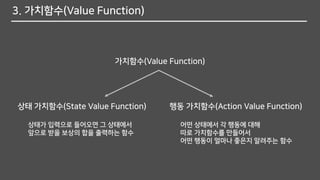
3. 가치함수(Value Function)
가치함수(ValueFunction)
상태 가치함수(State Value Function) 행동 가치함수(Action Value Function)
상태가 입력으로 들어오면 그 상태에서
앞으로 받을 보상의 합을 출력하는 함수
어떤 상태에서 각 행동에 대해
따로 가치함수를 만들어서
어떤 행동이 얼마나 좋은지 알려주는 함수
10.
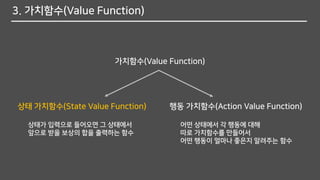
3. 가치함수(Value Function)
가치함수(ValueFunction)
상태 가치함수(State Value Function) 행동 가치함수(Action Value Function)
상태가 입력으로 들어오면 그 상태에서
앞으로 받을 보상의 합을 출력하는 함수
어떤 상태에서 각 행동에 대해
따로 가치함수를 만들어서
어떤 행동이 얼마나 좋은지 알려주는 함수
11.
상태 가치함수(State ValueFunction)
𝑣 𝑠 = 𝐸[𝐺𝑡|𝑆𝑡 = 𝑠]
𝑣 𝑠 = 𝐸[𝑅𝑡+1 + 𝛾𝑅𝑡+2 + 𝛾2
𝑅𝑡+3 + ⋯ |𝑆𝑡 = 𝑠]
- 상태 가치함수의 정의
𝑣 𝑠 = 𝐸[𝑅𝑡+1 + 𝛾(𝑅𝑡+2 + 𝛾𝑅𝑡+3 + ⋯ )|𝑆𝑡 = 𝑠]
- 앞으로 받을 보상으로 표현한 상태 가치함수
(𝐺𝑡 = 𝑅𝑡+1 + 𝛾𝑅𝑡+2 + 𝛾2
𝑅𝑡+3 + ⋯)
- 앞으로 받을 보상에서 𝛾 로 묶어 표현한 상태 가치함수
𝑣 𝑠 = 𝐸[𝑅𝑡+1 + 𝛾𝐺𝑡+1|𝑆𝑡 = 𝑠] - 반환값(𝐺)으로 표현한 상태 가치함수
12.
상태 가치함수(State ValueFunction)
𝑣 𝑠 = 𝐸[𝑅𝑡+1 + 𝛾𝐺𝑡+1|𝑆𝑡 = 𝑠] - 반환값(𝐺)으로 표현한 상태 가치함수
𝑣 𝑠 = 𝐸[𝑅𝑡+1 + 𝛾𝑣(𝑆𝑡+1)|𝑆𝑡 = 𝑠] - 가치함수로 표현한 상태 가치함수
𝑣 𝜋 𝑠 = 𝐸 𝜋[𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)|𝑆𝑡 = 𝑠] - 정책을 고려한 상태 가치함수
(𝑣 𝑆𝑡+1 = 𝐸[𝐺𝑡+1|𝑆𝑡+1 = 𝑠])
13.
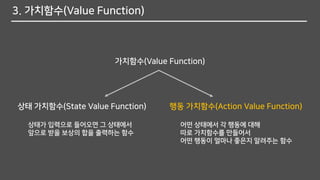
3. 가치함수(Value Function)
가치함수(ValueFunction)
상태 가치함수(State Value Function) 행동 가치함수(Action Value Function)
상태가 입력으로 들어오면 그 상태에서
앞으로 받을 보상의 합을 출력하는 함수
어떤 상태에서 각 행동에 대해
따로 가치함수를 만들어서
어떤 행동이 얼마나 좋은지 알려주는 함수
다이나믹 프로그래밍(Dynamic Programming,DP)이란?
다이나믹(Dynamic)
동적 메모리
(동적메모리란 메모리가
시간에 따라 변하는 메모리)
프로그래밍(Programming)
컴퓨터 프로그래밍이 아니라
계획을 하는 것으로서 여러 프로세스가
다단계로 이루어지는 것
+
한 마디로 큰 문제 안에 작은 문제들이 중첩된 경우에
전체 큰 문제를 작은 문제로 쪼개서 풀겠다는 것.
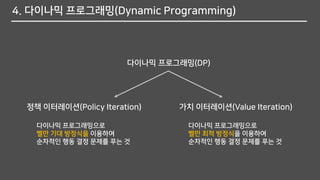
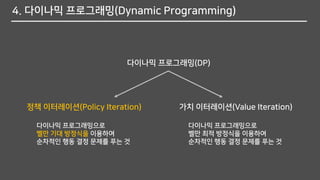
4. 다이나믹 프로그래밍(DynamicProgramming)
다이나믹 프로그래밍(DP)
정책 이터레이션(Policy Iteration) 가치 이터레이션(Value Iteration)
다이나믹 프로그래밍으로
벨만 기대 방정식을 이용하여
순차적인 행동 결정 문제를 푸는 것
다이나믹 프로그래밍으로
벨만 최적 방정식을 이용하여
순차적인 행동 결정 문제를 푸는 것
21.
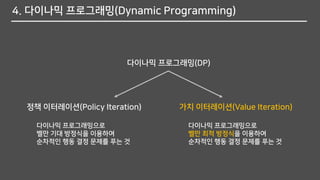
4. 다이나믹 프로그래밍(DynamicProgramming)
다이나믹 프로그래밍(DP)
정책 이터레이션(Policy Iteration) 가치 이터레이션(Value Iteration)
다이나믹 프로그래밍으로
벨만 기대 방정식을 이용하여
순차적인 행동 결정 문제를 푸는 것
다이나믹 프로그래밍으로
벨만 최적 방정식을 이용하여
순차적인 행동 결정 문제를 푸는 것
22.
정책 이터레이션(Policy Iteration)
정책이터레이션
= 벨만 기대 방정식을 이용
= 정책 + 가치함수
= 정책 + 상태 가치함수(기댓값) + 행동 가치함수(=큐함수, argmax)
= 정책 평가(Policy Evaluation)
+ 탐욕 정책 발전(Greedy Policy Improvement)
23.
정책 이터레이션(Policy Iteration)
정책이터레이션
= 벨만 기대 방정식을 이용
= 정책 + 가치함수
= 정책 + 상태 가치함수(기댓값) + 행동 가치함수(=큐함수, argmax)
= 정책 평가(Policy Evaluation)
+ 탐욕 정책 발전(Greedy Policy Improvement)
24.
정책 평가(Policy Evaluation)
정책평가 -> 벨만 기대 방정식
𝑣 𝜋 𝑠 = 𝐸 𝜋[𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)|𝑆𝑡 = 𝑠]
𝑣 𝜋 𝑠 =
𝑎∈𝐴
𝜋(𝑎|𝑠)(𝑅𝑡+1 + 𝛾
𝑠`∈𝑆
𝑃𝑠𝑠`
𝑎
𝑣 𝜋(𝑠`))
- 벨만 기대 방정식의 정의
- 계산 가능한 벨만 기대 방정식
𝑣 𝑘+1 𝑠 =
𝑎∈𝐴
𝜋(𝑎|𝑠)(𝑅𝑡+1 + 𝛾𝑣 𝑘 𝑠` ) - k와 k+1로 표현한 벨만 기대 방정식
(상태 변환 확률 = 1)
25.
정책 이터레이션(Policy Iteration)
정책이터레이션
= 벨만 기대 방정식을 이용
= 정책 + 가치함수
= 정책 + 상태 가치함수(기댓값) + 행동 가치함수(=큐함수, argmax)
= 정책 평가(Policy Evaluation)
+ 탐욕 정책 발전(Greedy Policy Improvement)
26.
탐욕 정책 발전(GreedyPolicy Improvement)
탐욕 정책 발전 -> 큐함수(argmax)
큐함수의 정의
계산 가능한 형태로 고친 큐함수
(상태 변환 확률 = 1)
- 탐욕 정책 발전으로 얻은 새로운 정책
𝑞 𝜋(𝑠, 𝑎) = 𝐸 𝜋[𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)|𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎]
𝑞 𝜋(𝑠, 𝑎) = 𝑅 𝑠
𝑎 + 𝛾𝑣 𝜋(𝑠`)
𝜋` 𝑠 = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑎∈𝐴 𝑞 𝜋(𝑠, 𝑎)
27.
4. 다이나믹 프로그래밍(DynamicProgramming)
다이나믹 프로그래밍(DP)
정책 이터레이션(Policy Iteration) 가치 이터레이션(Value Iteration)
다이나믹 프로그래밍으로
벨만 기대 방정식을 이용하여
순차적인 행동 결정 문제를 푸는 것
다이나믹 프로그래밍으로
벨만 최적 방정식을 이용하여
순차적인 행동 결정 문제를 푸는 것
28.
가치 이터레이션(Value Iteration)
가치이터레이션
= 벨만 최적 방정식을 이용
= 행동 가치함수(=큐함수, max)
𝑞∗(𝑠, 𝑎) = 𝐸[𝑅𝑡+1 + 𝛾 max
𝑎`
𝑞∗(𝑆𝑡+1, 𝑎`) |𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎]
𝑣∗ 𝑠 = max
𝑎
𝐸[𝑅𝑡+1 + 𝛾𝑣∗(𝑆𝑡+1)|𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎] - 벨만 최적 방정식의 정의
- 큐함수로 표현한 벨만 최적 방정식
𝑣 𝑘+1(𝑠) = max
𝑎∈𝐴
(𝑅 𝑠
𝑎 + 𝛾𝑣 𝑘 𝑠` ) k와 k+1로 표현한 계산 가능한 벨만 최적 방정식
(상태 변환 확률 = 1)





![1. MDP(Markov Decision Process)
𝑆𝑡 = s상태(State)
행동(Action) 𝐴 𝑡 = a
보상함수(Reward Function) 𝑅 𝑠
𝑎
= E[𝑅𝑡+1|𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎]
상태 변환 확률
(State Transition Probability) 𝑃𝑠𝑠`
𝑎
= P[𝑆𝑡+1 = 𝑠`|𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎]
할인율(Discount Factor) 𝛾 (단, 𝛾 ∈ [0,1])](https://image.slidesharecdn.com/flowchartpart1ofreinforcementlearning-180322084943/85/Part-1-5-320.jpg)

![2. 정책(Policy)
𝜋 𝑎 𝑠 = 𝑃[𝐴 𝑡 = 𝑎|𝑆𝑡 = 𝑠]
정책(Policy)의 정의](https://image.slidesharecdn.com/flowchartpart1ofreinforcementlearning-180322084943/85/Part-1-7-320.jpg)

![상태 가치함수(State Value Function)
𝑣 𝑠 = 𝐸[𝐺𝑡|𝑆𝑡 = 𝑠]
𝑣 𝑠 = 𝐸[𝑅𝑡+1 + 𝛾𝑅𝑡+2 + 𝛾2
𝑅𝑡+3 + ⋯ |𝑆𝑡 = 𝑠]
- 상태 가치함수의 정의
𝑣 𝑠 = 𝐸[𝑅𝑡+1 + 𝛾(𝑅𝑡+2 + 𝛾𝑅𝑡+3 + ⋯ )|𝑆𝑡 = 𝑠]
- 앞으로 받을 보상으로 표현한 상태 가치함수
(𝐺𝑡 = 𝑅𝑡+1 + 𝛾𝑅𝑡+2 + 𝛾2
𝑅𝑡+3 + ⋯)
- 앞으로 받을 보상에서 𝛾 로 묶어 표현한 상태 가치함수
𝑣 𝑠 = 𝐸[𝑅𝑡+1 + 𝛾𝐺𝑡+1|𝑆𝑡 = 𝑠] - 반환값(𝐺)으로 표현한 상태 가치함수](https://image.slidesharecdn.com/flowchartpart1ofreinforcementlearning-180322084943/85/Part-1-11-320.jpg)
![상태 가치함수(State Value Function)
𝑣 𝑠 = 𝐸[𝑅𝑡+1 + 𝛾𝐺𝑡+1|𝑆𝑡 = 𝑠] - 반환값(𝐺)으로 표현한 상태 가치함수
𝑣 𝑠 = 𝐸[𝑅𝑡+1 + 𝛾𝑣(𝑆𝑡+1)|𝑆𝑡 = 𝑠] - 가치함수로 표현한 상태 가치함수
𝑣 𝜋 𝑠 = 𝐸 𝜋[𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)|𝑆𝑡 = 𝑠] - 정책을 고려한 상태 가치함수
(𝑣 𝑆𝑡+1 = 𝐸[𝐺𝑡+1|𝑆𝑡+1 = 𝑠])](https://image.slidesharecdn.com/flowchartpart1ofreinforcementlearning-180322084943/85/Part-1-12-320.jpg)

![큐함수(Q Function)
𝑣 𝜋 𝑠 =
𝑎∈𝐴
𝜋(𝑎|𝑠)𝑞 𝜋(𝑠, 𝑎)
𝑞 𝜋(𝑠, 𝑎) = 𝐸 𝜋[𝑅𝑡+1 + 𝛾𝑞 𝜋(𝑆𝑡+1, 𝐴 𝑡+1)|𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎] - 큐함수의 정의
- 상태 가치함수와 큐함수 사이의 관계식](https://image.slidesharecdn.com/flowchartpart1ofreinforcementlearning-180322084943/85/Part-1-15-320.jpg)






![정책 평가(Policy Evaluation)
정책 평가 -> 벨만 기대 방정식
𝑣 𝜋 𝑠 = 𝐸 𝜋[𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)|𝑆𝑡 = 𝑠]
𝑣 𝜋 𝑠 =
𝑎∈𝐴
𝜋(𝑎|𝑠)(𝑅𝑡+1 + 𝛾
𝑠`∈𝑆
𝑃𝑠𝑠`
𝑎
𝑣 𝜋(𝑠`))
- 벨만 기대 방정식의 정의
- 계산 가능한 벨만 기대 방정식
𝑣 𝑘+1 𝑠 =
𝑎∈𝐴
𝜋(𝑎|𝑠)(𝑅𝑡+1 + 𝛾𝑣 𝑘 𝑠` ) - k와 k+1로 표현한 벨만 기대 방정식
(상태 변환 확률 = 1)](https://image.slidesharecdn.com/flowchartpart1ofreinforcementlearning-180322084943/85/Part-1-24-320.jpg)

![탐욕 정책 발전(Greedy Policy Improvement)
탐욕 정책 발전 -> 큐함수(argmax)
큐함수의 정의
계산 가능한 형태로 고친 큐함수
(상태 변환 확률 = 1)
- 탐욕 정책 발전으로 얻은 새로운 정책
𝑞 𝜋(𝑠, 𝑎) = 𝐸 𝜋[𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)|𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎]
𝑞 𝜋(𝑠, 𝑎) = 𝑅 𝑠
𝑎 + 𝛾𝑣 𝜋(𝑠`)
𝜋` 𝑠 = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑎∈𝐴 𝑞 𝜋(𝑠, 𝑎)](https://image.slidesharecdn.com/flowchartpart1ofreinforcementlearning-180322084943/85/Part-1-26-320.jpg)
![가치 이터레이션(Value Iteration)
가치 이터레이션
= 벨만 최적 방정식을 이용
= 행동 가치함수(=큐함수, max)
𝑞∗(𝑠, 𝑎) = 𝐸[𝑅𝑡+1 + 𝛾 max
𝑎`
𝑞∗(𝑆𝑡+1, 𝑎`) |𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎]
𝑣∗ 𝑠 = max
𝑎
𝐸[𝑅𝑡+1 + 𝛾𝑣∗(𝑆𝑡+1)|𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎] - 벨만 최적 방정식의 정의
- 큐함수로 표현한 벨만 최적 방정식
𝑣 𝑘+1(𝑠) = max
𝑎∈𝐴
(𝑅 𝑠
𝑎 + 𝛾𝑣 𝑘 𝑠` ) k와 k+1로 표현한 계산 가능한 벨만 최적 방정식
(상태 변환 확률 = 1)](https://image.slidesharecdn.com/flowchartpart1ofreinforcementlearning-180322084943/85/Part-1-28-320.jpg)




















![[DL輪読会]Reinforcement Learning with Deep Energy-Based Policies](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170406-170407002545-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[머가]Chap11 강화학습](https://cdn.slidesharecdn.com/ss_thumbnails/chap11-170923012256-thumbnail.jpg?width=640&height=640&fit=bounds)

















