Download as PDF, PPTX

![概要
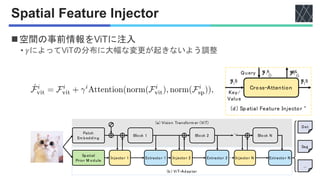
◼Vision Transformer (ViT) [Dosovitskiy+, ICLR 2021]を
密な画像タスクに適応するためのアダプタの提案
• 従来のモデルのバックボーンは画像に特化
• 提案手法ではシンプルなViTを使用
• 提案手法はマルチモーダルなバックボーンでも可
this issue, we propose the ViT-Adapter, which allows plain ViT to achieve com-
parable performance to vision-specific transformers. Specifically, the backbone
in our framework is a plain ViT that can learn powerful representations from
large-scale multi-modal data. W hen transferring to downstream tasks, a pre-
training-free adapter is used to introduce the image-related inductive biases into
the model, making it suitable for these tasks. We verify ViT-Adapter on mul-
tiple dense prediction tasks, including object detection, instance segmentation,
and semantic segmentation. Notably, without using extra detection data, our ViT-
Adapter-L yields state-of-the-art 60.9 box AP and 53.0 mask AP on COCO test-
dev. We hope that the ViT-Adapter could serve asan alternative for vision-specific
transformers and facilitate future research. Code and models will be released at
ht t ps: //gi t hub. com/czczup/Vi T- Adapt er .
Step1: Im ag e M odality Pre-training
Step2: Fine-tuning
(a) Previous Parad ig m
Vision-Specific
Transform er
COCO
ADE20K
Det/Seg
Vision-Specific
Transform er
Im ag e
M odality
SL/SSL
Step1: M ulti-M odal Pre-training
Step2: Fine-tuning with Adapter
(b) Our Parad ig m
ViT
Im ag e,
Video, Text, ...
SL/SSL
COCO
ADE20K
ViT
Adapter
Det/Seg](https://image.slidesharecdn.com/20231130visiontransformeradapterfordensepredictions-231222063439-60f53862/85/Vision-Transformer-Adapter-for-Dense-Predictions-2-320.jpg)
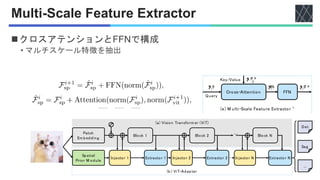
![関連研究
◼密な画像タスクでは複数スケールの特徴を扱う
◼ViTDet [Li+, arXiv2022]
• アップサンプリングとダウンサンプリング
◼提案手法
• アダプタによって入力画像も考慮](https://image.slidesharecdn.com/20231130visiontransformeradapterfordensepredictions-231222063439-60f53862/85/Vision-Transformer-Adapter-for-Dense-Predictions-3-320.jpg)


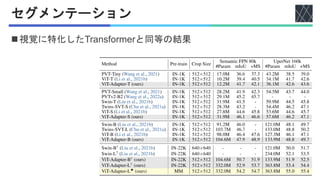
![実験
◼タスクとデータセット
• オブジェクト検出
• COCO [Lin+, ECCV2014]
• インスタンスセグメンテーション
• ADE20K [Zhou+, CVPR2017]
◼モデル
• ViT
• ImageNet 1K/ 22Kで事前学習](https://image.slidesharecdn.com/20231130visiontransformeradapterfordensepredictions-231222063439-60f53862/85/Vision-Transformer-Adapter-for-Dense-Predictions-8-320.jpg)





This document presents the vit-adapter, a method that enhances the Vision Transformer (ViT) for dense image prediction tasks, allowing it to match the performance of vision-specific transformers. It incorporates a pre-training-free adapter that introduces image-related biases into the model and has shown state-of-the-art results in object detection and segmentation tasks without using extra detection data. The study emphasizes the effectiveness of multi-modal pre-training and the potential of the vit-adapter as an alternative for vision-specific transformers.






![[DL輪読会]Object-Centric Learning with Slot Attention](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0717-200717023021-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20190621dlhack-190621022108-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-04] Human-in-the-Loop 機械学習](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-04-220607021031-e69700d5-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)








![[論文紹介] BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/blendedmvsslideshare-200630044345-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Generative Models of Visually Grounded Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20170602-170602005505-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] Multiscale Vision Transformers(MVit)](https://cdn.slidesharecdn.com/ss_thumbnails/papermultiscalevisiontransformers-210808092058-thumbnail.jpg?width=640&height=640&fit=bounds)














































