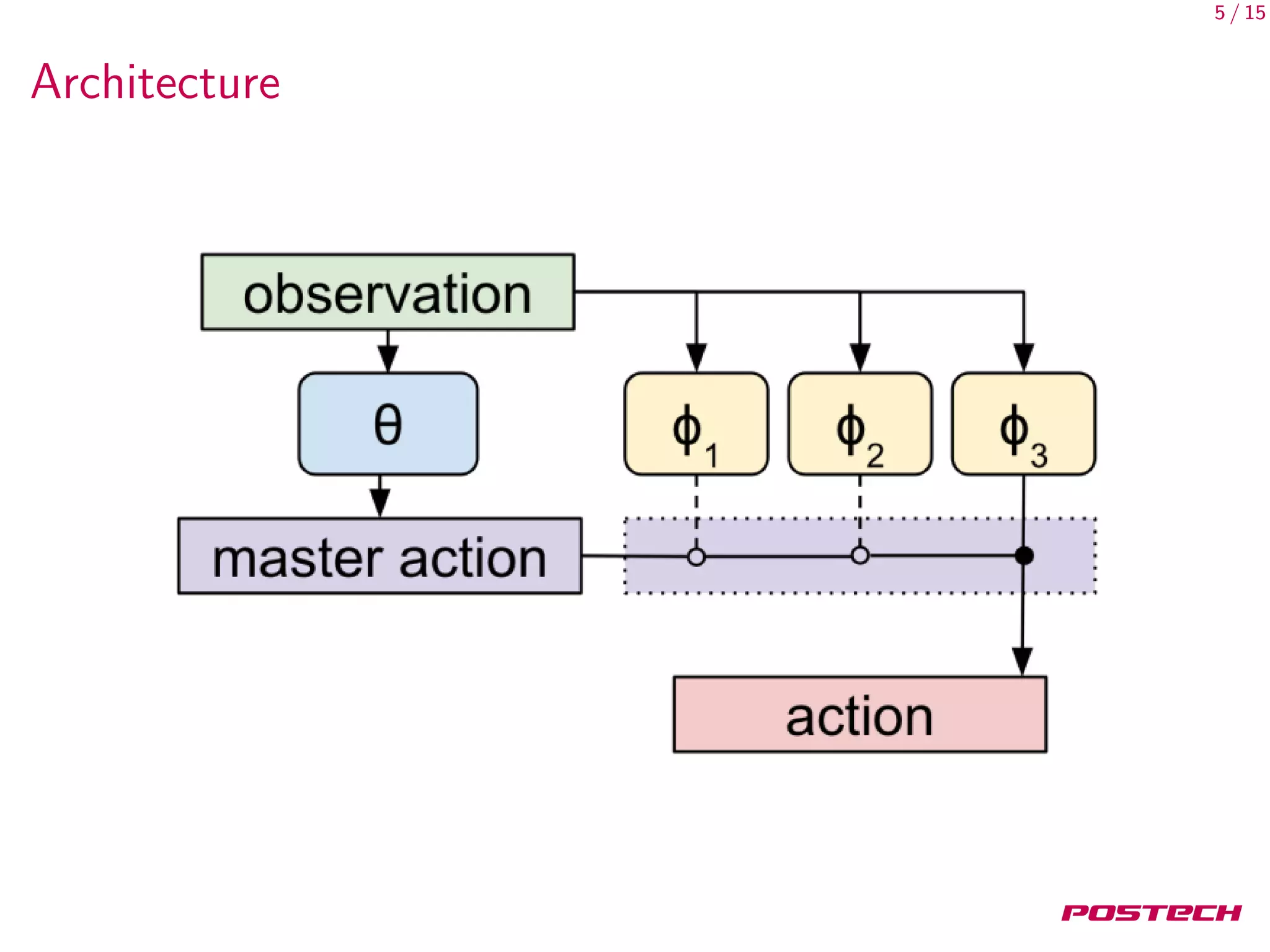
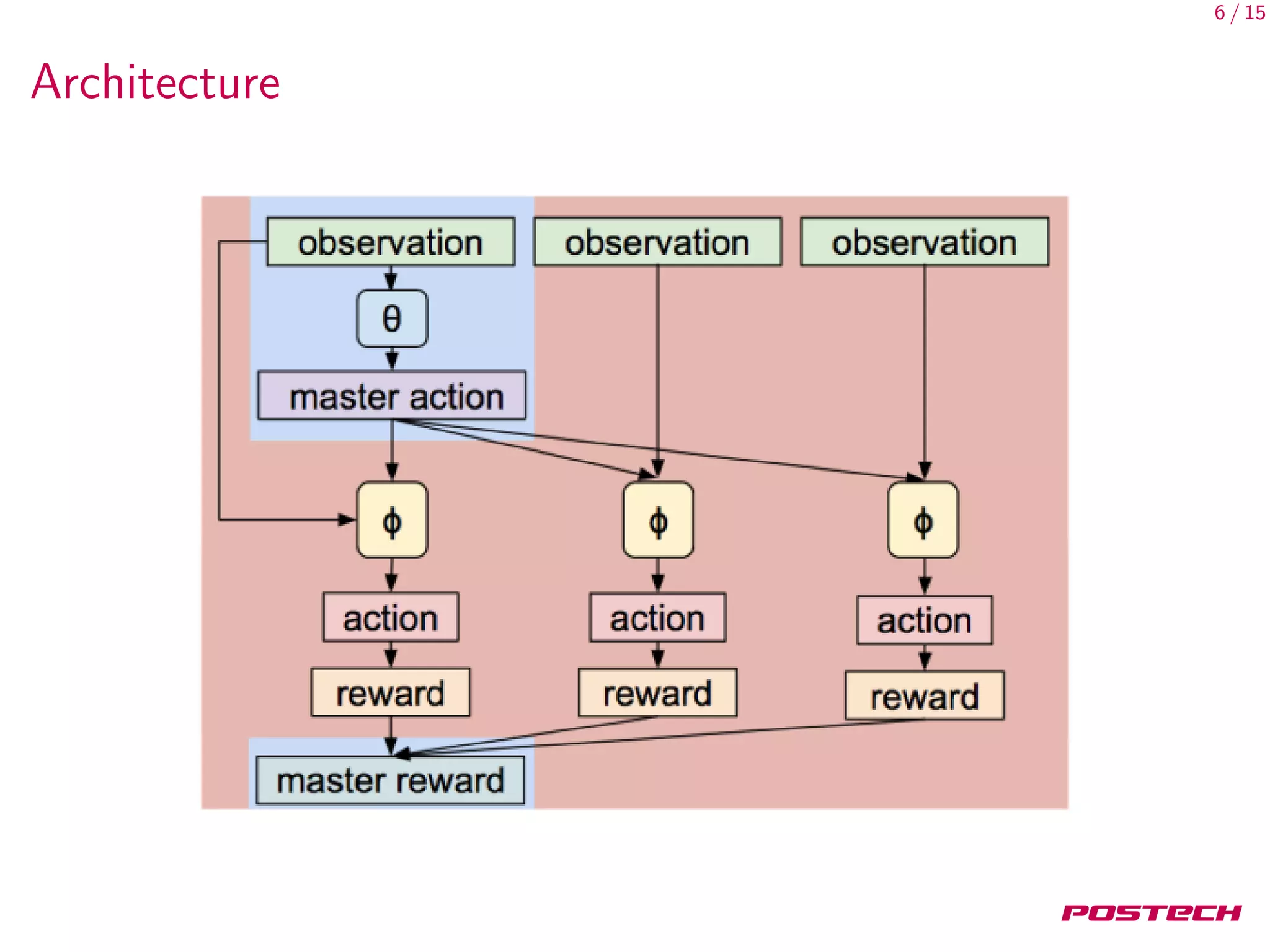
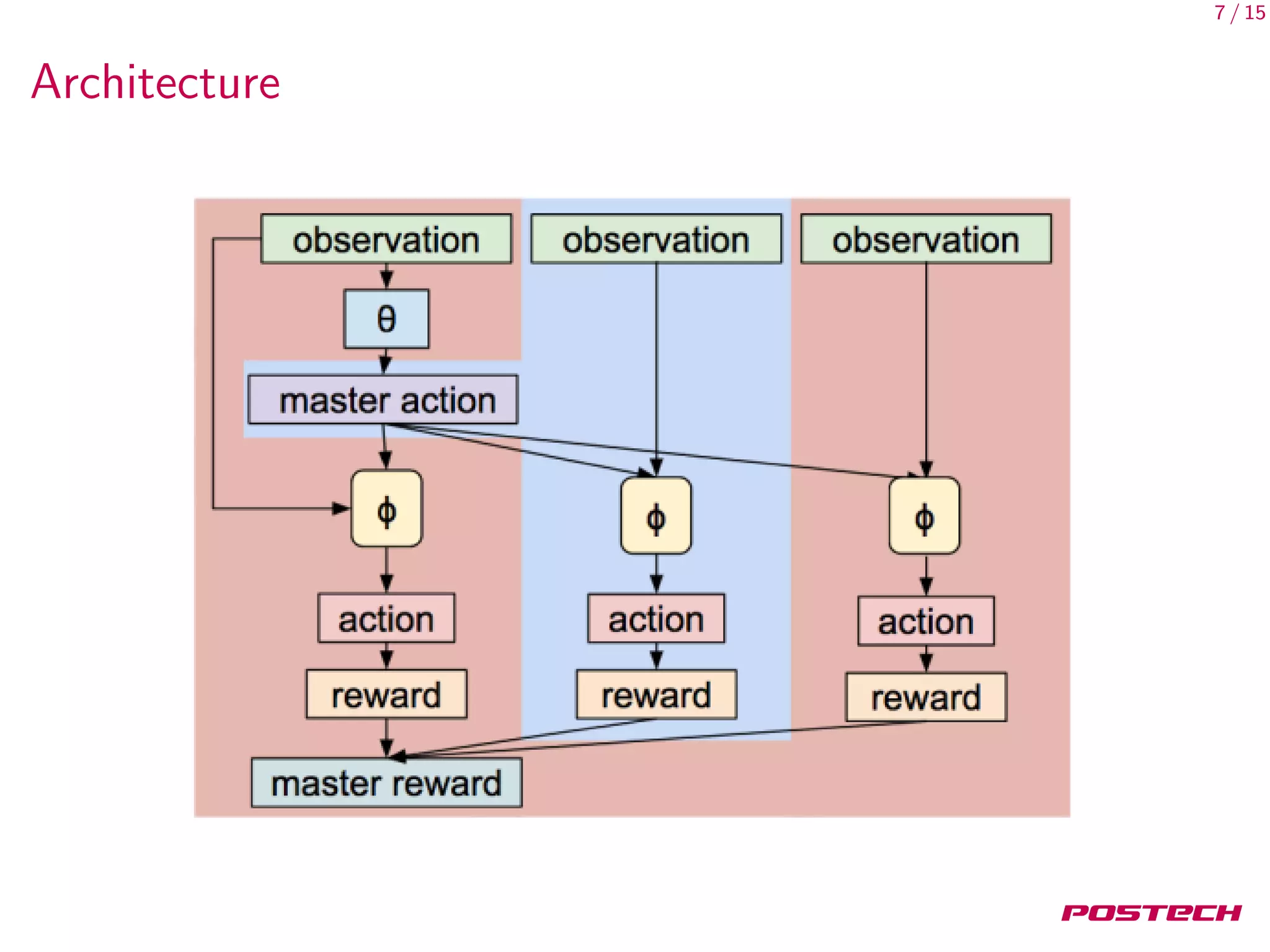
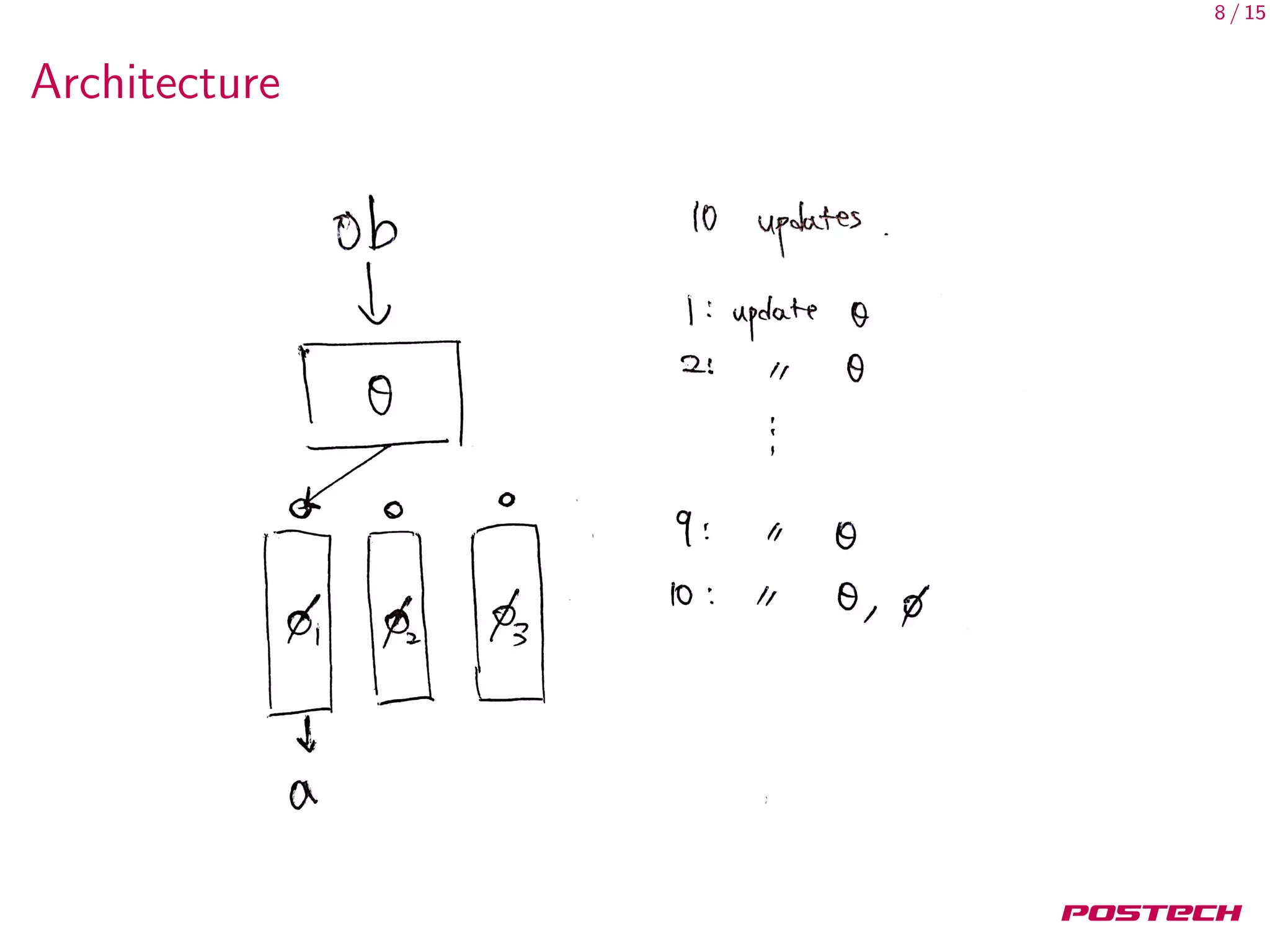
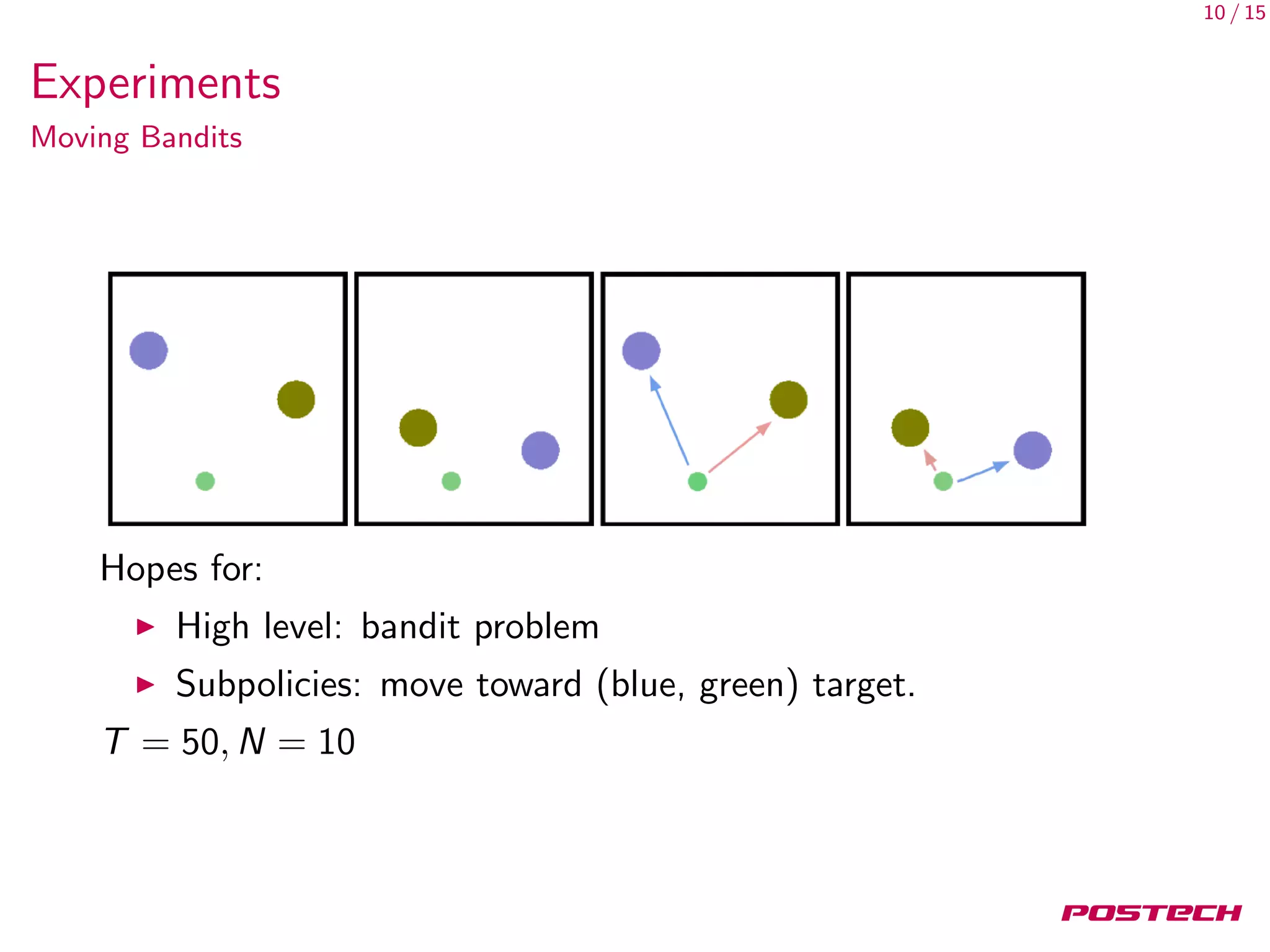
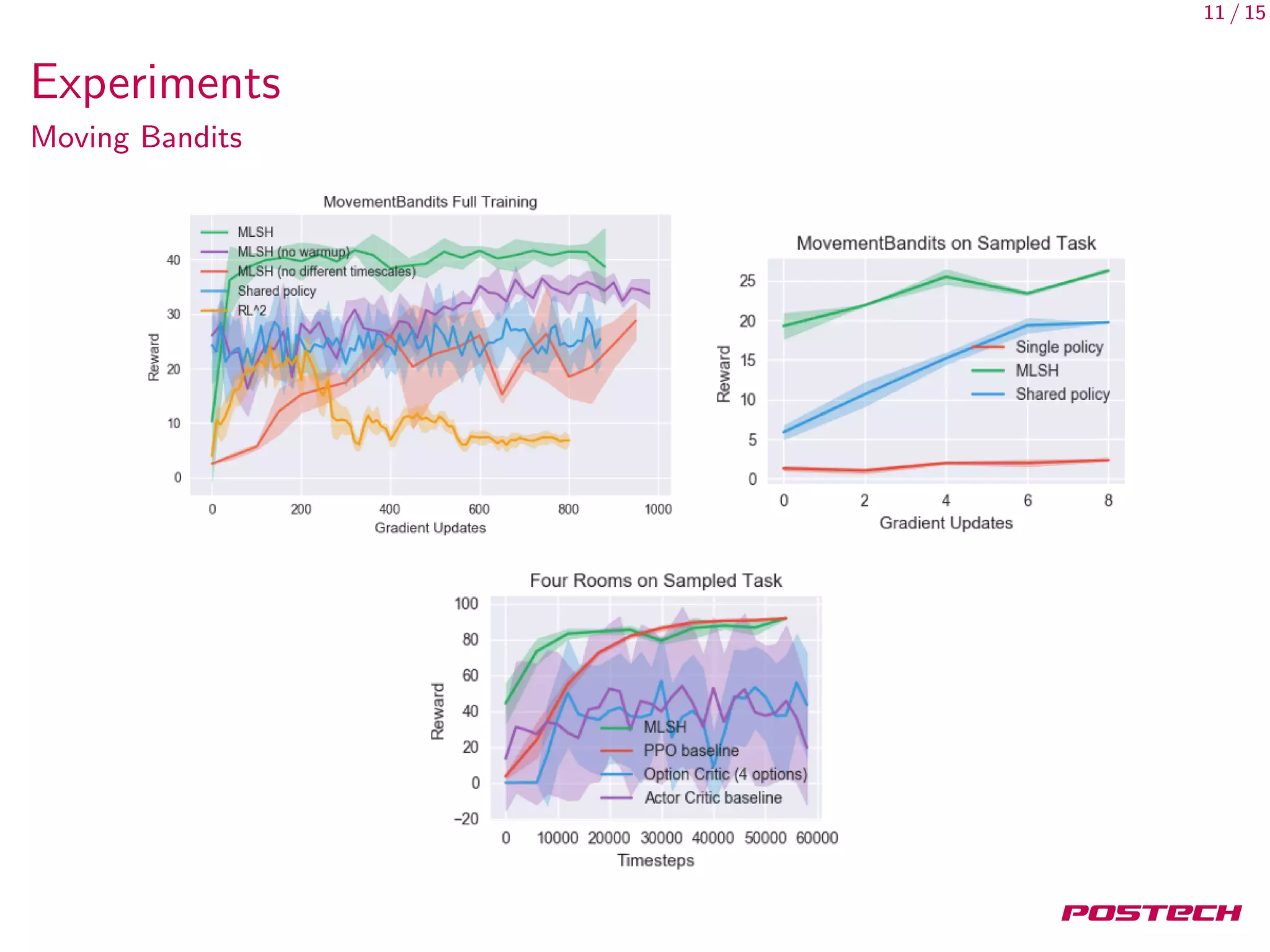
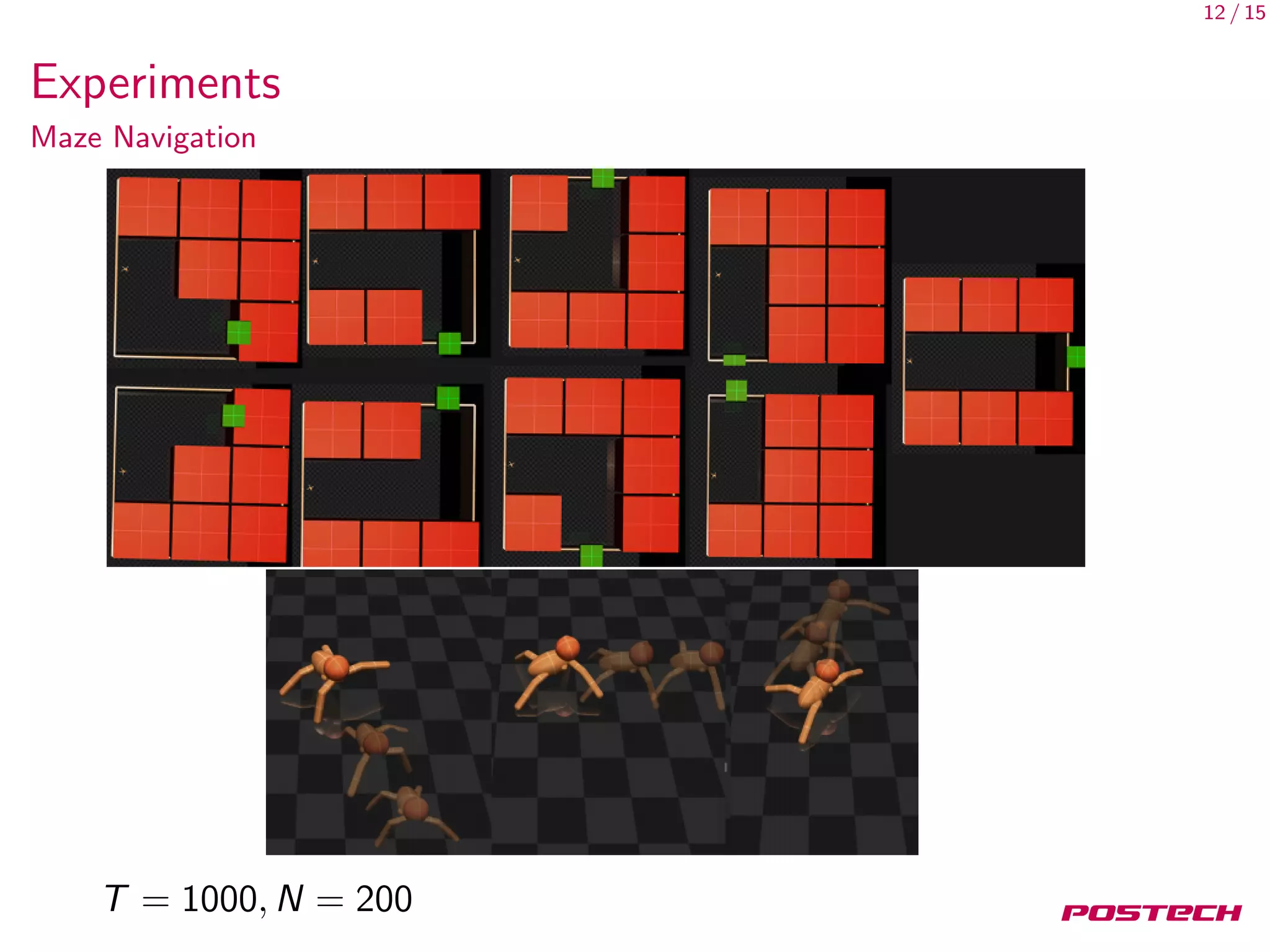
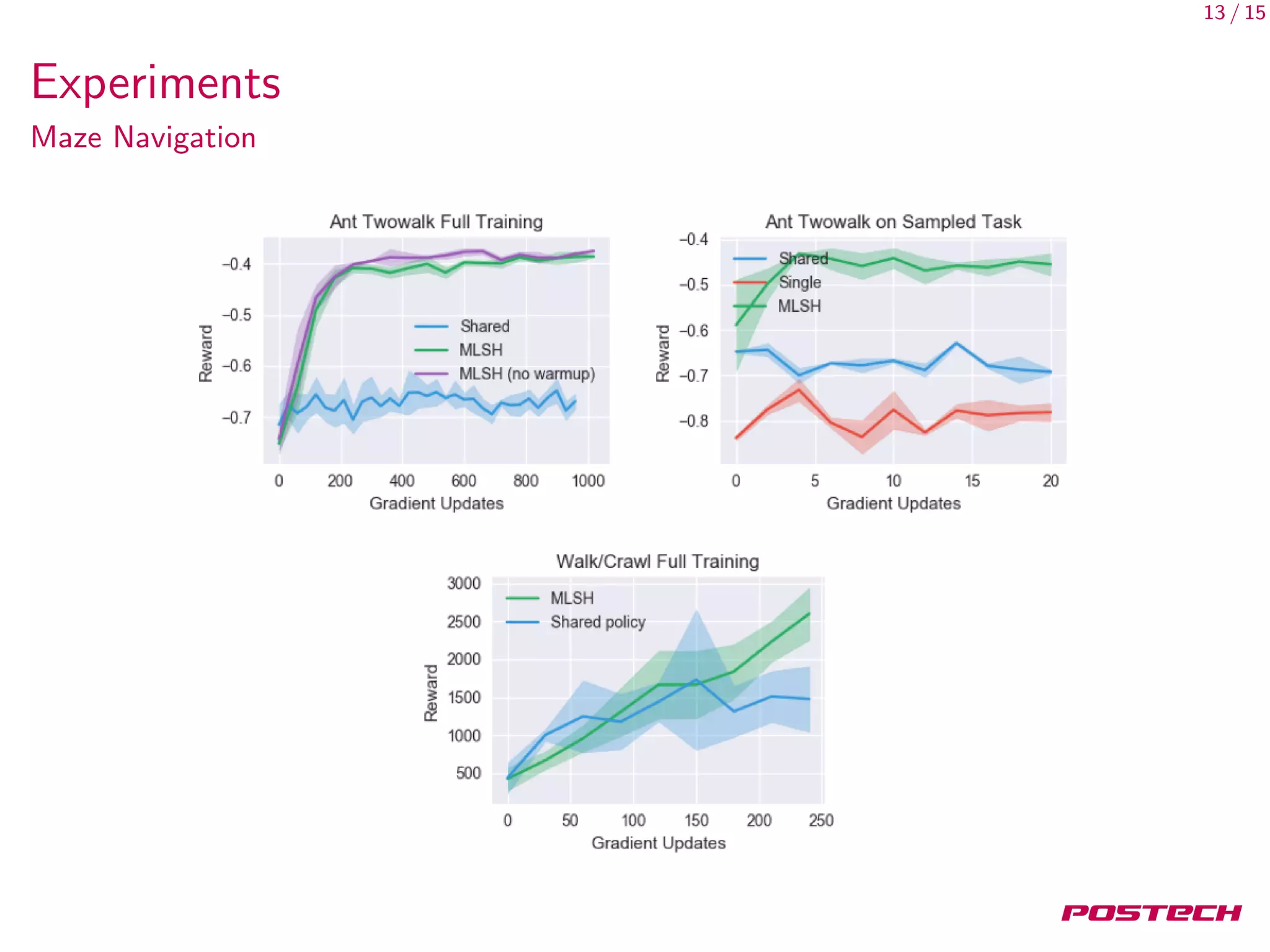
This document discusses meta-learning shared hierarchies for hierarchical reinforcement learning. It presents an approach that learns over a set of tasks, allowing agents to share some weights, with the goal that the shared weights will learn a set of generally applicable sub-policies. The document outlines an algorithm and architecture for this approach, and evaluates it on bandit and maze navigation tasks, demonstrating its ability to transfer knowledge to new environments.







































![[DL輪読会] off-policyなメタ強化学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190405journalclub-190415082841-thumbnail.jpg?width=640&height=640&fit=bounds)
































