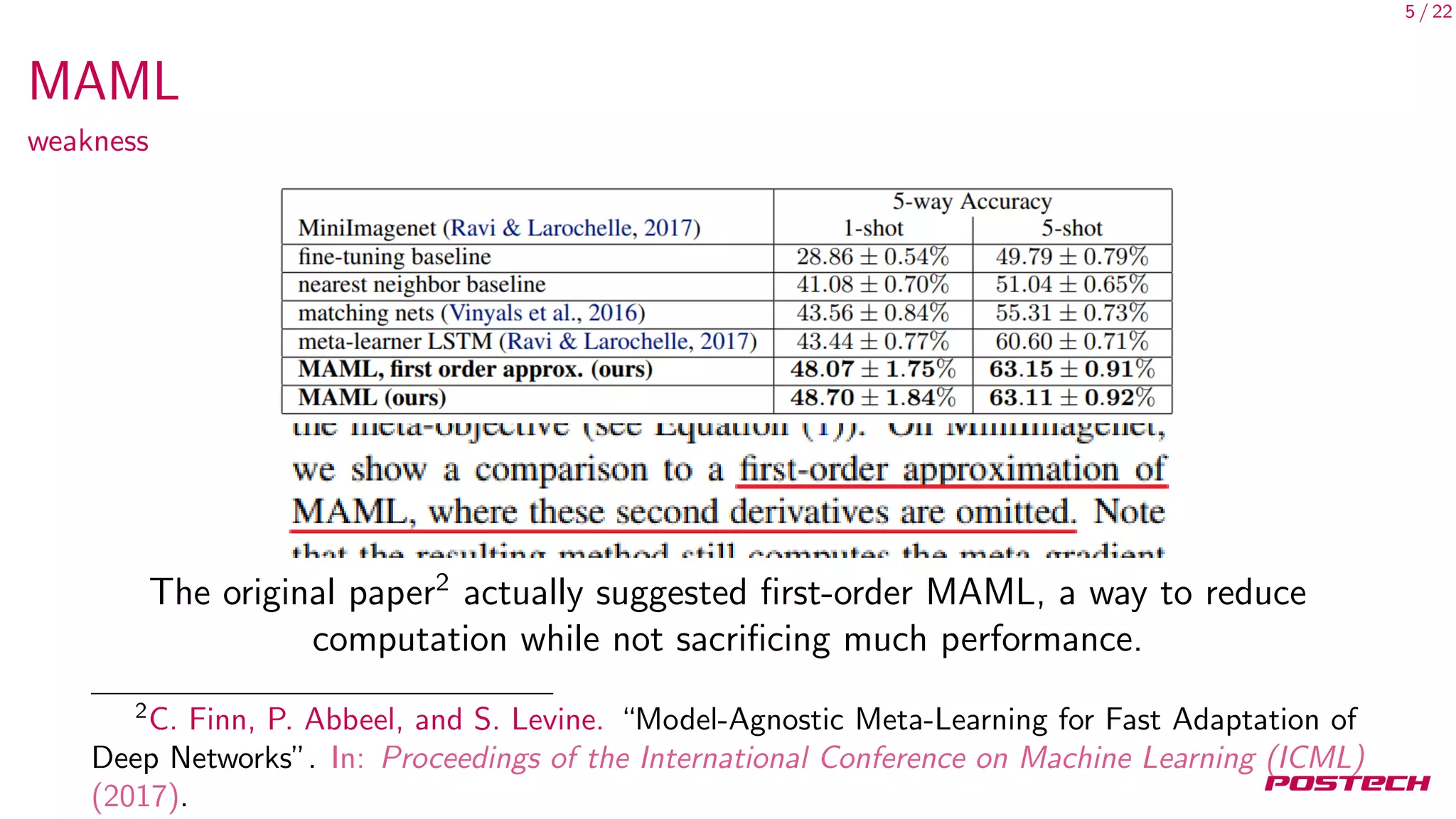
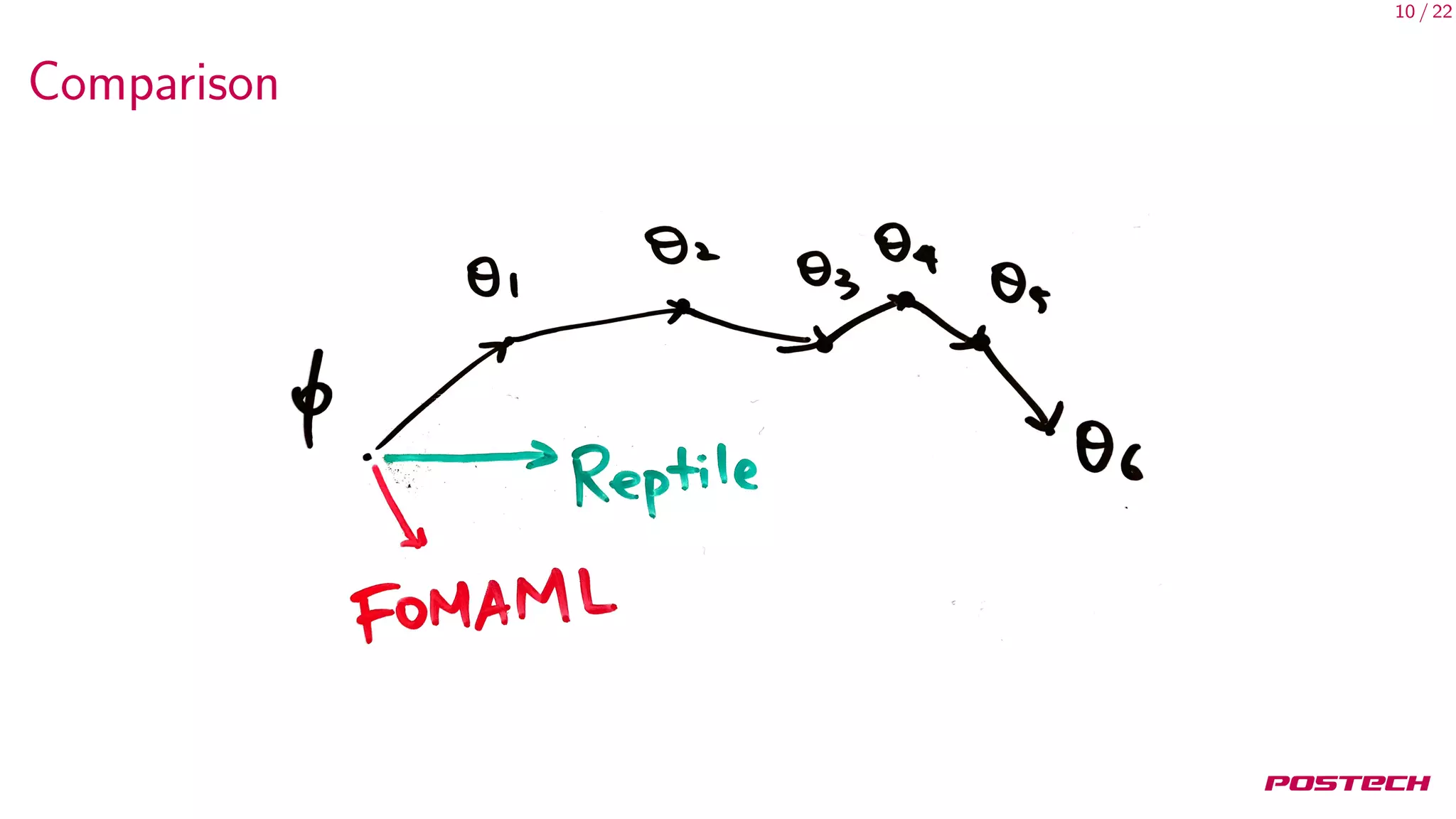
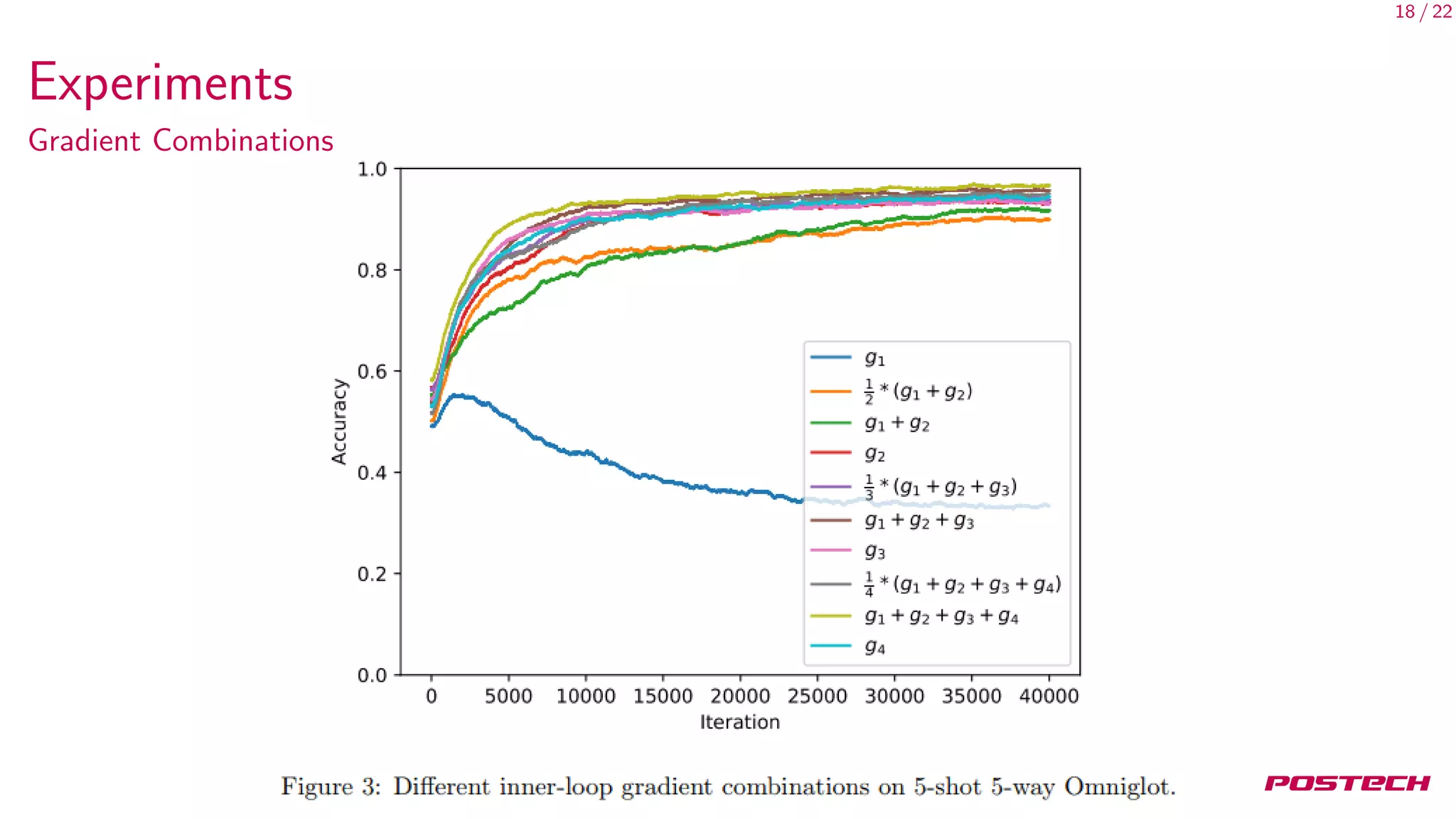
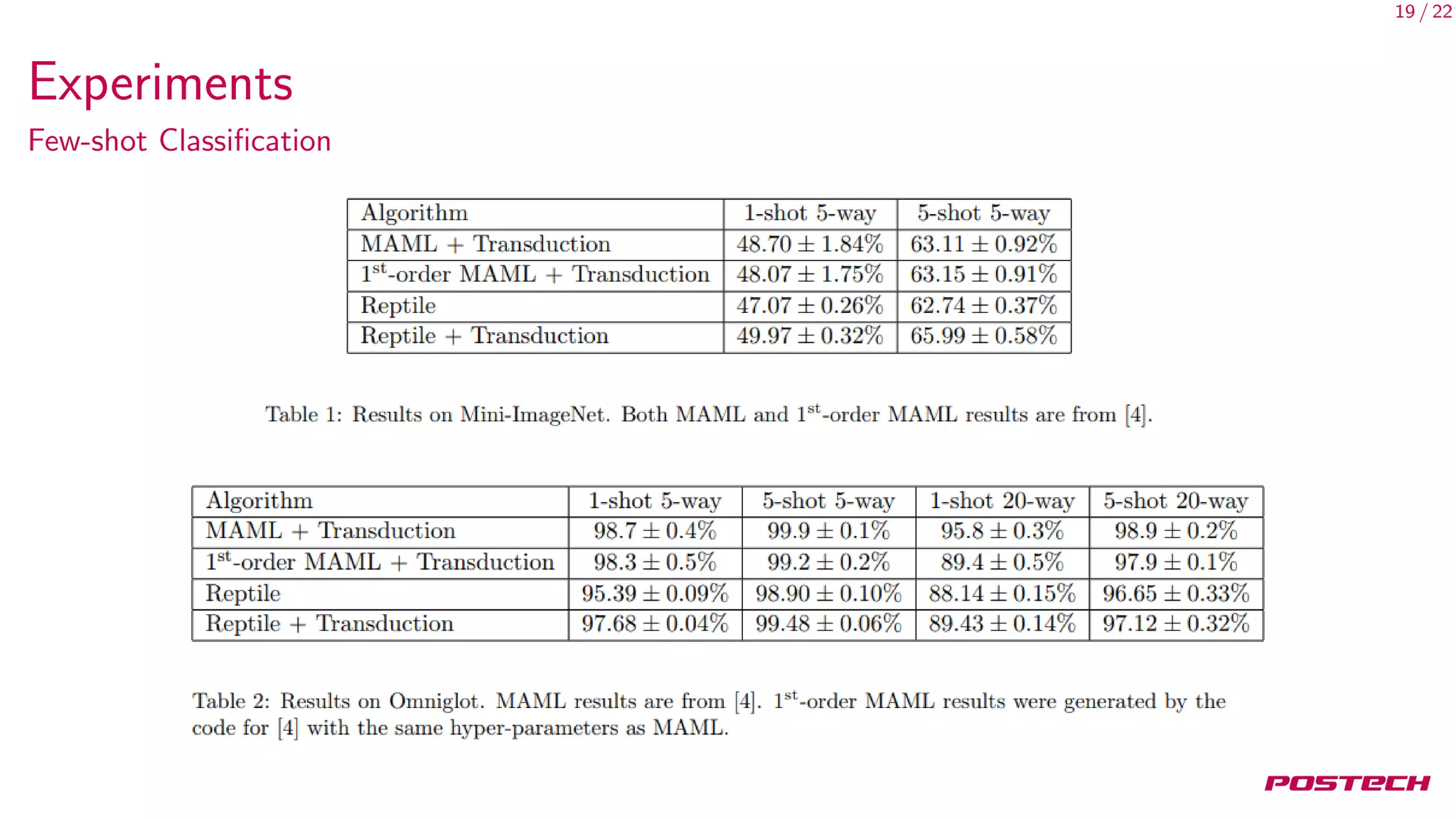
This document summarizes and analyzes first-order meta-learning algorithms. It discusses MAML, which approximates the MAML objective using only first-order information (FOMAML). FOMAML is equivalent to applying the last gradient to the initial parameters. Reptile is also analyzed, which simply averages the parameter updates. In expectation, the gradients of MAML, FOMAML and Reptile depend on the average gradient and average inner product of gradients. Experiments show similar performance between FOMAML and Reptile. The analysis suggests SGD may generalize well due to being an approximation of MAML.








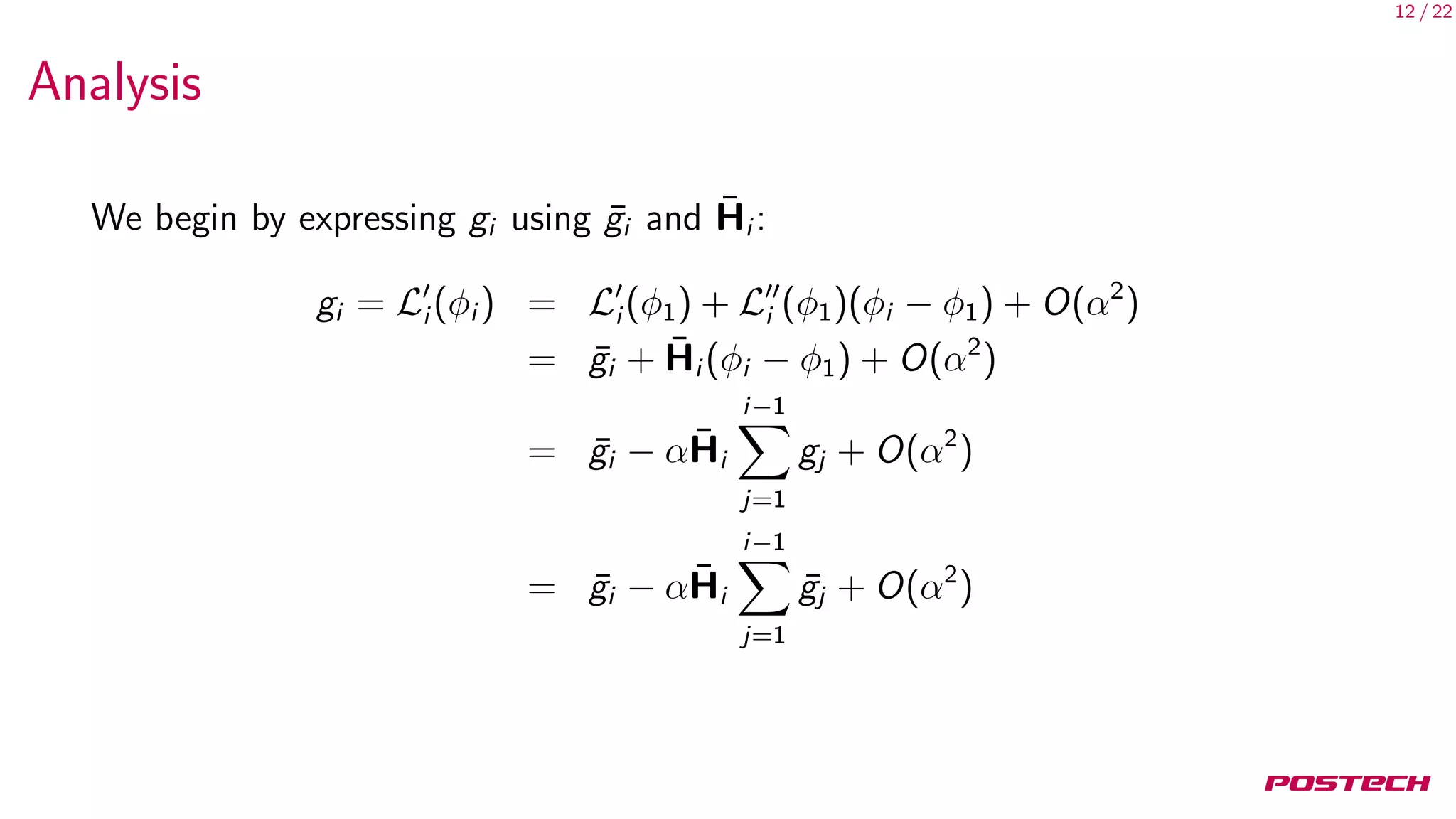

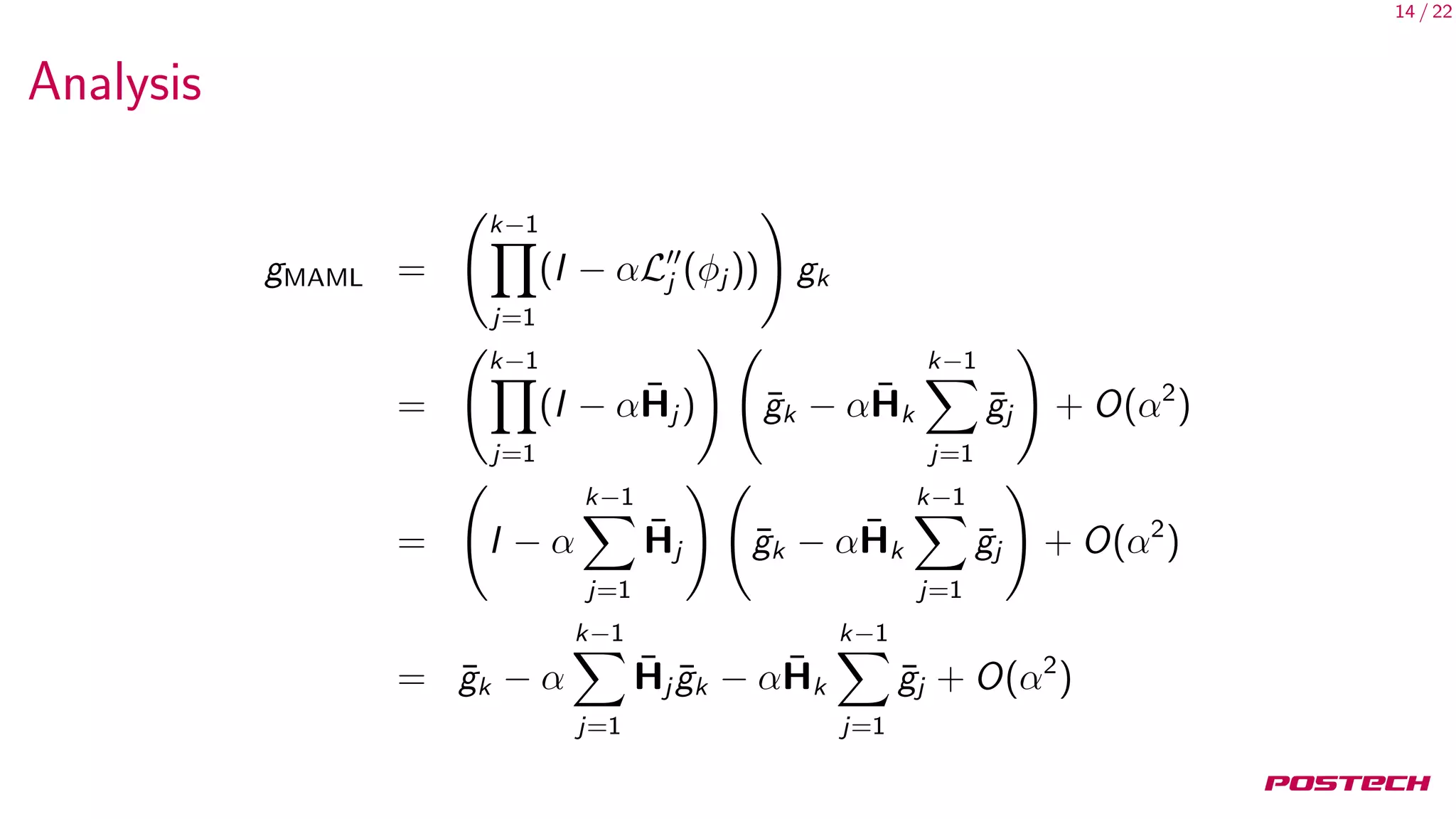
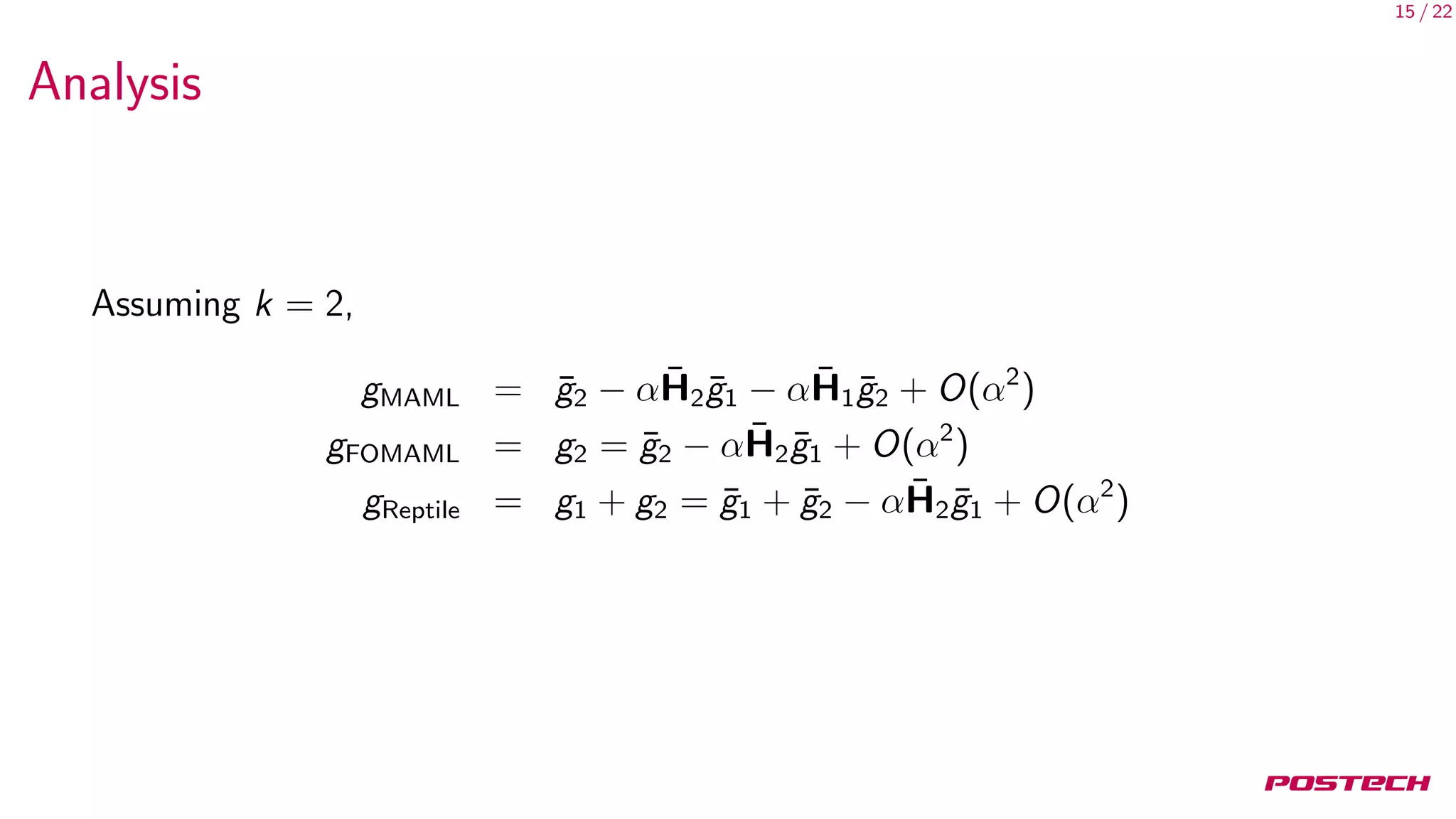
![16 / 22
Analysis
Since loss functions are exchangeable (losses are typically computed over
minibatches randomly taken from a larger set),
E[¯g1] = E[¯g2] = · · ·
Similarly,
E[ ¯Hi ¯gj ] =
1
2
E[ ¯Hi ¯gj + ¯Hj ¯gi ]
=
1
2
E[
∂
∂φ1
(¯gi · ¯gj )]](https://image.slidesharecdn.com/main-180517050811/75/On-First-Order-Meta-Learning-Algorithms-16-2048.jpg)
![17 / 22
Analysis
Therfore, in expectation, there are only two kinds of terms:
AvgGrad = E[¯g]
AvgGradInner = E[¯g · ¯g ]
We now return to gradient-based meta-learning for k steps:
E[gMAML] = 1AvgGrad + (2k − 2)αAvgGradInner
E[gFOMAML] = 1AvgGrad + (k − 1)αAvgGradInner
E[gReptile] = kAvgGrad +
1
2
k(k − 1)αAvgGradInner](https://image.slidesharecdn.com/main-180517050811/75/On-First-Order-Meta-Learning-Algorithms-17-2048.jpg)

![22 / 22
References I
[1] John Schulman Alex Nichol Joshua Achiam. “On First-Order Meta-Learning
Algorithms”. In: (2018). Preprint arXiv:1803.02999.
[2] C. Finn, P. Abbeel, and S. Levine. “Model-Agnostic Meta-Learning for Fast
Adaptation of Deep Networks”. In: Proceedings of the International
Conference on Machine Learning (ICML) (2017).](https://image.slidesharecdn.com/main-180517050811/75/On-First-Order-Meta-Learning-Algorithms-22-2048.jpg)


![[DL輪読会]1次近似系MAMLとその理論的背景](https://cdn.slidesharecdn.com/ss_thumbnails/20190412kondo-190412002418-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL Hacks]Model-Agnostic Meta-Learning for Fast Adaptation of Deep Network](https://cdn.slidesharecdn.com/ss_thumbnails/maml-181024060235-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Pyramid Stereo Matching Network](https://cdn.slidesharecdn.com/ss_thumbnails/2019-05-31psmnetpyramidstereomatchingnetwork-hiroakisugisaki-190531000258-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]陰関数微分を用いた深層学習](https://cdn.slidesharecdn.com/ss_thumbnails/implicitgradient1-191001072242-thumbnail.jpg?width=640&height=640&fit=bounds)


















































