OpenAI APIを使ってみよう
Pythonで実装する ④APIリクエストを送って動作確認
•OpenAI公式HPに載っているサンプルコードを試してみる。
→ チャット補完(文法修正)を試してみる。
import os
import openai
# APIキーを設定
openai.organization = "[会社アカウントのOrganization ID]"
openai.api_key = os.getenv("OPENAI_API_KEY")
# 応答を取得するためのリクエストデータを定義
request_data = {
"model": "gpt-3.5-turbo",
"messages": [
{"role": "system", "content": "You will be provided with statements, and your task is to convert them to standard English."},
{"role": "user", "content": "She no went to the marcket"}
],
"temperature": 0,
"max_tokens": 256
}
# チャット補完APIにリクエストを送って応答を取得
response = openai.ChatCompletion.create(**request_data)
# メッセージの内容のみを表示
print(response['choices'][0]['message']['content'])
“ She no went to the marcket .”
↑
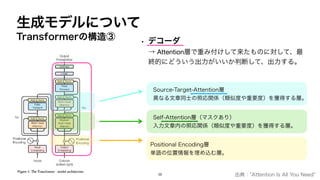
・リクエスト
「この文を標準的な英語の文に直してほしい」
← Openaiのチャット補完APIにリクエストを送って、
応答を取得
92



























































![機械学習モデルを作ってみよう
演習手順 ②データの整形(気温と日照時間を標準化)
今回は標準化を使用
Pythonライブラリsklearnの中に含まれている、標準化のメソッドを使用。
(正規化のメソッドもある)
from sklearn.preprocessing import StandardScaler
# 気温と日照時間のデータを標準化する
sc_temperature = StandardScaler()
sc_daylight = StandardScaler()
# トレーニングデータ
miyako_tr_sc_tem = sc_temperature.fit_transform(miyako_tr[:, :1])
miyako_tr_sc_dl = sc_daylight.fit_transform(miyako_tr[:, 1:2])
・標準化メソッド StandardScaler()
→ StandardScaler.
fi
t̲transform()関数で、標準化を実行
61](https://image.slidesharecdn.com/2023-230908011205-ea0b0c7f/85/AI-61-320.jpg)





























![OpenAI APIを使ってみよう
Pythonで実装する ④APIリクエストを送って動作確認
• OpenAI公式HPに載っているサンプルコードを試してみる。
→ チャット補完(文法修正)を試してみる。
import os
import openai
# APIキーを設定
openai.organization = "[会社アカウントのOrganization ID]"
openai.api_key = os.getenv("OPENAI_API_KEY")
# 応答を取得するためのリクエストデータを定義
request_data = {
"model": "gpt-3.5-turbo",
"messages": [
{"role": "system", "content": "You will be provided with statements, and your task is to convert them to standard English."},
{"role": "user", "content": "She no went to the marcket"}
],
"temperature": 0,
"max_tokens": 256
}
# チャット補完APIにリクエストを送って応答を取得
response = openai.ChatCompletion.create(**request_data)
# メッセージの内容のみを表示
print(response['choices'][0]['message']['content'])
“ She no went to the marcket .”
↑
・リクエスト
「この文を標準的な英語の文に直してほしい」
← Openaiのチャット補完APIにリクエストを送って、
応答を取得
92](https://image.slidesharecdn.com/2023-230908011205-ea0b0c7f/85/AI-92-320.jpg)
![OpenAI APIを使ってみよう
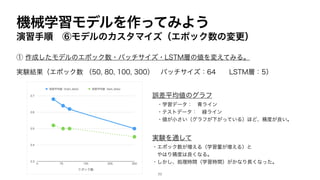
Pythonで実装する ④APIリクエストを送って動作確認(実行結果)
• チャット補完(文法修正)の実行結果
She did not go to the market.
・レスポンス
# メッセージの内容のみを表示
print(response['choices'][0]['message']['content'])
メッセージの内容のみを表示するように指示
93](https://image.slidesharecdn.com/2023-230908011205-ea0b0c7f/85/AI-93-320.jpg)









![[2024年4月] 業務で生成AIを活用したい人のための生成AI入門講座(社外公開版:キンドリルジャパン社内勉強会)](https://cdn.slidesharecdn.com/ss_thumbnails/genai101forgenaiusers-240501013644-db5ddbe3-thumbnail.jpg?width=640&height=640&fit=bounds)























































![Drupal11新機能紹介.pptx [2025/09/12]の勉強会で発表されたものです。](https://cdn.slidesharecdn.com/ss_thumbnails/drupal11-250912092900-c9767fcf-thumbnail.jpg?width=640&height=640&fit=bounds)














