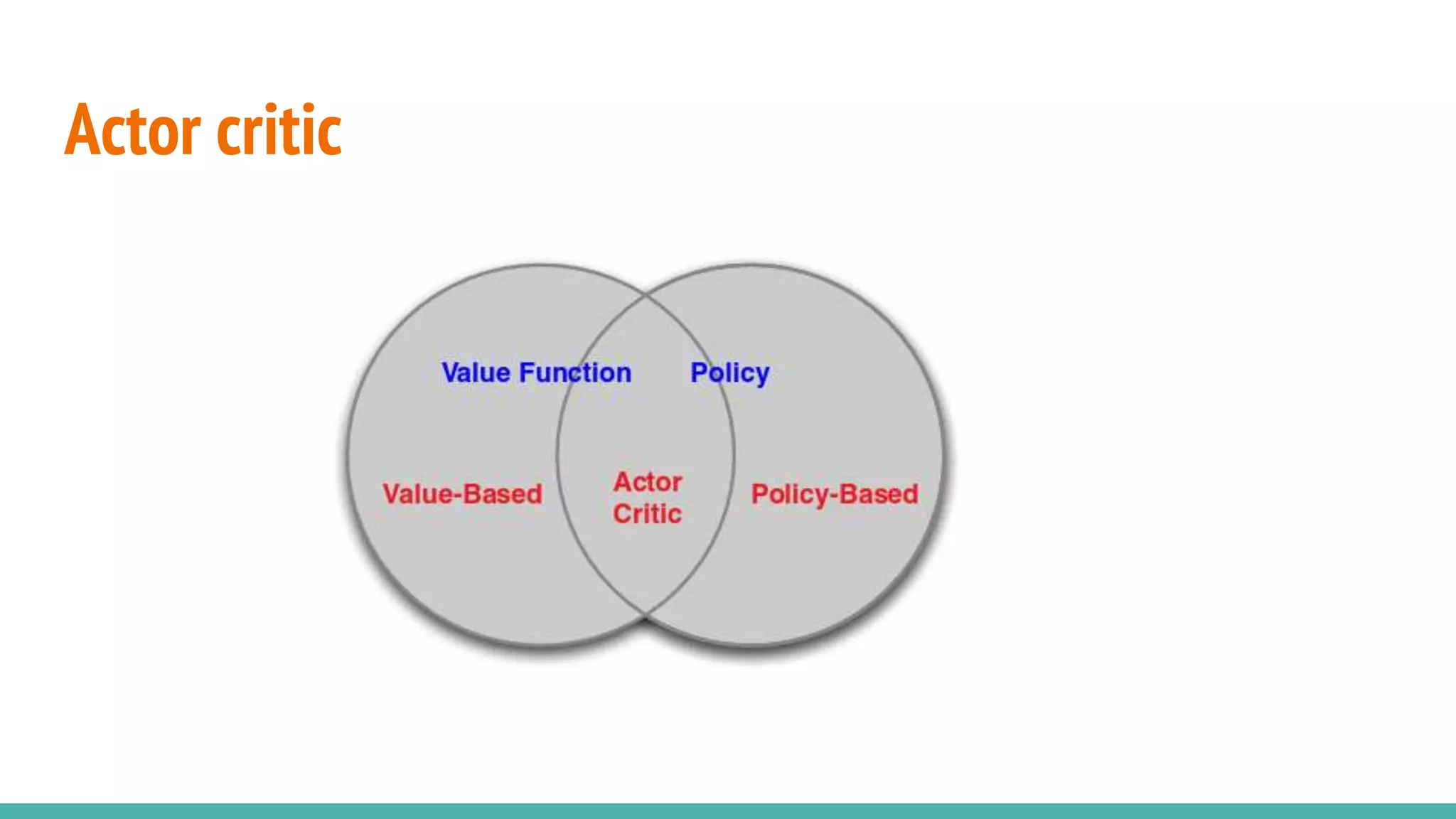
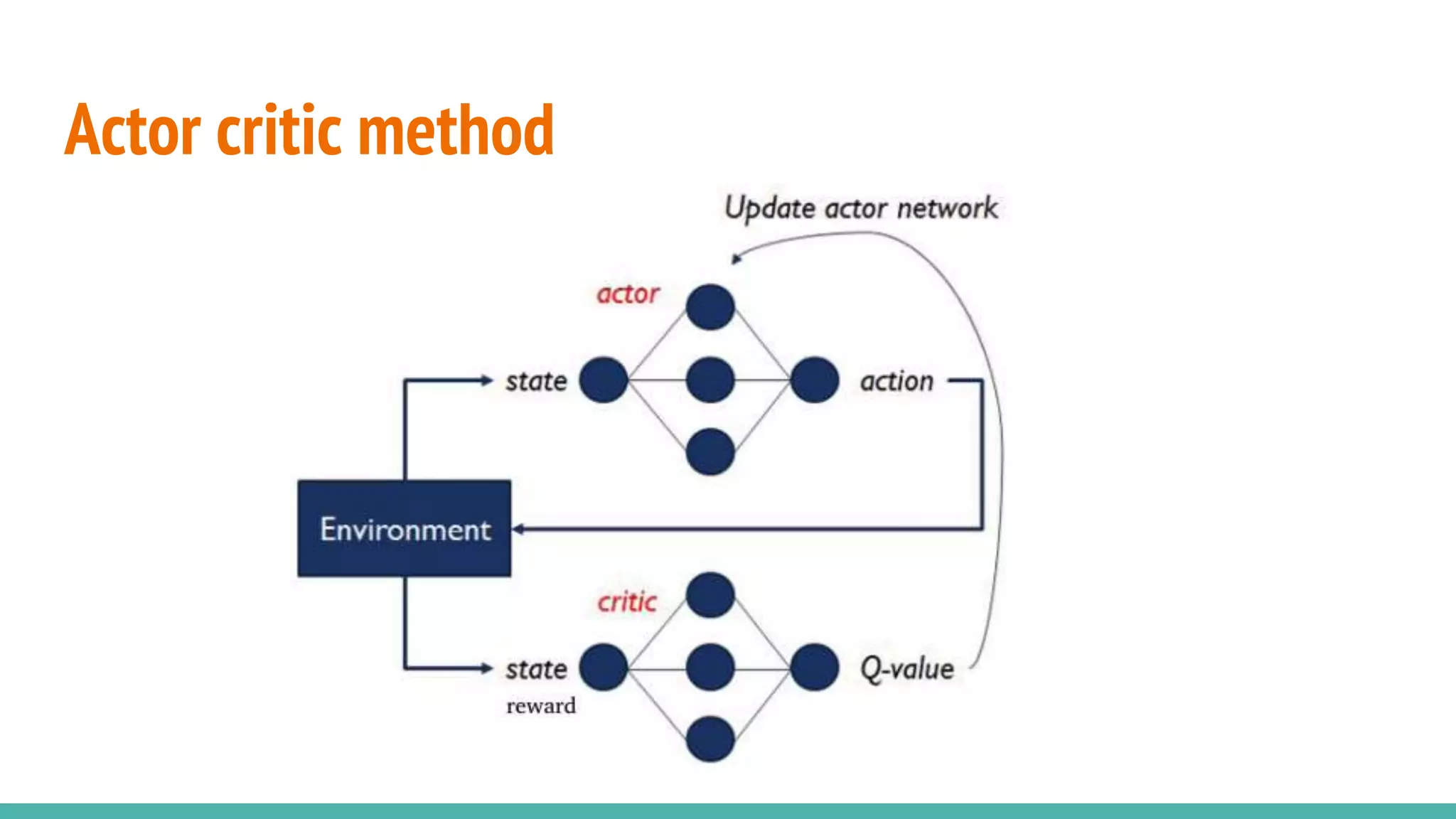
Describes the actor-critic method, a key concept in reinforcement learning involving two components.
Outlines the characteristics of DDPG including continuous spaces, replay buffers, and exploration.
Identifies major challenges in DDPG such as reward function design and training requirements.
Details an application of DDPG in simulating driving scenarios.














































