[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
1.
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
Makoto Kawano, Keio University
タスク1:Masked Language Model
●pre-traininig時とfine-tuning時で違いが生じてしまう
‣Fine-tuningの時に[MASK]トークンは見ない
‣ 常に置換するのではなく,系列のうち15%の単語を置き換える
• 例:my dog is hairy -> hairyが選択される
• 80%:[MASK]トークンに置換
• my dog is hairy -> my dog is [MASK]
• 10%:ランダムな別の単語に置換
• my dog is hairy -> my dog is apple
• 10%:置き換えない(モデルに実際に観測される言葉表現に偏らせる)
• my dog is hairy -> my dog is hairy
14
![DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
Makoto Kawano, Keio University](https://image.slidesharecdn.com/dlreadingpaper20181019-181019010218/85/DL-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-1-320.jpg)
![DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
Makoto Kawano, Keio University](https://image.slidesharecdn.com/dlreadingpaper20181019-181019010218/75/DL-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-1-2048.jpg)




![Feature-basedアプローチ
●様々なNLPタスクの素性として利用される
‣ N-gramモデル[Brown et al., 1992]やWord2Vec[Mikolov et al., 2013]
• 文や段落レベルの分散表現に拡張されたものある
‣ タスクに合わせて学習させると性能向上[Turian et al., 2010]
●最近では,ELMo[Peters et al., 2017, 2018]が話題に
‣ Context-Sensitiveな素性を獲得
‣ 複数のNLPタスクでSOTA
• QA,極性分類,エンティティ認識
‣ 既存の素性にConcatすると精度UP
6](https://image.slidesharecdn.com/dlreadingpaper20181019-181019010218/85/DL-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-6-320.jpg)
![ELMo [Peters et al., 2017, 2018]
●BiLSTMをL層積んで,各隠れ層を加重平均する
●獲得したELMoをNLPタスクの入力および隠れ層に連結するだけ
7
or](https://image.slidesharecdn.com/dlreadingpaper20181019-181019010218/85/DL-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-7-320.jpg)
![Transformer[Ł.Kaiser et al., arXiv,2017]
●有名なXXX is All You Needの先駆者(今回はAttention)
●RNN構造ではなく,Attention機構のみで構成
●Encoder-Decoderで構成されている
‣ 左側:Transformer-Encoder
‣ 右側:Transformer-Decoder
●Transformerって結局?
‣ Multi-Head AttentionとPosition-wise FFNの集合体
(より詳細は@_Ryobotさんのブログhttp://deeplearning.hatenablog.com/entry/transformerでお願いします)
8](https://image.slidesharecdn.com/dlreadingpaper20181019-181019010218/85/DL-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-8-320.jpg)
![Fine-tuningアプローチ
●言語モデルの目的関数で事前学習する
‣ そのあと教師ありタスクでfine-tuningする
‣ 少ないパラメータで学習することが可能(らしい,,,)
●最近では,OpenAI GPT[Radford et al. 2018]
‣ GLUEスコアでSOTA
‣ TransformerのDecoderだけを利用[Liu et al., 2018]
• 単方向のモデル
9](https://image.slidesharecdn.com/dlreadingpaper20181019-181019010218/85/DL-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-9-320.jpg)

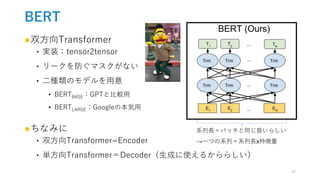
![入力表現:一つの文章or文章のペア(QAなど)
●三種類の埋め込みの合計(sum≠concat)
‣ トークン埋め込み:30000種類のWordPiece埋め込み
• 分割されたところは「##」で表現
‣ 単語位置埋め込み:系列長1〜512個の表現
• 位置0には,[CLS]トークンを追加→系列分類問題ではこの埋め込みを利用
‣ 文区別埋め込み:QAなどの場合の話
• 一文の時はAのみ
12](https://image.slidesharecdn.com/dlreadingpaper20181019-181019010218/85/DL-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-12-320.jpg)

![タスク1:Masked Language Model
●pre-traininig時とfine-tuning時で違いが生じてしまう
‣ Fine-tuningの時に[MASK]トークンは見ない
‣ 常に置換するのではなく,系列のうち15%の単語を置き換える
• 例:my dog is hairy -> hairyが選択される
• 80%:[MASK]トークンに置換
• my dog is hairy -> my dog is [MASK]
• 10%:ランダムな別の単語に置換
• my dog is hairy -> my dog is apple
• 10%:置き換えない(モデルに実際に観測される言葉表現に偏らせる)
• my dog is hairy -> my dog is hairy
14](https://image.slidesharecdn.com/dlreadingpaper20181019-181019010218/85/DL-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-14-320.jpg)



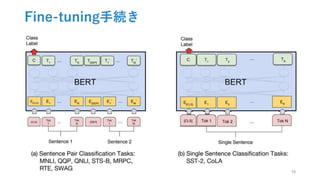
![Fine-tuning手続き
●系列レベルの分類問題
‣ 固定長の分散表現C∈RHを獲得するため,最初の[CLS]トークンを使う
‣ 新しく追加する層は分類層W∈RKxH+ソフトマックス層のみ
‣ BERTも一緒に学習させる
●スパンorトークンレベルの分類問題
‣ 各タスクの仕様に合わせて学習させる
●バッチサイズ,学習率,エポック数のみ変更
‣ ドロップアウト:常に0.1
‣ 10万以上のラベル付きデータセットの場合はそこまで気にしなくていい
‣ Fine-tuningは高速でできるため,パラメータ探索すべき
18](https://image.slidesharecdn.com/dlreadingpaper20181019-181019010218/85/DL-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-18-320.jpg)

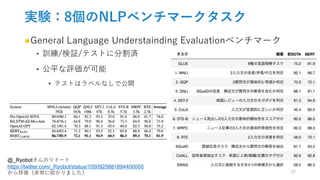

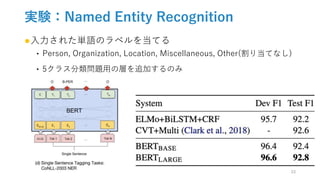
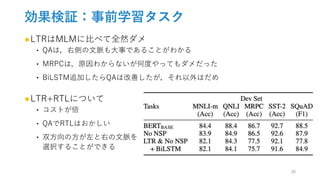
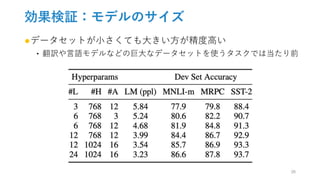
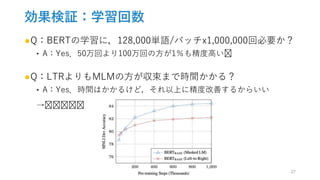
![効果検証:事前学習タスク
●No NSP:MLMを学習させるだけ
●LTR&No NSP:MLMもなし=left-to-right言語モデルで学習
‣ Pre-training時:マスクなし, fine-tuning時:左からの情報のみ
• 別のパターンも試したけど,精度下がりすぎて意味がなかった
‣ OpenAI GPTと比較することが可能
• データセットの違い:GPTはBooksCorpusのみ
• 入力表現の違い:GPTは[CLS][SEP]はfine-tuningのみ&文区別表現なし
• Fine-tuning戦略:バッチに含まれる単語やパラメータ探索なし
24](https://image.slidesharecdn.com/dlreadingpaper20181019-181019010218/85/DL-BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-24-320.jpg)





![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)








![[FUNAI輪講] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/bert-190625044118-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL Hacks]BERT: Pre-training of Deep Bidirectional Transformers for Language ...](https://cdn.slidesharecdn.com/ss_thumbnails/20181129suzukibert1-181204064830-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL Hacks]Pretraining-Based Natural Language Generation for Text Summarizatio...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspretraining-basednaturallanguagegenerationfortextsummarization-190422070150-thumbnail.jpg?width=640&height=640&fit=bounds)



![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)






















