Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
651 views
[DL輪読会]representation learning via invariant causal mechanisms
2021/09/10 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 15 times
1
/ 21
2
/ 21
3
/ 21
4
/ 21
5
/ 21
6
/ 21
7
/ 21
8
/ 21
9
/ 21
10
/ 21
11
/ 21
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
18
/ 21
19
/ 21
20
/ 21
21
/ 21
More Related Content
PPTX
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PPTX
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
PDF
生成モデルの Deep Learning
by
Seiya Tokui
PDF
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
PDF
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
深層生成モデルと世界モデル
by
Masahiro Suzuki
[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination
by
Deep Learning JP
生成モデルの Deep Learning
by
Seiya Tokui
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
What's hot
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
PPTX
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
PPTX
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
PDF
【DL輪読会】Hierarchical Text-Conditional Image Generation with CLIP Latents
by
Deep Learning JP
PPTX
【DL輪読会】Visual Classification via Description from Large Language Models (ICLR...
by
Deep Learning JP
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
PDF
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PDF
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
by
Deep Learning JP
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
PPTX
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
PPTX
Deep Learning による視覚×言語融合の最前線
by
Yoshitaka Ushiku
PPTX
[DL輪読会]When Does Label Smoothing Help?
by
Deep Learning JP
PDF
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
PDF
Variational AutoEncoder
by
Kazuki Nitta
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder
by
Deep Learning JP
[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing
by
Deep Learning JP
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
勾配ブースティングの基礎と最新の動向 (MIRU2020 Tutorial)
by
RyuichiKanoh
【DL輪読会】Hierarchical Text-Conditional Image Generation with CLIP Latents
by
Deep Learning JP
【DL輪読会】Visual Classification via Description from Large Language Models (ICLR...
by
Deep Learning JP
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...
by
Deep Learning JP
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
Deep Learning による視覚×言語融合の最前線
by
Yoshitaka Ushiku
[DL輪読会]When Does Label Smoothing Help?
by
Deep Learning JP
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
Variational AutoEncoder
by
Kazuki Nitta
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
Similar to [DL輪読会]representation learning via invariant causal mechanisms
PPTX
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
PDF
[DL輪読会]Relational inductive biases, deep learning, and graph networks
by
Deep Learning JP
PPTX
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
PDF
[DL輪読会]Causality Inspired Representation Learning for Domain Generalization
by
Deep Learning JP
PPTX
【DL輪読会】Emergent World Representations: Exploring a Sequence ModelTrained on a...
by
Deep Learning JP
PDF
グラフニューラルネットワークとグラフ組合せ問題
by
joisino
PDF
[DL輪読会]Fast and Slow Learning of Recurrent Independent Mechanisms
by
Deep Learning JP
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
PDF
Deep learning勉強会20121214ochi
by
Ohsawa Goodfellow
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PDF
ゼロから作るDeepLearning 4章 輪読
by
KCS Keio Computer Society
PPTX
[DL輪読会]Adversarial Representation Active Learning
by
Deep Learning JP
PDF
論文紹介:Relational inductive biases, deep learning, and graph networks
by
Tatsuhiko Kato
PPTX
[DL輪読会] Learning Finite State Representations of Recurrent Policy Networks (I...
by
Deep Learning JP
PPTX
"Universal Planning Networks" and "Composable Planning with Attributes"
by
Yusuke Iwasawa
PDF
dl-with-python01_handout
by
Shin Asakawa
PPTX
Cvim saisentan-6-4-tomoaki
by
tomoaki0705
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
Generative deeplearning #02
by
逸人 米田
[DL輪読会]相互情報量最大化による表現学習
by
Deep Learning JP
[DL輪読会]Relational inductive biases, deep learning, and graph networks
by
Deep Learning JP
[DL輪読会]Temporal DifferenceVariationalAuto-Encoder
by
Deep Learning JP
[DL輪読会]Causality Inspired Representation Learning for Domain Generalization
by
Deep Learning JP
【DL輪読会】Emergent World Representations: Exploring a Sequence ModelTrained on a...
by
Deep Learning JP
グラフニューラルネットワークとグラフ組合せ問題
by
joisino
[DL輪読会]Fast and Slow Learning of Recurrent Independent Mechanisms
by
Deep Learning JP
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
Deep learning勉強会20121214ochi
by
Ohsawa Goodfellow
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
ゼロから作るDeepLearning 4章 輪読
by
KCS Keio Computer Society
[DL輪読会]Adversarial Representation Active Learning
by
Deep Learning JP
論文紹介:Relational inductive biases, deep learning, and graph networks
by
Tatsuhiko Kato
[DL輪読会] Learning Finite State Representations of Recurrent Policy Networks (I...
by
Deep Learning JP
"Universal Planning Networks" and "Composable Planning with Attributes"
by
Yusuke Iwasawa
dl-with-python01_handout
by
Shin Asakawa
Cvim saisentan-6-4-tomoaki
by
tomoaki0705
Deep Learningの基礎と応用
by
Seiya Tokui
Generative deeplearning #02
by
逸人 米田
More from Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
[DL輪読会]representation learning via invariant causal mechanisms
1.
DEEP LEARNING JP [DL
Papers] Representation Learning via Invariant Causal Mechanisms XIN ZHANG, Matsuo Lab http://deeplearning.jp/
2.
書誌情報 ● Representation Learning
via Invariant Causal Mechanisms ● 著者:Jovana Mitrovic, Brian McWilliams, Jacob Walker, Lars Buesing, Charles Blundell ● 研究機関:DeepMind, Oct 2020(Arxiv) ● 概要 ○ Contrastive Learning(CL)が上手くいっている理由を因果論で解釈する論文 ○ データ拡張に注目して、画像のStyleがdowntasksに影響しないため(仮説のもとで)、 事前学習のTaskにおいても影響しないようにすれば良い ○ CLのLoss関数に、Styleによる影響を抑える制限を加える ○ 学習した表現の良さは、Baselineと同等だが、ロバスト性や汎化性が優れている 2
3.
Introduction:Representation Learning
4.
Representation Learning via
Invariant Causal Mechanisms
5.
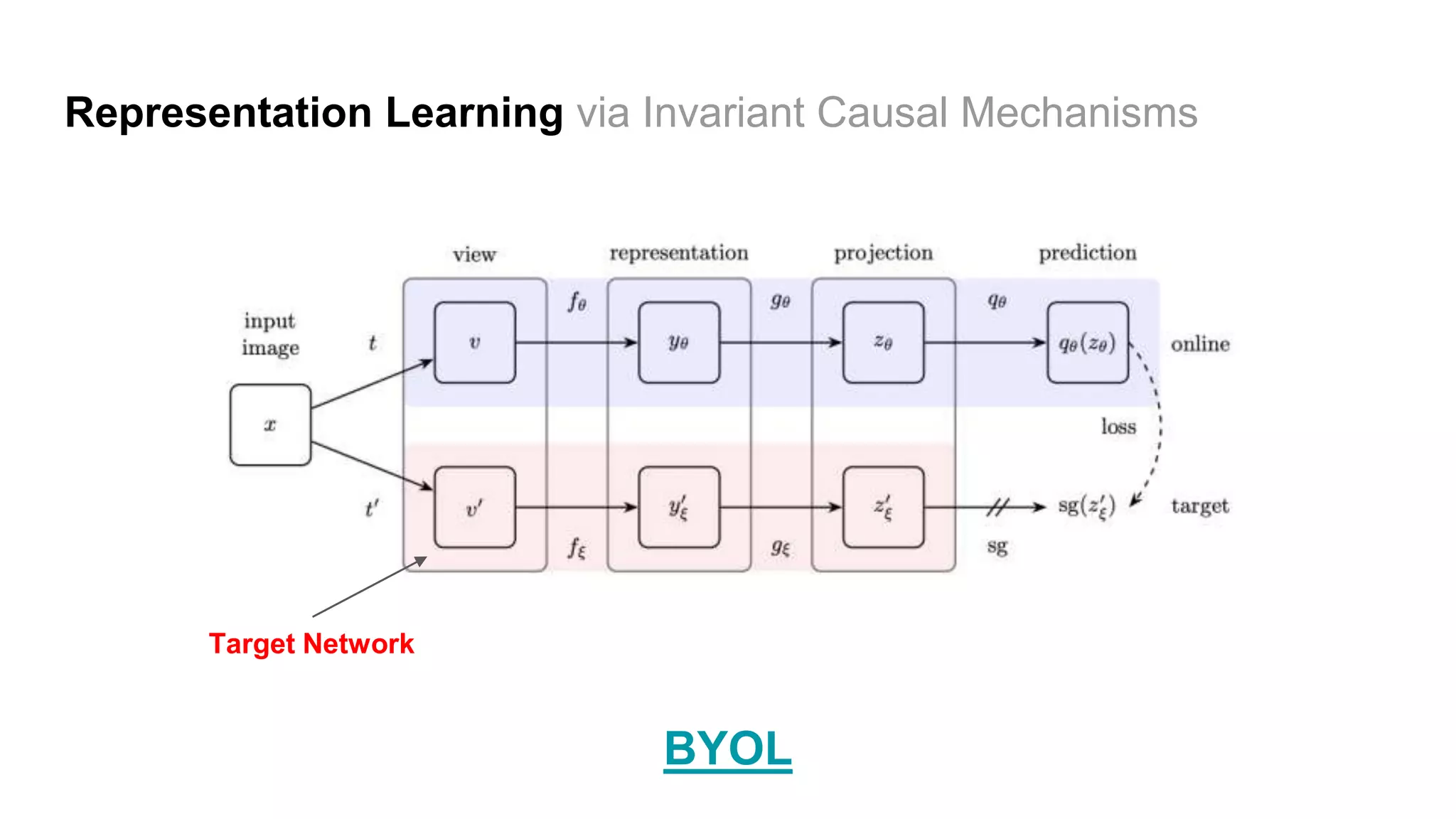
BYOL Representation Learning via
Invariant Causal Mechanisms Target Network
6.
Reprensentation(Self-supervised) learningはMIだけでは解釈でき ない [DL輪読会]相互情報量最大化による表現学習、岩澤先生より
7.
Representation Learning via
Invariant Causal Mechanisms Alignment and Uniformity on the Hypersphere
8.
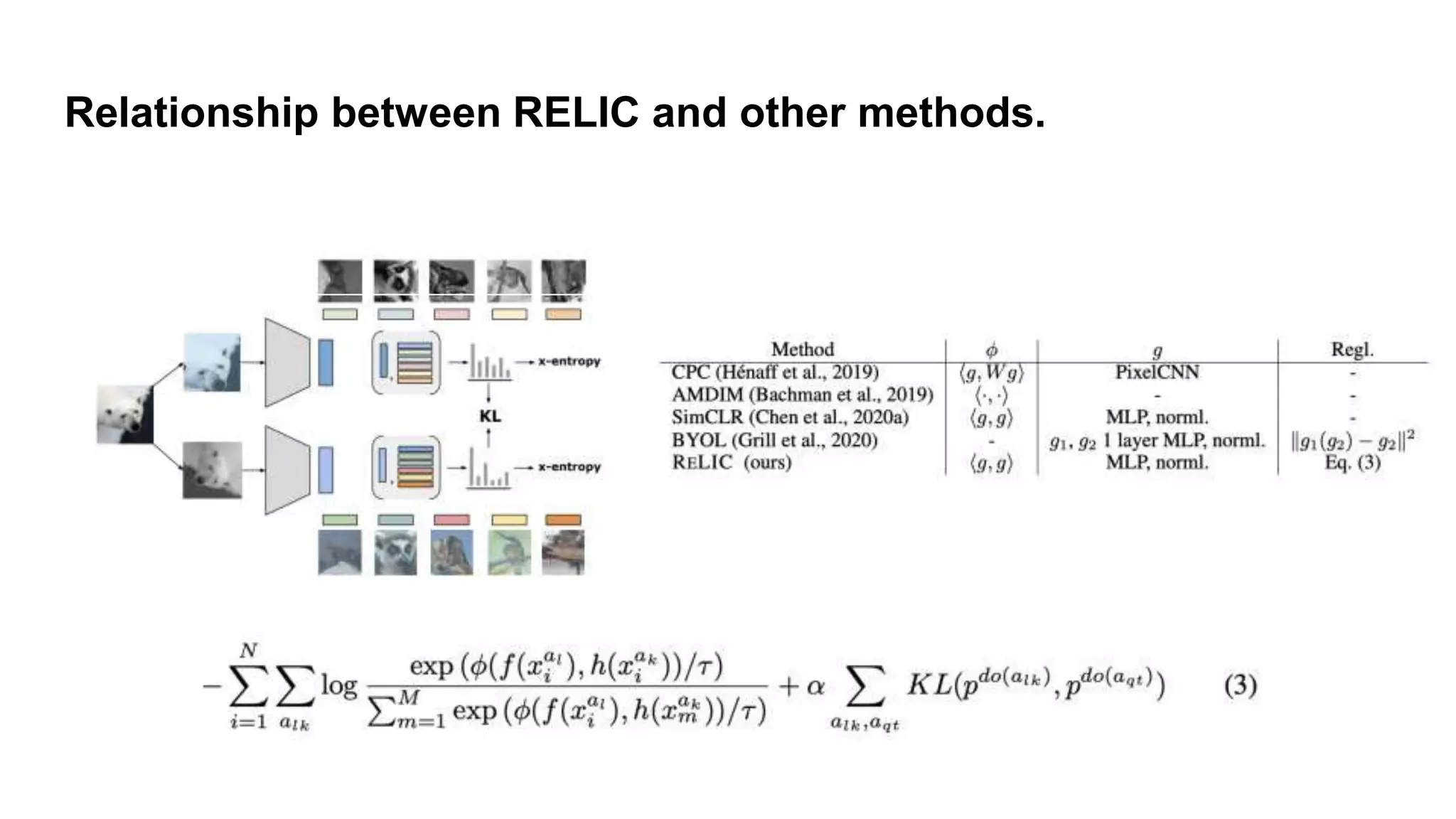
Proposed method:RELIC
9.
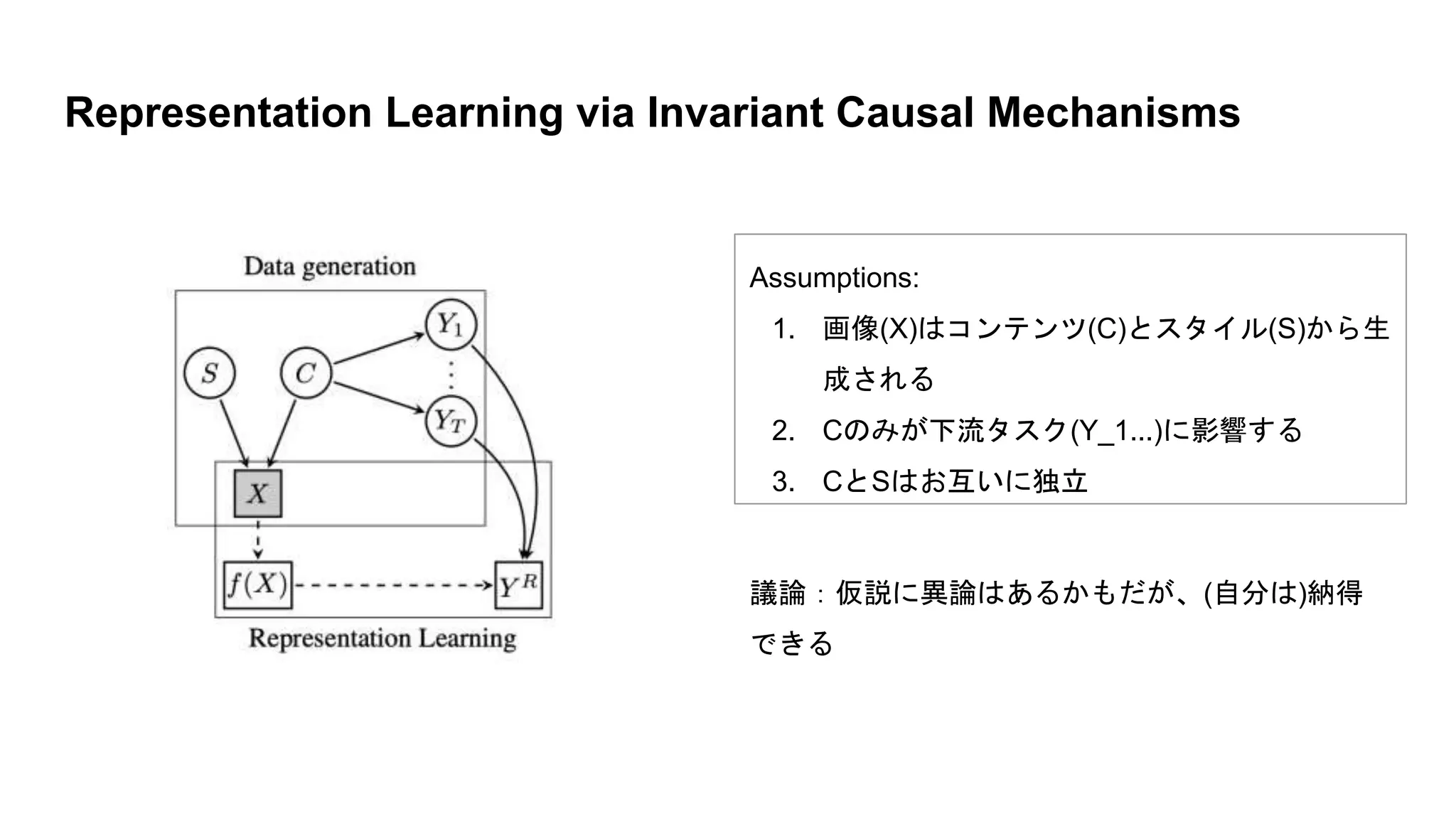
議論:仮説に異論はあるかもだが、(自分は)納得 できる Representation Learning via
Invariant Causal Mechanisms Assumptions: 1. 画像(X)はコンテンツ(C)とスタイル(S)から生 成される 2. Cのみが下流タスク(Y_1...)に影響する 3. CとSはお互いに独立
10.
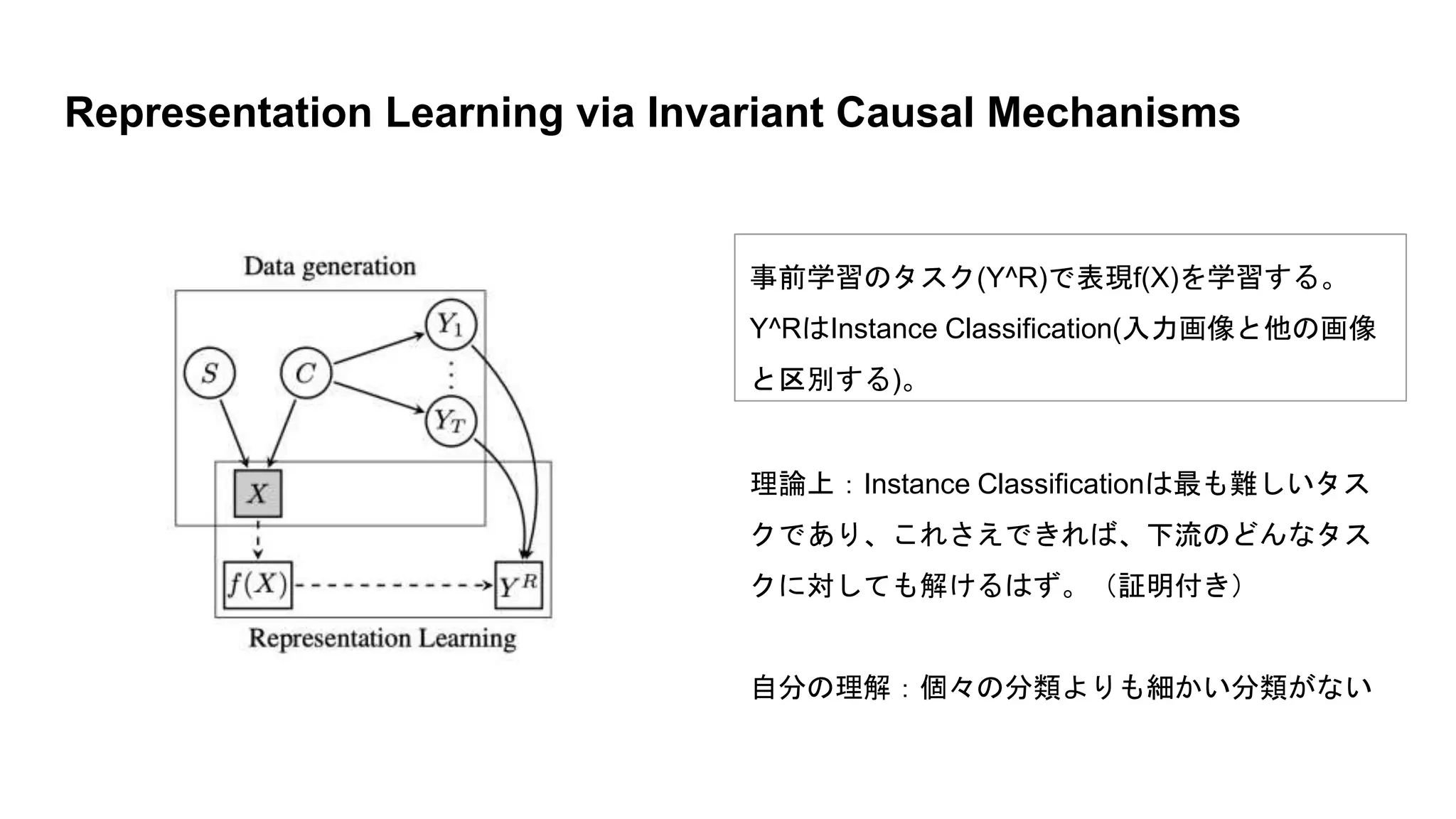
理論上:Instance Classificationは最も難しいタス クであり、これさえできれば、下流のどんなタス クに対しても解けるはず。(証明付き) 自分の理解:個々の分類よりも細かい分類がない Representation Learning
via Invariant Causal Mechanisms 事前学習のタスク(Y^R)で表現f(X)を学習する。 Y^RはInstance Classification(入力画像と他の画像 と区別する)。
11.
Representation Learning via
Invariant Causal Mechanisms Y^Rでf(X)で事前学習する際に、Sの変化による影 響を無くすように制限をかける。
12.
Relationship between RELIC
and other methods.
13.
EXPERIMENTS
14.
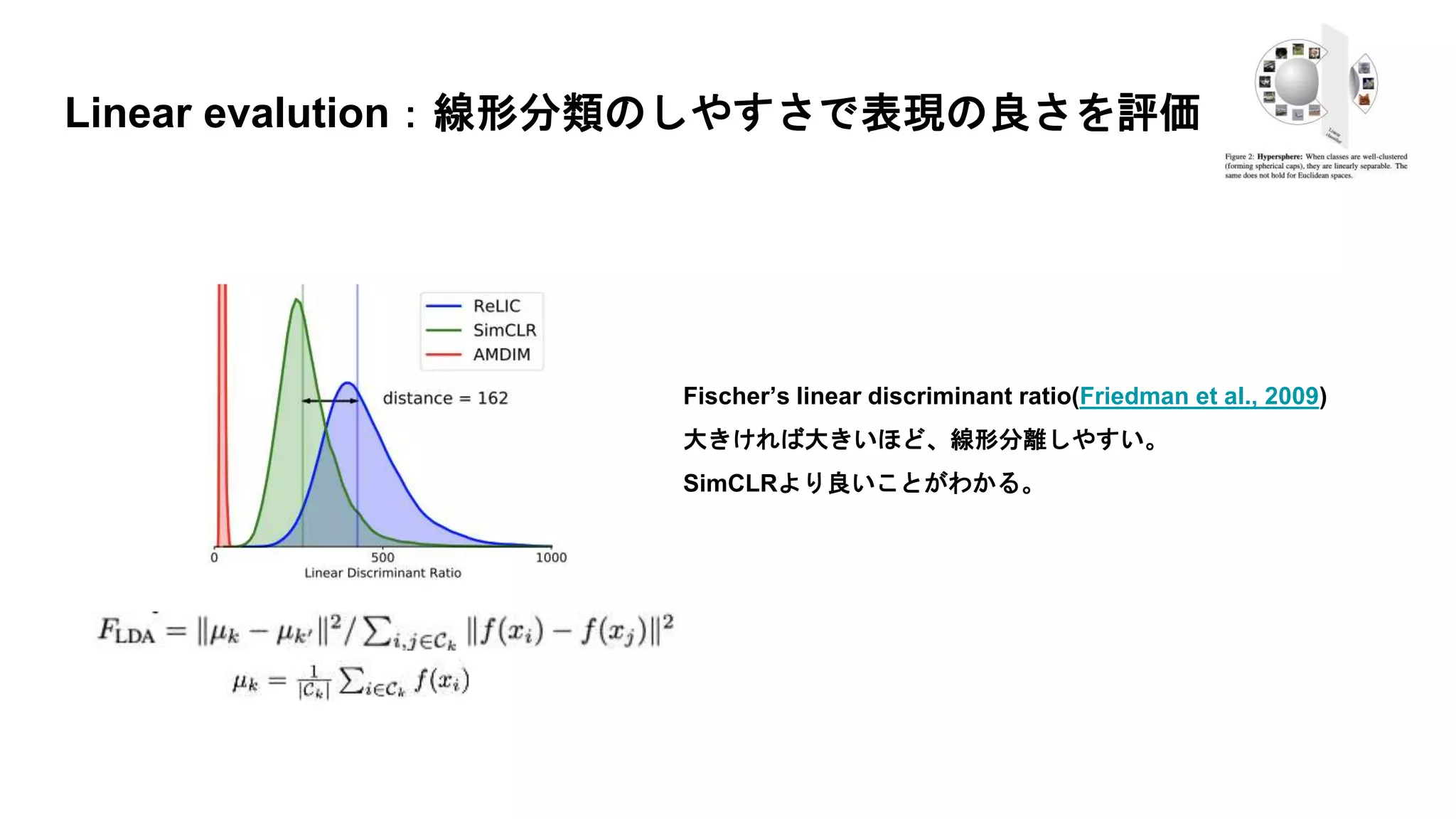
Linear evalution:線形分類のしやすさで表現の良さを評価 Fischer’s linear
discriminant ratio(Friedman et al., 2009) 大きければ大きいほど、線形分離しやすい。 SimCLRより良いことがわかる。
15.
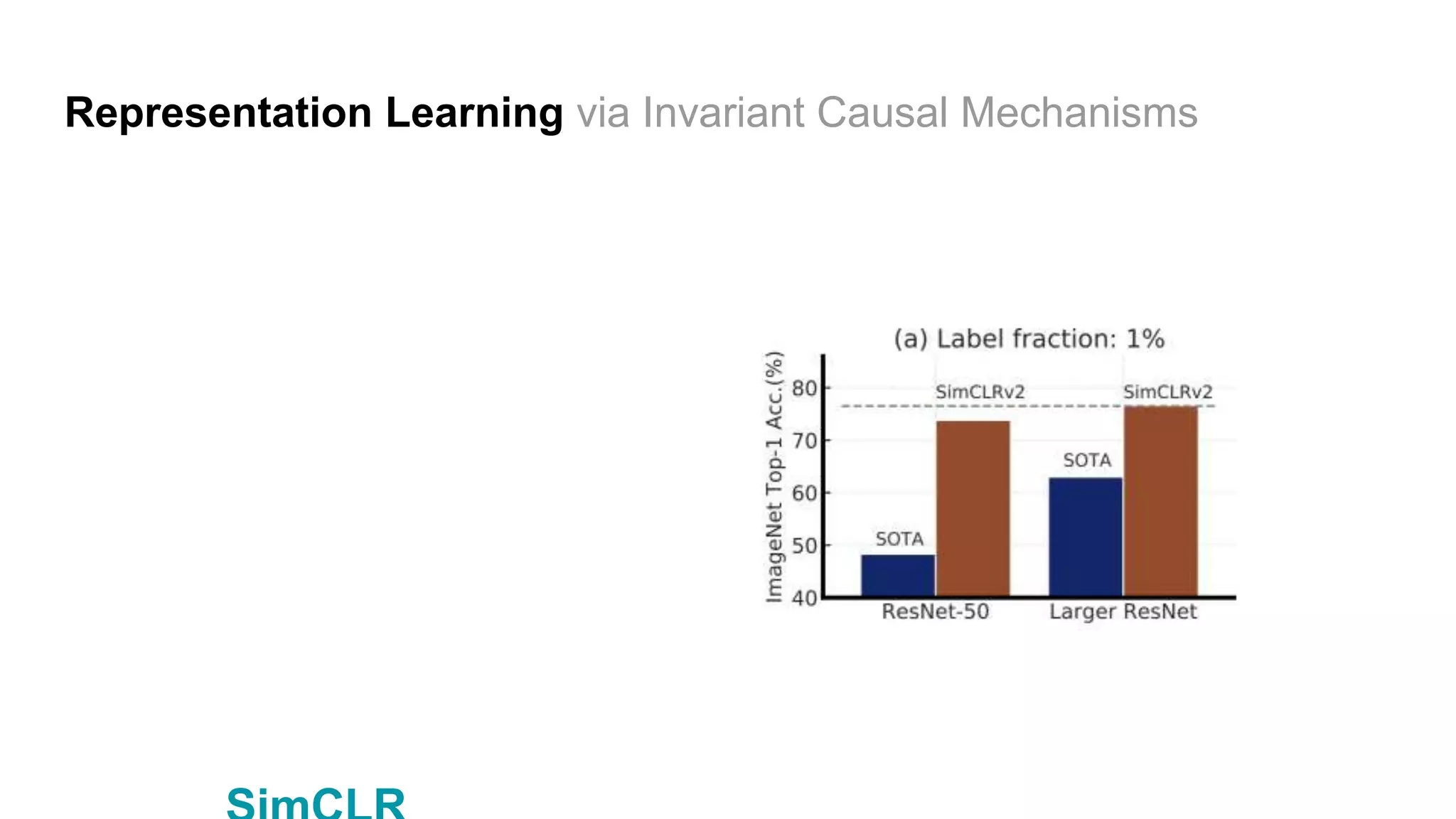
Linear evalution:ImageNetで線形評価を行う(スタンダード) 2種類のArchitectureで、それぞれSOTAと同等程度な精度 - ただし、InfoMin
AugとSwAVはより強力データ拡張を使 った。(5%ほど精度上げられるもの) 議論:より強力データ拡張を使った結果は気になる
16.
ImageNet-R:ImageNetの画像を拡張したデータセット。 Top-1 Error%がSimCLRより低く、Supervisedより高い。 Robustness and
Generalization
17.
Robustness and Generalization ImageNet-C:ImageNetの画像に異なる程度な異なるノイズを 加えたデータセット。 複数のError率では、SimCLRとBYOLより低い(良い)。
18.
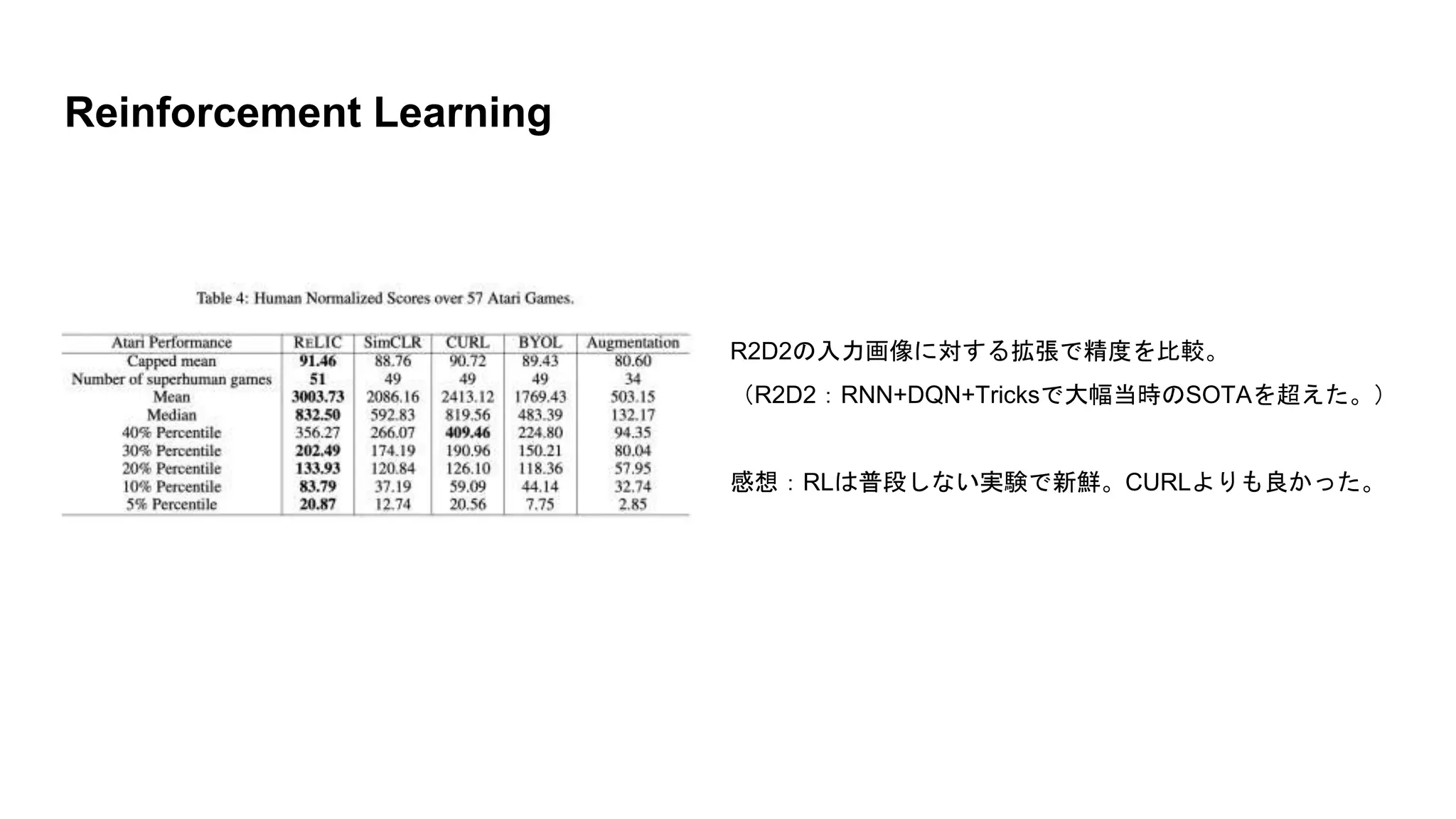
Reinforcement Learning R2D2の入力画像に対する拡張で精度を比較。 (R2D2:RNN+DQN+Tricksで大幅当時のSOTAを超えた。) 感想:RLは普段しない実験で新鮮。CURLよりも良かった。
19.
Conclusion
20.
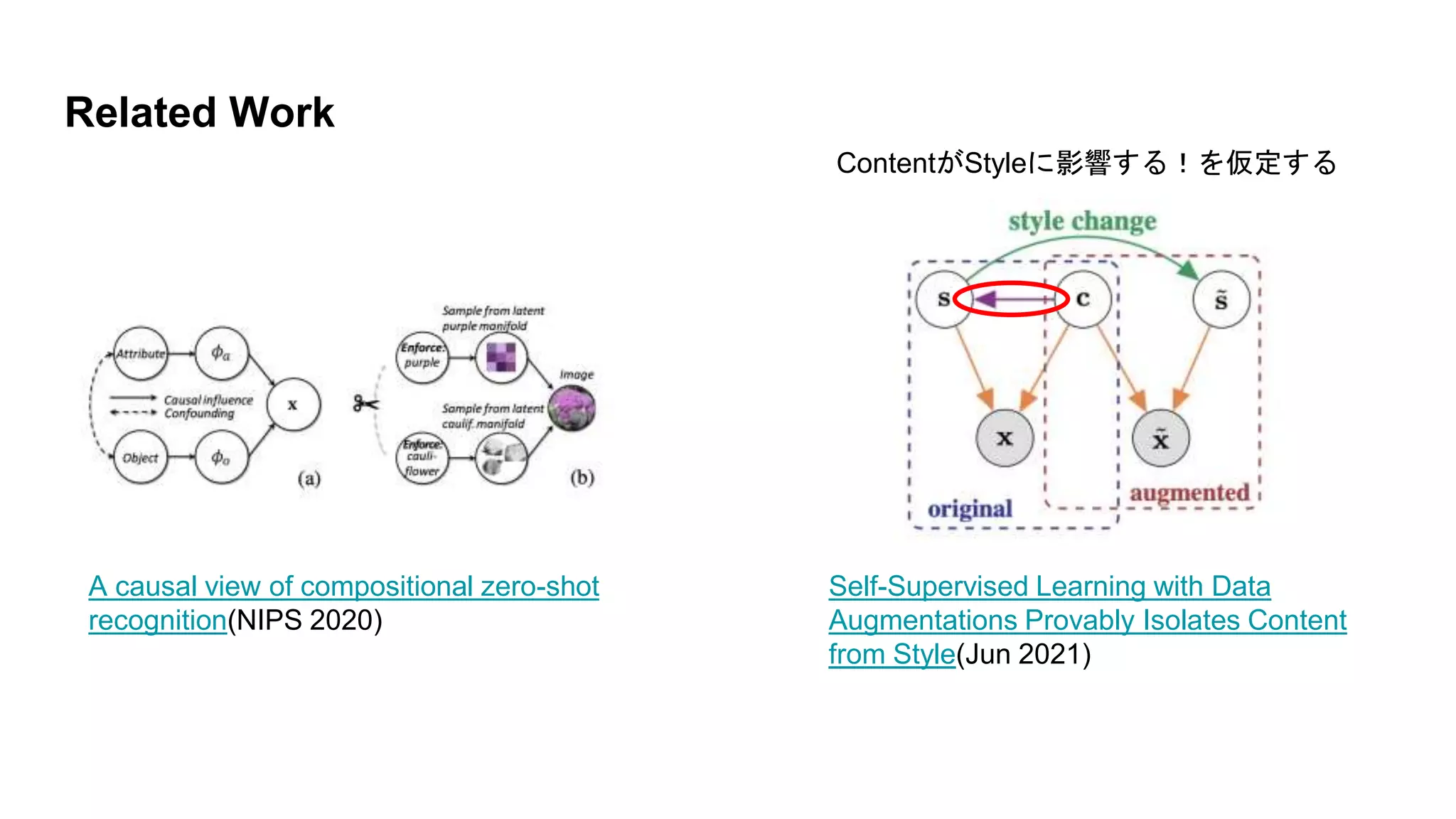
Related Work A causal
view of compositional zero-shot recognition(NIPS 2020) Self-Supervised Learning with Data Augmentations Provably Isolates Content from Style(Jun 2021) ContentがStyleに影響する!を仮定する
21.
まとめ: - Self-supervised learning(Contrastive
Learning)を因果の枠組みで解釈してみた研究。 - 特徴は、RELIC Lossが必要であることをを因果論?の数式で証明した(Appendixを参考)。 感想: - Contrastive Learningの新しい手法がどんどん提案されているに対して、その理論解析の研究が少な い(追いついていない)。 - 実装公開してほしい。
Download
![DEEP LEARNING JP
[DL Papers] Representation Learning via Invariant Causal Mechanisms
XIN ZHANG, Matsuo Lab
http://deeplearning.jp/](https://image.slidesharecdn.com/2021910representationlearningviainvariantcausalmechanisms-210910032836/75/DL-representation-learning-via-invariant-causal-mechanisms-1-2048.jpg)


![Reprensentation(Self-supervised) learningはMIだけでは解釈でき
ない
[DL輪読会]相互情報量最大化による表現学習、岩澤先生より](https://image.slidesharecdn.com/2021910representationlearningviainvariantcausalmechanisms-210910032836/75/DL-representation-learning-via-invariant-causal-mechanisms-6-2048.jpg)










![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Causality Inspired Representation Learning for Domain Generalization](https://cdn.slidesharecdn.com/ss_thumbnails/20220422lin-220422031920-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Fast and Slow Learning of Recurrent Independent Mechanisms](https://cdn.slidesharecdn.com/ss_thumbnails/20210604zhangxin-210604043141-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Adversarial Representation Active Learning](https://cdn.slidesharecdn.com/ss_thumbnails/adversarialrepresentationactivelearning131-200207031121-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] Learning Finite State Representations of Recurrent Policy Networks (I...](https://cdn.slidesharecdn.com/ss_thumbnails/20190830kaitosuzuki-190902060756-thumbnail.jpg?width=640&height=640&fit=bounds)
























