【メタサーベイ】Transformerから基盤モデルまでの流れ / From Transformer to Foundation Models
1.
From Transformer toFoundation Models
Transformerから基盤モデルまでの流れ
cvpaper.challenge
1
http://xpaperchallenge.org/cv
2.
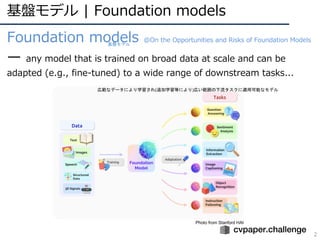
基盤モデル | Foundationmodels
2
Foundation models @On the Opportunities and Risks of Foundation Models
̶ any model that is trained on broad data at scale and can be
adapted (e.g., fine-tuned) to a wide range of downstream tasks...
広範なデータにより学習され(追加学習等により)広い範囲の下流タスクに適用可能なモデル
基盤モデル
Photo from Stanford HAI
3.
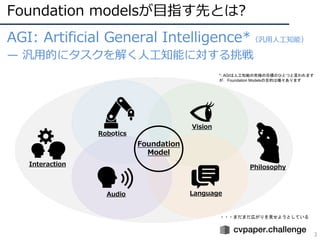
Foundation modelsが⽬指す先とは?
3
AGI: ArtificialGeneral Intelligence*(汎⽤⼈⼯知能)
̶ 汎⽤的にタスクを解く⼈⼯知能に対する挑戦
Robotics
Vision
Language
Audio
Foundation
Model
Philosophy
Interaction
・・・まだまだ広がりを見せようとしている
*: AGIは人工知能の究極の目標のひとつと言われます
が,Foundation Modelsの目的は種々あります
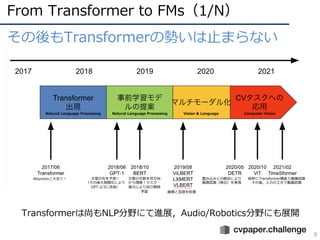
From Transformer toFMs(1/N)
5
⾃然⾔語処理 (NLP)分野でTransformerが提案
● Transformer
● Self-attention (⾃⼰注視)機構により系
列データを⼀括処理
● “Attention Is All You Need”とタイトル
を名付けるくらいには衝撃的だった
● 学習時間短縮・性能向上を同時に実現
【Why Transformer?】
Transformerの提案論⽂ “Attention Is All You
Need”(NIPS 2017)にて,機械翻訳タスク(Neural
Machine Translation; NMT)を⾼度に解いたモデル
だからだと思っているのですが諸説あり︖
Transformerについてはこちらも参照
https://www.slideshare.net/cvpaperchallenge/transformer-247407256
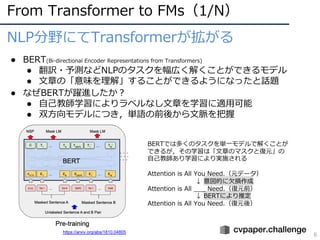
6.
From Transformer toFMs(1/N)
6
NLP分野にてTransformerが拡がる
● BERT(Bi-directional Encoder Representations from Transformers)
● 翻訳・予測などNLPのタスクを幅広く解くことができるモデル
● ⽂章の「意味を理解」することができるようになったと話題
● なぜBERTが躍進したか︖
● ⾃⼰教師学習によりラベルなし⽂章を学習に適⽤可能
● 双⽅向モデルにつき,単語の前後から⽂脈を把握
https://arxiv.org/abs/1810.04805
BERTでは多くのタスクを単⼀モデルで解くことが
できるが,その学習は「⽂章のマスクと復元」の
⾃⼰教師あり学習により実施される
Attention is All You Need.(元データ)
↓ 意図的に⽋損作成
Attention is All ___ Need.(復元前)
↓ BERTにより推定
Attention is All You Need.(復元後)




![From Transformer to FMs(1/N)
9
Vision Transformer(ViT)
● 純Transformer構造により画像認識
● 画像パッチを単語と⾒なして処理
● Encoderのみ使⽤ / MLPを通して出⼒
● ViTの後にも亜種が登場
● CNN + Transformer: CvT, ConViT(擬似畳込み),
CMT, CoAtNet
● MLP: MLP-Mixer, gMLP
● ViT: DeiT, Swin Transformer ViT [Dosovitskiy+, ICLR21]
【Vision Transformer】
【Swin Transformer V1/V2】
Swin Transformer V1 [Liu+, ICCV21]
Swin Transformer V2 [Liu+, CVPR22]](https://image.slidesharecdn.com/foundation-models-v0-220824224423-a6745788/85/Transformer-From-Transformer-to-Foundation-Models-9-320.jpg)
![From Transformer to FMs(1/N)
10
ViTでも自己教師あり学習できることを実証
● ViTでは教師あり学習 @ ImageNet-1k/22k, JFT-300MGoogleが誇る3億のラベル付画像データ
● 最初はContrastive Learning (対照学習)が提案・使⽤
● SimCLR / MoCo / DINOいずれもViTを学習可能
SimCLR [Chen+, ICML20] DINO [Caron+, ICCV21]
⾃⼰教師あり学習ではContrastive Learningが主流の1つ(だった)
Transformerへ適⽤する研究も多数
MoCo [He+, CVPR20]](https://image.slidesharecdn.com/foundation-models-v0-220824224423-a6745788/85/Transformer-From-Transformer-to-Foundation-Models-10-320.jpg)
![From Transformer to FMs(1/N)
11
ViTにおける自己教師あり学習の真打ち!?
● “ViTでBERTする” Masked AutoEncoder (MAE)
● 画像・⾔語・⾳声の⾃⼰教師あり学習 Data2vec
MAE [He+, CVPR22]
Data2vec [Baevski+, arXiv22]
どちらも「マスクして復元」という⽅法論
● MAEは画像における⾃⼰教師あり学習
● Data2vecは3つのモダリティ(但しFTは個別)
● 今後,基盤モデルのための⾃⼰教師あり学習が登場す
る可能性は⼤いにある](https://image.slidesharecdn.com/foundation-models-v0-220824224423-a6745788/85/Transformer-From-Transformer-to-Foundation-Models-11-320.jpg)
















![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)



















