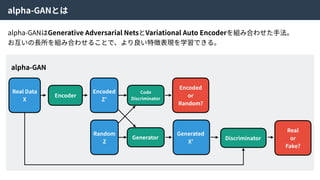
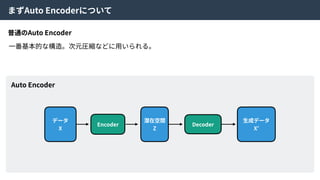
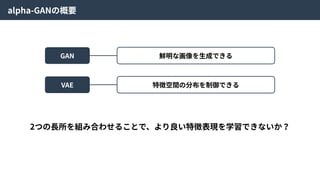
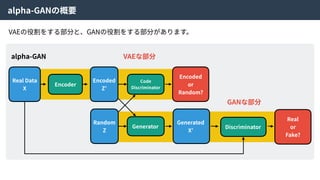
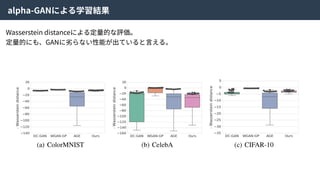
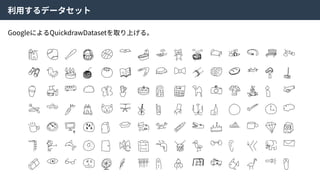
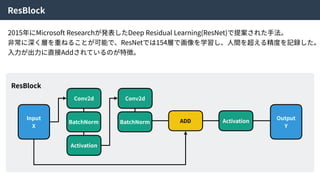
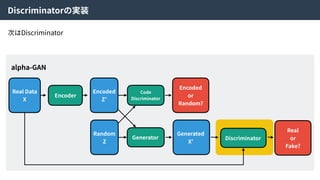
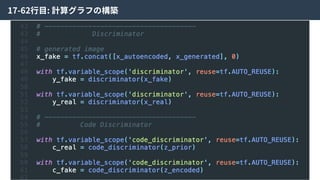
alpha-GANとは
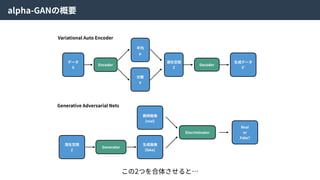
alpha-GANはGenerative Adversarial NetsとVariationalAuto Encoderを組み合わせた⼿法。
お互いの⻑所を組み合わせることで、より良い特徴表現を学習できる。
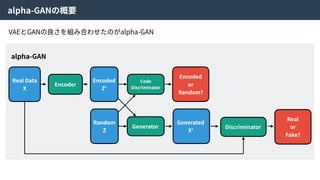
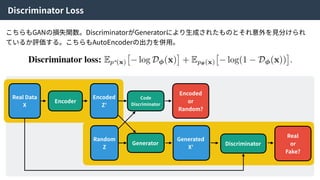
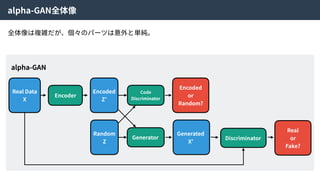
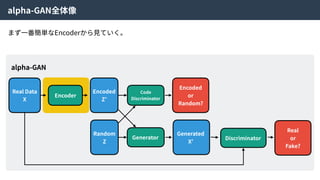
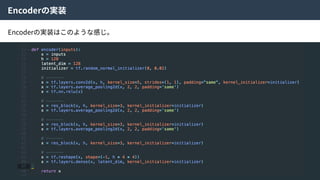
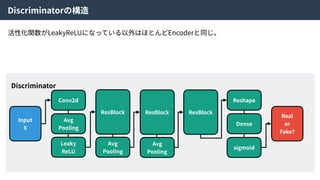
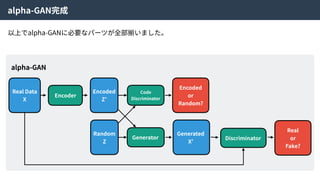
Real Data
X
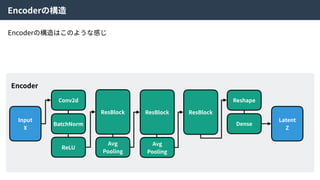
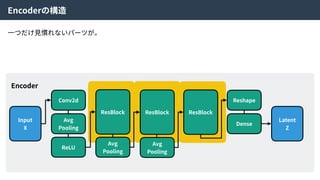
Encoder
Encoded
Z’
Random
Z
Code
Discriminator
Encoded
or
Random?
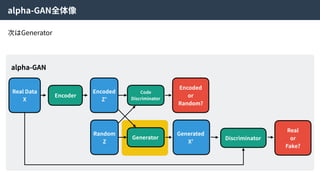
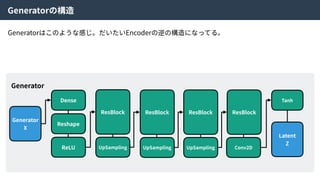
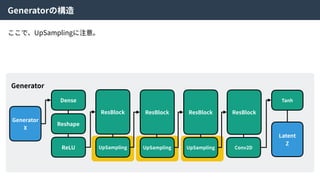
Generator
Generated
X’
Discriminator
Real
or
Fake?
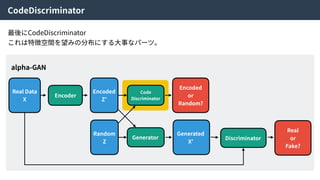
alpha-GAN
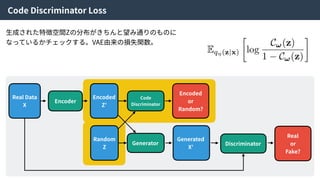
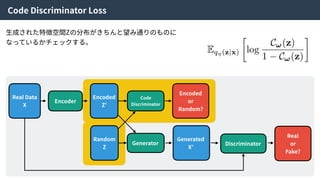
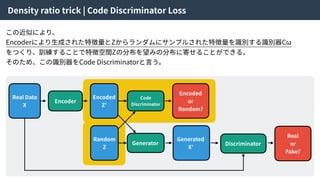
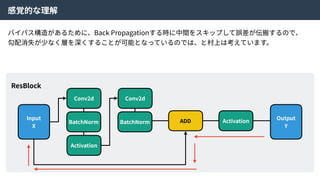
Density ratio trick| Code Discriminator Loss
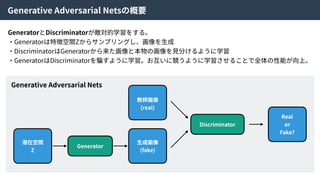
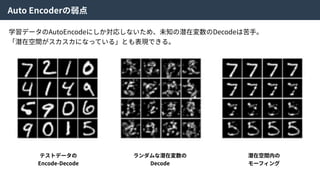
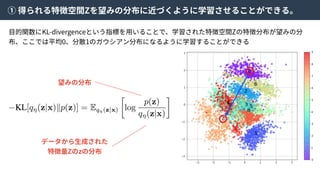
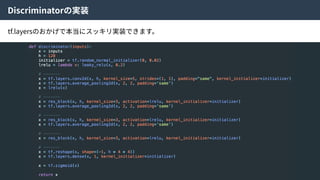
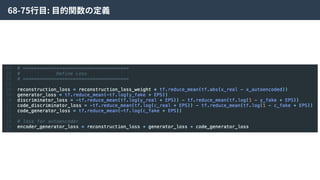
ここで、元となったVAEはKL-divergenceを使って得られたZの分布が望み通りになっていることを
チェックしていた。しかしながら、KL-divergenceはガウス分布を仮定しているため、それよりも複
雑な分布を仮定できないという⽋点があった。
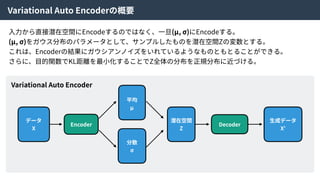
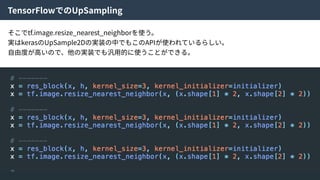
そこで、density ratio trickという⼿法を使い、KL-divergenceを以下のように近似した。
GANのLoss関数と同じ
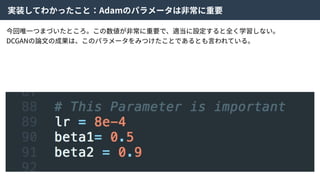
36.
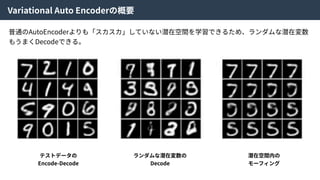
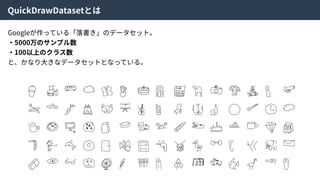
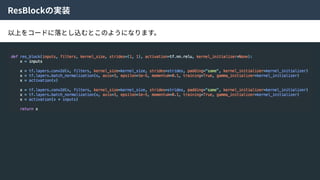
Density ratio trick| Code Discriminator Loss
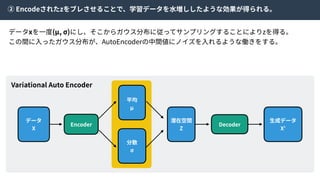
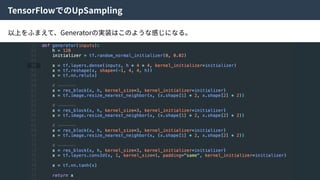
この近似により、
Encoderにより⽣成された特徴量とZからランダムにサンプルされた特徴量を識別する識別器Cω
をつくり、訓練することで特徴空間Zの分布を望みの分布に寄せることができる。
そのため、この識別器をCode Discriminatorと⾔う。
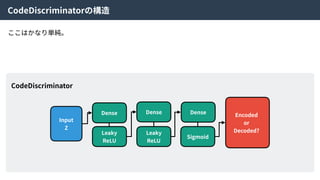
Real Data
X
Encoder
Encoded
Z’
Random
Z
Code
Discriminator
Encoded
or
Random?
Generator
Generated
X’
Discriminator
Real
or
Fake?
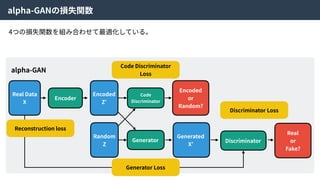
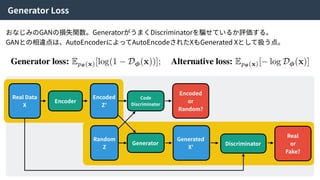
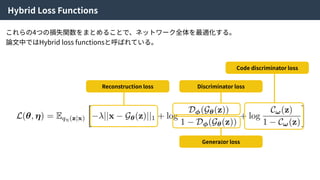
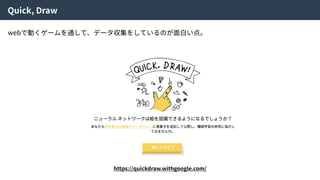
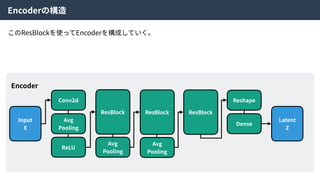
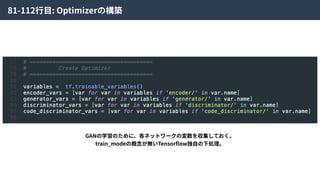
Hybrid Loss Functions
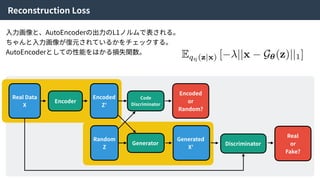
Reconstructionloss Discriminator loss
Generator loss
Code discriminator loss
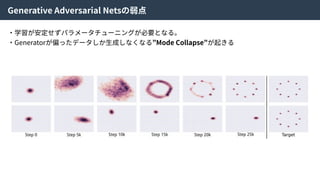
これらの4つの損失関数をまとめることで、ネットワーク全体を最適化する。
論⽂中ではHybrid loss functionsと呼ばれている。
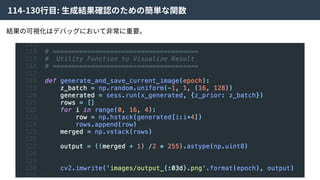
41.
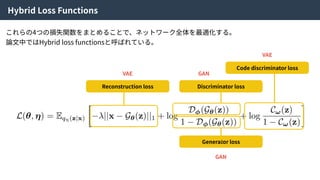
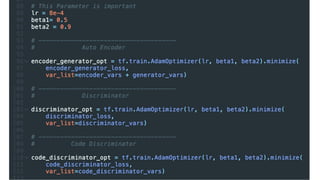
Hybrid Loss Functions
Reconstructionloss Discriminator loss
Generator loss
Code discriminator loss
これらの4つの損失関数をまとめることで、ネットワーク全体を最適化する。
論⽂中ではHybrid loss functionsと呼ばれている。
VAE
GAN
GAN
VAE
![Variational Approaches For Auto-Encoding
Generative Adversarial Networks
Shintaro Murakami, Dentsu Inc.
DEEP LEARNING JP [DL HACKS]](https://image.slidesharecdn.com/alpha-gan-inpl-180417074219/85/DL-Hacks-Variational-Approaches-For-Auto-Encoding-Generative-Adversarial-Networks-1-320.jpg)
![Variational Approaches For Auto-Encoding
Generative Adversarial Networks
Shintaro Murakami, Dentsu Inc.
DEEP LEARNING JP [DL HACKS]](https://image.slidesharecdn.com/alpha-gan-inpl-180417074219/75/DL-Hacks-Variational-Approaches-For-Auto-Encoding-Generative-Adversarial-Networks-1-2048.jpg)




































![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Progressive Growing of GANs for Improved Quality, Stability, and Varia...](https://cdn.slidesharecdn.com/ss_thumbnails/kuboshizuma20180316-180525003941-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会] GAN系の研究まとめ (NIPS2016とICLR2016が中心)](https://cdn.slidesharecdn.com/ss_thumbnails/dliwasawagansurvey-161220014753-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]HoloGAN: Unsupervised learning of 3D representations from natural images](https://cdn.slidesharecdn.com/ss_thumbnails/hologanslideshare-190906010228-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)




















