2017年春季研究発表会の発表資料です. 邦題: 形態素解析も辞書も言語モデルもいらないend-to-end音声認識 英題: End-to-end Japanese ASR without using morphological analyzer, pronunciation dictionary and language model







![© MERL
MITSUBISHI ELECTRIC RESEARCH LABORATORIES
Connectionist temporal classification (CTC)
[Graves+(2006), Graves+(2014), Miao+(2015)]
2016 8
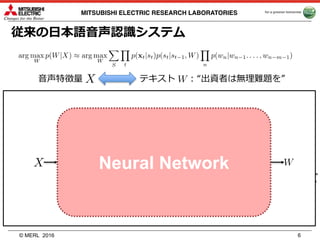
• ⽂字系列:
• 冗⻑表現⽂字系列:
• : HMMと同様の形式, forward-backward algorithm
• 発⾳辞書は不要
• 条件付き独⽴の仮定を利⽤
– 1次マルコフ性を仮定, ⻑期の影響を明⽰的に考慮せず
and
aab, abb, a_b,
ab_, _ab
条件付き独⽴の仮定 2
条件付き独⽴の仮定 3
条件付き独⽴の仮定 1](https://image.slidesharecdn.com/2017merl-170316190016/85/end-to-end-8-320.jpg)
![© MERL
MITSUBISHI ELECTRIC RESEARCH LABORATORIES
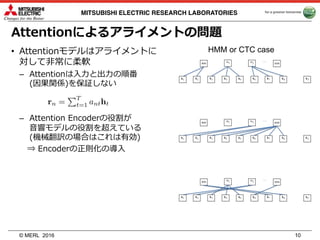
Attention ASR [Chorowski+(2014), Chan+(2015)]
2016 9
連鎖律
• 条件付き独⽴性の仮定が不要
• 発⾳辞書が不要
• Attention & Encoder: ⾳響モデル
• Decoder: ⾔語モデル
⾳響モデルと⾔語モデルを単⼀の
ネットワークで表現!しかし…](https://image.slidesharecdn.com/2017merl-170316190016/85/end-to-end-9-320.jpg)
![© MERL
MITSUBISHI ELECTRIC RESEARCH LABORATORIES
Joint CTC/Attention network [Kim+(2017)]
2016 11
Multitask learning:](https://image.slidesharecdn.com/2017merl-170316190016/85/end-to-end-11-320.jpg)
![© MERL
MITSUBISHI ELECTRIC RESEARCH LABORATORIES
Joint CTC/Attention network [Kim+(2017)]
2016 12
Multitask learning:
ブラックボックスな
ネットワークに
⾳声認識の知識を組み込み](https://image.slidesharecdn.com/2017merl-170316190016/85/end-to-end-12-320.jpg)




























![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DL輪読会]Convolutional Sequence to Sequence Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl0519-170519005603-thumbnail.jpg?width=640&height=640&fit=bounds)










