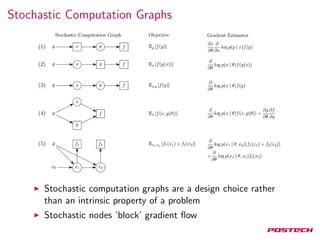
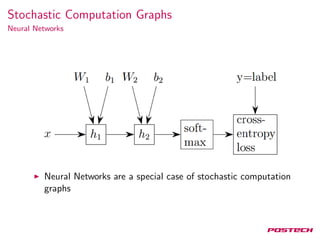
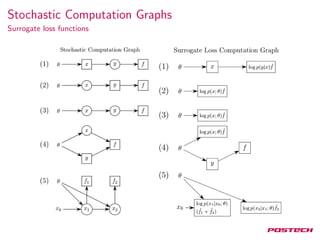
The document discusses stochastic gradient estimation using stochastic computation graphs, which are essential in various applications such as computational finance, reinforcement learning, and neural networks. It introduces different gradient estimation approaches, including score function and pathwise derivative estimators, highlighting their advantages and disadvantages. Furthermore, it emphasizes the versatility of stochastic computation graphs in expressing multiple algorithms and their capacity to unify diverse methods in machine learning.




![Stochastic Gradient Estimation
R(θ) = Ew∼Pθ(dw)[f (θ, w)]
Approximate θR(θ) can be used for:
Computational Finance
Reinforcement Learning
Variational Inference
Explaining the brain with neural networks](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-4-320.jpg)
![Stochastic Gradient Estimation
R(θ) = Ew∼Pθ(dw)[f (θ, w)] =
Ω
f (θ, w)Pθ(dw)](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-5-320.jpg)
![Stochastic Gradient Estimation
R(θ) = Ew∼Pθ(dw)[f (θ, w)] =
Ω
f (θ, w)Pθ(dw)
=
Ω
f (θ, w)
Pθ(dw)
G(dw)
G(dw)](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-6-320.jpg)
![Stochastic Gradient Estimation
R(θ) = Ew∼Pθ(dw)[f (θ, w)] =
Ω
f (θ, w)Pθ(dw)
=
Ω
f (θ, w)
Pθ(dw)
G(dw)
G(dw)
θR(θ) = θ
Ω
f (θ, w)
Pθ(dw)
G(dw)
G(dw)
=
Ω
θ(f (θ, w)
Pθ(dw)
G(dw)
)G(dw)
= Ew∼G(dw)[ θf (θ, w)
Pθ(dw)
G(dw)
+ f (θ, w)
θPθ(dw)
G(dw)
]](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-7-320.jpg)
![Stochastic Gradient Estimation
So far we have
θR(θ) = Ew∼G(dw)[ θf (θ, w)
Pθ(dw)
G(dw)
+ f (θ, w)
θPθ(dw)
G(dw)
]](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-8-320.jpg)
![Stochastic Gradient Estimation
So far we have
θR(θ) = Ew∼G(dw)[ θf (θ, w)
Pθ(dw)
G(dw)
+ f (θ, w)
θPθ(dw)
G(dw)
]
Letting G = Pθ0 and evaluating at θ = θ0, we get
θR(θ)
θ=θ0
= Ew∼Pθ0
(dw)[ θf (θ, w)
Pθ(dw)
Pθ0 (dw)
+ f (θ, w)
θPθ(dw)
Pθ0 (dw)
]
θ=θ0
= Ew∼Pθ0
(dw)[ θf (θ, w) + f (θ, w) θlnPθ(dw)]
θ=θ0](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-9-320.jpg)
![Stochastic Gradient Estimation
So far we have
R(θ) = Ew∼Pθ(dw)[f (θ, w)]
θR(θ)
θ=θ0
= Ew∼Pθ0
(dw)[ θf (θ, w) + f (θ, w) θlnPθ(dw)]
θ=θ0](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-10-320.jpg)
![Stochastic Gradient Estimation
So far we have
R(θ) = Ew∼Pθ(dw)[f (θ, w)]
θR(θ)
θ=θ0
= Ew∼Pθ0
(dw)[ θf (θ, w) + f (θ, w) θlnPθ(dw)]
θ=θ0
1. Assuming w fully determines f :
θR(θ)
θ=θ0
= Ew∼Pθ0
(dw)[f (w) θlnPθ(dw)]
θ=θ0
2. Assuming Pθ(dw) is independent of θ:
θR(θ) = Ew∼P(dw)[ θf (θ, w)]](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-11-320.jpg)
![Stochastic Gradient Estimation
SF vs PD
R(θ) = Ew∼Pθ(dw)[f (θ, w)]
Score Function (SF) Estimator:
θR(θ)
θ=θ0
= Ew∼Pθ0
(dw)[f (w) θlnPθ(dw)]
θ=θ0
Pathwise Derivative (PD) Estimator:
θR(θ) = Ew∼P(dw)[ θf (θ, w)]](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-12-320.jpg)
![Stochastic Gradient Estimation
SF vs PD
R(θ) = Ew∼Pθ(dw)[f (θ, w)]
Score Function (SF) Estimator:
θR(θ)
θ=θ0
= Ew∼Pθ0
(dw)[f (w) θlnPθ(dw)]
θ=θ0
Pathwise Derivative (PD) Estimator:
θR(θ) = Ew∼P(dw)[ θf (θ, w)]
SF allows discontinuous f .
SF requires sample values f ; PD requires derivatives f .
SF takes derivatives over the probability distribution of w; PD
takes derivatives over the function f .
SF has high variance on high-dimensional w.
PD has high variance on rough f .](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-13-320.jpg)



![Stochastic Computation Graphs
SF estimator:
θR(θ)
θ=θ0
= Ex∼Pθ0
(dx)[f (x) θlnPθ(dx)]
θ=θ0
PD estimator:
θR(θ) = Ez∼P(dz)[ θf (x(θ, z))]](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-17-320.jpg)




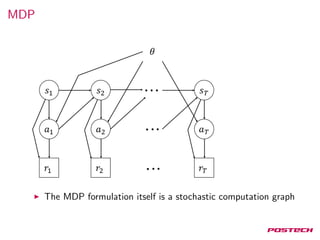

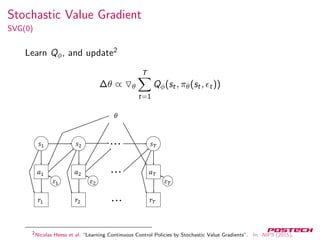
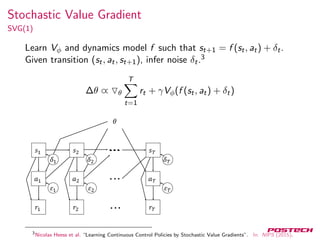
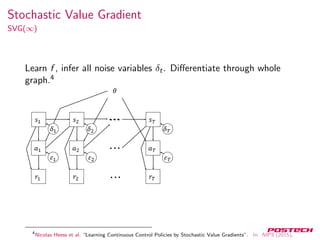
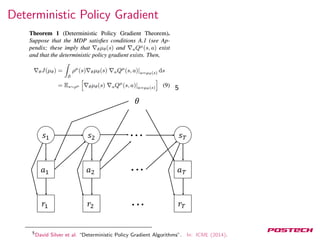
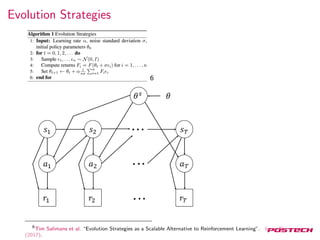

![Neural Variational Inference
7
Where
L(x, θ, φ) = Eh∼Q(h|x)[logPθ(x, h) − logQφ(h|x)]
Score function estimator
7
Andriy Mnih and Karol Gregor. “Neural Variational Inference and Learning in Belief Networks”. In: ICML
(2014).](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-34-320.jpg)

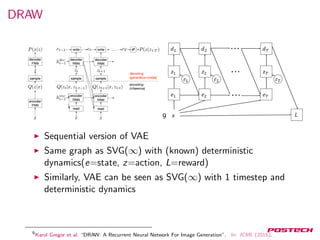
![GAN
10
Connection to SVG(0) has been established in [10]
Actor has no access to state. Observation is a random choice
between real or fake image. Reward is 1 if real, 0 if fake. D
learns value function of observation. G’s learning signal is D.
10
David Pfau and Oriol Vinyals. “Connecting Generative Adversarial Networks and Actor-Critic Methods”. In:
(2016).](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-37-320.jpg)
![Bayes by backprop
11
and our cost function f is:
f (D, θ) = Ew∼q(w|θ)[f (w, θ)]
= Ew∼q(w|θ)[−logp(D|w) + logq(w|θ) − logp(w)]
From the point of view of stochastic computation graphs,
weights and activations are not different
Estimate ELBO gradient of activation with PD estimator:
VAE
Estimate ELBO gradient of weight with PD estimator: Bayes
by Backprop
11
Charles Blundell et al. “Weight Uncertainty in Neural Networks”. In: ICML (2015).](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-38-320.jpg)
![Summary
Stochastic computation graphs explain many different
algorithms with one gradient estimator(Theorem 1)
Stochastic computation graphs give us insight into the
behavior of estimators
Stochastic computation graphs reveal equivalencies:
NVIL[7]=Policy gradient[12]
VAE[6]/DRAW[4]=SVG(∞)[5]
GAN[3]=SVG(0)[5]](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-39-320.jpg)
![References I
[1] Charles Blundell et al. “Weight Uncertainty in Neural
Networks”. In: ICML (2015).
[2] Michael Fu. “Stochastic Gradient Estimation”. In: (2005).
[3] Ian J. Goodfellow et al. “Generative Adversarial Networks”.
In: NIPS (2014).
[4] Karol Gregor et al. “DRAW: A Recurrent Neural Network
For Image Generation”. In: ICML (2015).
[5] Nicolas Heess et al. “Learning Continuous Control Policies
by Stochastic Value Gradients”. In: NIPS (2015).
[6] Diederik P Kingma and Max Welling. “Auto-Encoding
Variational Bayes”. In: ICLR (2014).
[7] Andriy Mnih and Karol Gregor. “Neural Variational Inference
and Learning in Belief Networks”. In: ICML (2014).](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-40-320.jpg)
![References II
[8] David Pfau and Oriol Vinyals. “Connecting Generative
Adversarial Networks and Actor-Critic Methods”. In: (2016).
[9] Tim Salimans et al. “Evolution Strategies as a Scalable
Alternative to Reinforcement Learning”. In: arXiv (2017).
[10] John Schulman et al. “Gradient Estimation Using Stochastic
Computation Graphs”. In: NIPS (2015).
[11] David Silver et al. “Deterministic Policy Gradient
Algorithms”. In: ICML (2014).
[12] Richard S Sutton et al. “Policy Gradient Methods for
Reinforcement Learning with Function Approximation”. In:
NIPS (1999).](https://image.slidesharecdn.com/20170509-170925075722/85/Gradient-Estimation-Using-Stochastic-Computation-Graphs-41-320.jpg)











































![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=640&height=640&fit=bounds)






























