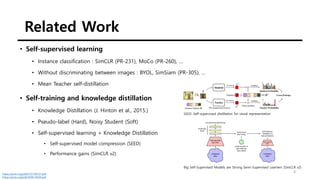
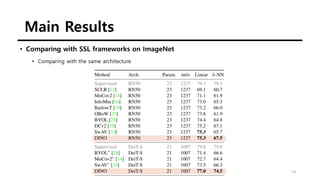
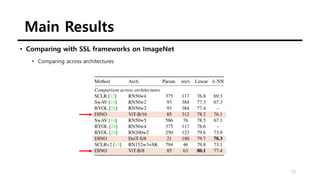
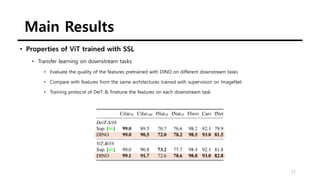
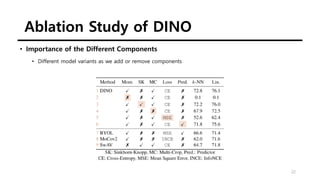
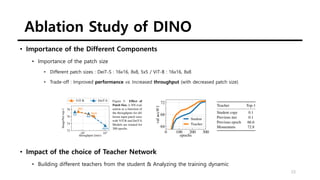
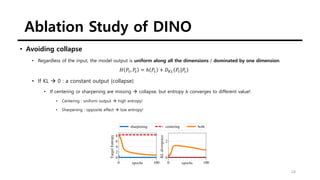
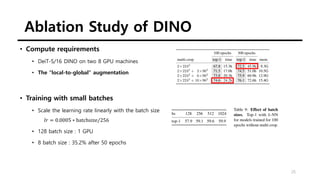
The document summarizes the DINO self-supervised learning approach for vision transformers. DINO uses a teacher-student framework where the teacher's predictions are used to supervise the student through knowledge distillation. Two global and several local views of an image are passed through the student, while only global views are passed through the teacher. The student is trained to match the teacher's predictions for local views. DINO achieves state-of-the-art results on ImageNet with linear evaluation and transfers well to downstream tasks. It also enables vision transformers to discover object boundaries and semantic layouts.




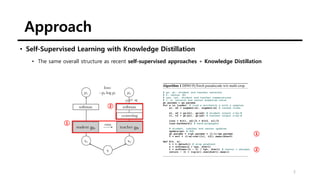




![Approach
11
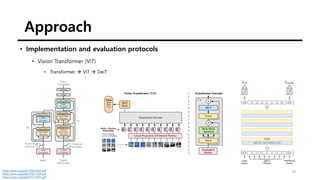
• Implementation and evaluation protocols
• Vision Transformer (ViT)
• N=16 (“/16”) or N=8 (“/8”)
• The patches → linear layer → a set of embeddings
• The class token [CLS] for consistency with previous works
• NOT attached to any label nor supervision](https://image.slidesharecdn.com/210516emergingpropertiesinself-supervisedvisiontransformers-210516144611/85/Emerging-Properties-in-Self-Supervised-Vision-Transformers-11-320.jpg)




















![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Energy-based generative adversarial networks](https://cdn.slidesharecdn.com/ss_thumbnails/energy-basedgenerativeadversarialnetworks-171030102253-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)


































































