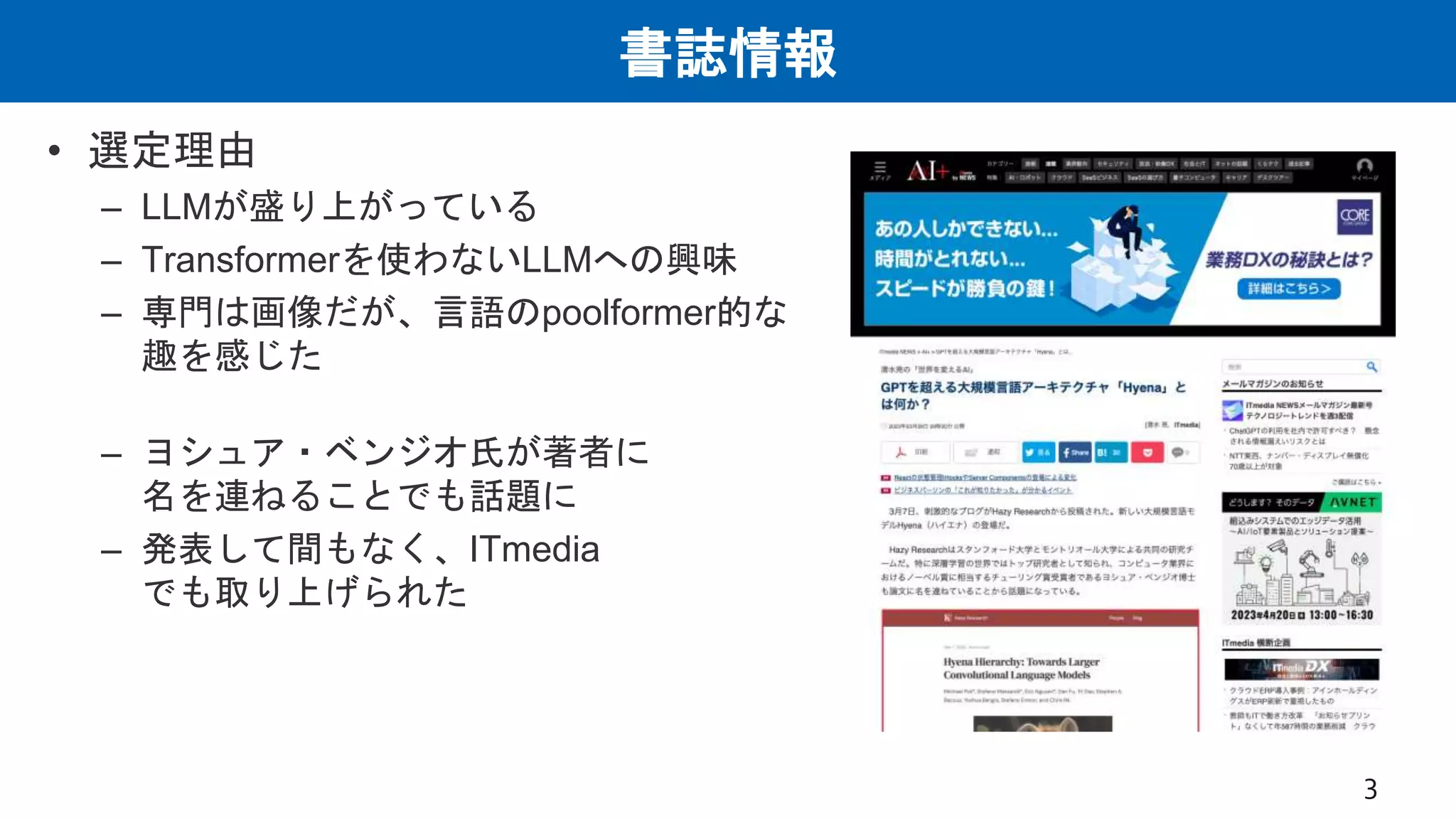
関連研究
• Attentionの計算コスト削減
– 線形化や低ランク行列の積、スパース化による近似
(Childet al., 2019; Wang et al., 2020; Kitaev et al., 2020; Zhai et al., 2021; Roy et al., 2021;
Schlag et al., 2021; Tu et al., 2022)
– 計算量と表現力はトレードオフ
(Mehta et al., 2022; Dao et al., 2022c)
• Attentionの演算子としての冗長性
– Attention機構が言語処理に利用しているのは、
二次的な能力のほんの一部とする証拠が増えている
(Olsson et al., 2022; Dao et al., 2022c)
5




![関連研究(補足)
• Swin Transformer [Ze Liu et al. 2021]
– 省コストなViT
– 階層的な特徴表現により、入力画像サイズに対して線形な計算量
– 過去の輪読会でも紹介
https://www.slideshare.net/DeepLearningJP2016/dlswin-transformer-hierarchical-vision-transformer-using-shifted-windows
• Reformer [Nikita et al. 2020]
– 性能を保ちながらTransformerの効率を向上させるために2つの技術を導入
• ハッシュトリックを用いて 𝑂(𝐿2
) から 𝑂(𝐿𝑙𝑜𝑔𝐿) に
– ドット積アテンションを局所性を考慮したハッシュ関数で置き換え
• 標準的な残差の代わりに可逆的な残差層を使用
6](https://image.slidesharecdn.com/20230331dl-230410031231-28b7a2c2/75/DL-Hyena-Hierarchy-Towards-Larger-Convolutional-Language-Models-6-2048.jpg)









![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)















































