1
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
l 0. 自己紹介
l 1. 導入:自然言語処理とは?
l 2. 技術の変遷 ルール => 統計処理 => 深層学習
l 3. 言語モデルに基づく言語処理
l 4. 巨大言語モデル(大規模化)
l 5. まとめ
3.
2
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
l 0. 自己紹介
l 1. 導入:自然言語処理とは?
l 2. 技術の変遷 ルール => 統計処理 => 深層学習
l 3. 言語モデルに基づく言語処理
l 4. 巨大言語モデル(大規模化)
l 5. まとめ
4.
3
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
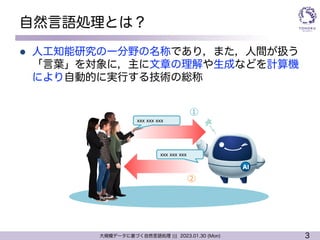
自然言語処理とは?
l 人工知能研究の一分野の名称であり,また,人間が扱う
「言葉」を対象に,主に文章の理解や生成などを計算機
により自動的に実行する技術の総称
①
②
xxx xxx xxx
xxx xxx xxx
5.
4
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
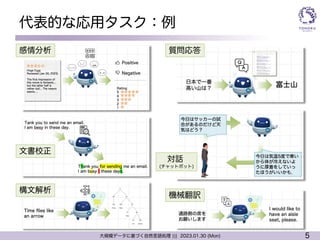
代表的な応用タスク
l 機械翻訳,文書要約,文章構成,対話,
l 質問応答,情報検索,
l 文書分類,感情分析,評判分析,スパムフィルタ
l 構文解析,意味解析,談話構造解析,
固有表現抽出,意図解析,照応解析,
含意認識,言い換え,
l ...その他沢山
l 他研究分野との境界領域のタスク
l 音声認識 (speech-to-text),音声合成 (text-to-speech)
l 画像キャプション生成 (image-to-text),
画像生成 (text-to-image)
9
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
まとめ
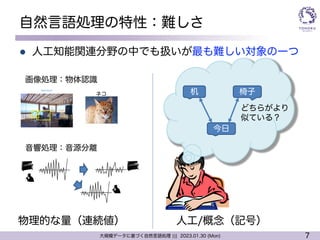
l 自然言語処理とは
l 人工知能研究の一分野の名称
l 文章の理解や生成などを計算機により自動的に実行する技術
l 代表的な応用タスク
l 機械翻訳,文書要約...全ては 入力=> システム => 出力
l 特性:難しさ
l 人工/概念,記号
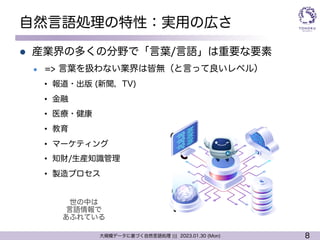
l 特性:実応用の広さ
l 産業界の多くの分野で「言葉」は重要な要素
=> 実社会において直に役立つ研究分野
11.
10
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
l 0. 自己紹介
l 1. 導入:自然言語処理とは?
l 2. 技術の変遷 ルール => 統計処理 => 深層学習
l 3. 言語モデルに基づく言語処理
l 4. 巨大言語モデル(大規模化)
l 5. まとめ
12.
11
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
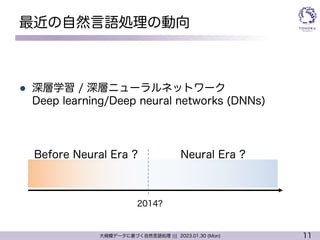
最近の自然言語処理の動向
l 深層学習 / 深層ニューラルネットワーク
Deep learning/Deep neural networks (DNNs)
Neural Era ?
Before Neural Era ?
2014?
13.
12
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
自然言語処理 x 深層学習 (DNN)
l 深層学習 (DNN) がAI関連技術の現在の主流
l 発端:音声認識 / 画像認識 2011〜
l 自然言語処理 2014〜
• 音声認識や画像認識などに比べると成功したのはだいぶ遅い
l Speech recognition
[Seide+, Interspeach11]
Improved 33%
l Image recognition
Won the first place [ILSVRC12]
Improved more than 10%
[参考資料] https://jsai-deeplearning.github.io/support/nnhistory.pdf
14.
13
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]
15.
14
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]
16
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
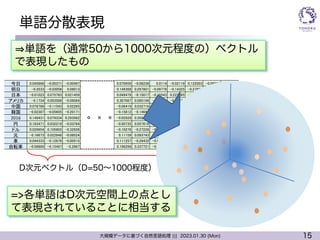
単語分散表現の効果
l 単語の関連性をベクトルとして「計算できる」
l 意味の合成 = ベクトル足し算
l 角度 = 二単語間の関連性
今日
明日
車
「今日」と「明日」は意味
的に近い
「今日」と「車」は意味的
に遠い
国名
都市名
年号
単語間の似た関連は似
た角度で配置される
man
men
woman
lion
lions
lioness
単数と複数
の関係
性別の関係
l 距離 = 単語間の意味的な類似性の
度合い
萌えバス
萌え
バス
+ =
18.
17
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
単語分散表現の重要さ
l 言語モデルなどを使う際にも必ず利用
l 言語モデルの入力層 = 単語分散表現そのもの
=> なくてはならない要素技術
l 記号からベクトル空間,ベクトル空間から記号への変換
l もしかしたら情報が欠損している可能性
19.
18
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]
20.
19
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
系列変換モデル
l 処理手順
l 入力文をDNNに入力
l その情報に基づいて出力文を先頭から一単語ずつ予測して出力
入力
[子犬] [隠れた] BOS
A
A
puppy hid
puppy
quickly
hid quickly
EOS
[は] [素早く]
BOS
出力
21.
20
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
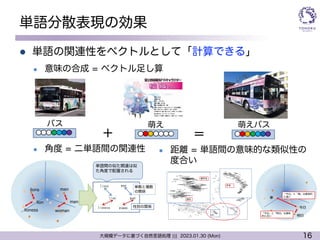
ニューラル機械翻訳
l 翻訳 => 確率モデルによる定式化
l 入力文X が与えられた時に出力文Y が得られる確率をモデルパラ
メタθを使ってモデル化
( I ʼd like to have an aisle seat please . )
<latexit sha1_base64="P3IhSBvvUBNospzIZILp/flLjD0=">AAACp3ichVFNSxtRFD2Oraa2amw3hW4G04gihBuhVLoK7aa7xo98lIyEmfGpj8wXMy+BOMwfcC246KqFLko3XRXabTf+ARf5CeJSoRsX3pkEShX1Dm/euefdc995XCtwZKSIBmPa+IOHE5O5R1OPn0zPzObnntYjvxvaomb7jh82LTMSjvRETUnliGYQCtO1HNGwOu/S80ZPhJH0vU3VD8SWa+56ckfapmKqnX9ZbceG5caG2hPKTJLFNPmY6IYrt/UUN5MlvZ0vUImy0G+C8ggUKvPG8uGg0q/6+Z8wsA0fNrpwIeBBMXZgIuKvhTIIAXNbiJkLGcnsXCDBFGu7XCW4wmS2w/9dzloj1uM87RllaptvcXiFrNRRpBP6Rud0TN/plC5v7RVnPVIvfd6toVYE7dmD5xt/71W5vCvs/VPd6VlhB6uZV8neg4xJX2EP9b39o/ONN+vFeIG+0Bn7/0wD+sMv8HoX9tc1sf7pDj8We0l4POXrw7gJ6iul8qsSrfGc3mIYObzAPBZ5Gq9RwXtUUePuB/iBX/itLWkftLrWHJZqYyPNM/wXmnkF8YKheg==</latexit>
P✓(Y | X)
<latexit sha1_base64="rMJ8zv+vkbYaiZjBIYbWhcjQ6x8=">AAACtnichVFNSxtRFD2OrbVaTdRNoZuQkGJRwp2WohQKoW7anRoTA8aGmfEZH5kvZl5C05A/4LpQiqsWuhD33bpwoz/ARX6CuEyhmy56ZyZQVNQ7vLnnnXfPfedxTd+WoSLqj2ijDx6OPRp/PDH5ZGo6lZ6ZrYReK7BE2fJsL6iaRihs6YqyksoWVT8QhmPaYtNsrkTnm20RhNJzN1THF9uO0XDlrrQMxVQ9/apmOt1q7+18lD/16vpiprbjqZBTQsjrxIcX9XSOChRH5ibQhyBXzNYWvvSLnVUv/Qs17MCDhRYcCLhQjG0YCPnbgg6Cz9w2uswFjGR8LtDDBGtbXCW4wmC2yf8G77aGrMv7qGcYqy2+xeYVsDKDPJ3TIQ3olI7ogv7e2qsb94i8dDibiVb49dT+09Kfe1UOZ4W9/6o7PSvsYjn2Ktm7HzPRK6xE3/78dVB6s57vPqcfdMn+v1OfTvgFbvu39XNNrB/c4cdkLz0ej359GDdB5WVBf12gNZ7TOyQxjmfIYp6nsYQi3mMVZe7+Dcc4xZm2rH3UhNZISrWRoWYOV0Lz/wEGH6bM</latexit>
X = (x1, . . . , xi, . . . , xI )
<latexit sha1_base64="5IH/sHLx4k6WNSnYSJRPJ9ef4b4=">AAACtnichVHJSiRBEH2W4761M5cBL40bCtJEKTIiDMh4EU9u7YKtTVV12pbWRlV2Q9v0D/gDIp4UPMjcvXrwoh/gwU8Qj24XD0ZVNYiKGkVWvHwZL/IloXuWGUii6xql9kddfUNjU3NLa1t7R6Lz52LgFnxDpA3Xcv1lXQuEZToiLU1piWXPF5qtW2JJ354Mz5eKwg9M11mQJU+s2VreMTdMQ5NMZRMjGd0ur1T+DoS5VMmqQ8lMzpUBp5jYek9MD2YTPZSiKJIfgVoFPRO9D6fnxZbHGTdxigxycGGgABsCDiRjCxoC/lahguAxt4Yycz4jMzoXqKCZtQWuElyhMbvN/zzvVqusw/uwZxCpDb7F4uWzMok+uqITuqML+k839Pxpr3LUI/RS4qzHWuFlO3Z/zz99q7I5S2y+qr70LLGBsciryd69iAlfYcT64s7e3fz4XF+5n47olv0f0jWd8wuc4r1xPCvmDr7wo7OXCo9HfT+Mj2BxOKWOpmiW5/QPcTSiC90Y4Gn8wQSmMIM0d9/HGS5wqYwp64pQ8nGpUlPV/MKbULwXd16oDA==</latexit>
Y = (y1, . . . , yj, . . . , yJ )
( 通路 側 の 席 を お願い し ます 。)
Neural Machine Translation (NMT)
22.
21
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
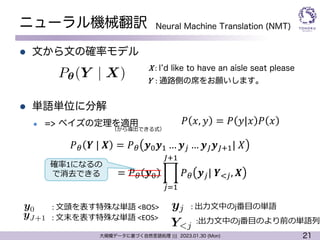
ニューラル機械翻訳
l 文から文の確率モデル
l 単語単位に分解
l => ベイズの定理を適用
Y : 通路側の席をお願いします。
X : Iʼd like to have an aisle seat please
<latexit sha1_base64="P3IhSBvvUBNospzIZILp/flLjD0=">AAACp3ichVFNSxtRFD2Oraa2amw3hW4G04gihBuhVLoK7aa7xo98lIyEmfGpj8wXMy+BOMwfcC246KqFLko3XRXabTf+ARf5CeJSoRsX3pkEShX1Dm/euefdc995XCtwZKSIBmPa+IOHE5O5R1OPn0zPzObnntYjvxvaomb7jh82LTMSjvRETUnliGYQCtO1HNGwOu/S80ZPhJH0vU3VD8SWa+56ckfapmKqnX9ZbceG5caG2hPKTJLFNPmY6IYrt/UUN5MlvZ0vUImy0G+C8ggUKvPG8uGg0q/6+Z8wsA0fNrpwIeBBMXZgIuKvhTIIAXNbiJkLGcnsXCDBFGu7XCW4wmS2w/9dzloj1uM87RllaptvcXiFrNRRpBP6Rud0TN/plC5v7RVnPVIvfd6toVYE7dmD5xt/71W5vCvs/VPd6VlhB6uZV8neg4xJX2EP9b39o/ONN+vFeIG+0Bn7/0wD+sMv8HoX9tc1sf7pDj8We0l4POXrw7gJ6iul8qsSrfGc3mIYObzAPBZ5Gq9RwXtUUePuB/iBX/itLWkftLrWHJZqYyPNM/wXmnkF8YKheg==</latexit>
P✓(Y | X)
Neural Machine Translation (NMT)
𝑃 𝑥, 𝑦 = 𝑃 𝑦|𝑥 𝑃 𝑥
𝑃% 𝒀 | 𝑿 = 𝑃% 𝒚&𝒚' … 𝒚( … 𝒚)𝒚)*'| 𝑋
<latexit sha1_base64="4MlYSDcAqfpzo4bYRcgwW2N95zc=">AAACiXichVG7TgJREB3WF4IKamNiQ0SMFZk1MRIqIo0lD3kkQMjuesGVfWV3IUHCD1jaWGCjiYWx5wdo/AELPsFY4qOxcFhIjBJxNrv33HPnzJ6bIxqKbNmIfRc3Mzs3v+Be9HiXlld8/tW1rKXXTYllJF3RzbwoWEyRNZaxZVthecNkgioqLCfW4sPzXIOZlqxrx3bTYCVVqGpyRZYEm6h8UVRbzXb5rOwPYhidCkwCfgyCse23bq/hfU/o/i4U4QR0kKAOKjDQwCasgAAWPQXgAcEgrgQt4kxCsnPOoA0e0tapi1GHQGyNvlXaFcasRvvhTMtRS/QXhV6TlAEI4RPe4wAf8QGf8fPPWS1nxtBLk1ZxpGVG2Xexkf74V6XSasPpt2qqZxsqEHG8yuTdcJjhLaSRvnF+NUhHU6HWDt7iC/m/wT726AZa41W6S7JUZ4ofkby0KR7+dxiTILsX5vfDmKScDmFUbtiELdilNA4gBkeQgIyTwiV04JrzcjwX4aKjVs411qzDj+LiX2Uml1Y=</latexit>
yj
<latexit sha1_base64="fw21zBFbMKoQ2BDwJOY8J79g/nU=">AAACjHichVHLSsNAFL2Nr/ps1Y3gpqgVV+VWFMUHiIK4tGptpZWSxGmNzYtkGqihP+BeXAiKggtx3x/oxh9w4SeIS18bF94kBVFRb5jMmTP33DkzVzJVxeaI9yGhpbWtvSPc2dXd09sXifYPbNtGxZJZWjZUw8pKos1URWdprnCVZU2LiZqksoxUXvH2Mw6zbMXQt3jVZLuaWNKVoiKLnKhcXtLcnVrBXTioFaKjmEA/Yj9BsglGl8Ze6g2n+3XdiNYhD3tggAwV0ICBDpywCiLY9OUgCQgmcbvgEmcRUvx9BjXoIm2FshhliMSW6V+iVa7J6rT2atq+WqZTVBoWKWMQxzu8xie8xRt8wPdfa7l+Dc9LlWYp0DKzEDka2nz7V6XRzGH/U/WnZw5FmPW9KuTd9BnvFnKgdw5PnjbnNuLuOF7iI/m/wHts0A1051m+SrGN0z/8SOTFa0/yezN+gu3JRHI6gSnq0zIEEYZhGIEJ6sYMLMEarEPaf89jOINzoU+YEuaFxSBVCDU1g/AlhNUPKNmYiA==</latexit>
Y<j
<latexit sha1_base64="BQlHOr3CdtLMtgzH9k1fZKhzVqk=">AAACjHichVG7SgNBFL1ZXzG+ojaCjUSUVOFGlIgiBAWxjInRQBLD7jrq4L7YnQTikh+wF4uAomAh9v6AjX6ARdAfEMsINhbe3QRERb3L7Jw5c8+dM3MVS+OOQGwEpI7Oru6eYG+or39gcCg8PLLpmGVbZVnV1Ew7p8gO07jBsoILjeUsm8m6orEt5WDF29+qMNvhprEhqhYr6vKewXe5Kgui8gVFd6u1bbdWwlJ4EmPox8RPEG+DyWQk+vSYuK+nzPANFGAHTFChDDowMEAQ1kAGh748xAHBIq4ILnE2Ie7vM6hBiLRlymKUIRN7QP89WuXbrEFrr6bjq1U6RaNhk3ICpvABr7CJd3iNz/j+ay3Xr+F5qdKstLTMKg0djWXe/lXpNAvY/1T96VnALsz7Xjl5t3zGu4Xa0lcOT5qZhfSUO40X+EL+z7GBt3QDo/KqXq6zdP0PPwp5qVF74t+b8RNszsTiczFcpz4tQyuCMA4RiFI3EpCENUhB1n/PYziFM2lQmpUWpaVWqhRoa0bhS0irH2U9mCM=</latexit>
y0
<latexit sha1_base64="z+rVvxyPo2BHm8YbKoO6uXtWxYE=">AAACknichVE7S8NQFD7GV62P1scguIhSKQjlRBDFqeoi4mCt1UJbSxJv68W8SNJCDfEH+AccnHx0EHf/gIt/wMHZSRwVXBw8SQqiRT0hud/97vlOvssnmyq3HcTHDqGzq7unN9IX7R8YHIrFh0d2bKNmKSynGKph5WXJZirXWc7hjsrypsUkTVbZrny46p/v1pllc0PfdhomK2lSVecVrkgOUeV4rChrbsPbc72yuz4reuX4NKYwqMl2ILbAdDqZfDo5ti83jfgtFGEfDFCgBhow0MEhrIIENj0FEAHBJK4ELnEWIR6cM/AgStoadTHqkIg9pG+VdoUWq9Pen2kHaoX+otJrkXISEviA1/iK93iDz/jx6yw3mOF7adAqh1pmlmMn49n3f1UarQ4cfKn+9OxABRYDr5y8mwHj30IJ9fWj09fs0lbCncELfCH/5/iId3QDvf6mNDNs6+wPPzJ58eMRf4bRDnbmUuJ8CjOU0wqEFYEJmIIkpbEAaViDTcgFiZ3BFTSFMWFJWBZWw1aho6UZhW8lbHwCECGZnw==</latexit>
yJ+1
: ⽂頭を表す特殊な単語 <BOS>
: ⽂末を表す特殊な単語 <EOS>
: 出⼒⽂中のj番⽬の単語
:出⼒⽂中のj番⽬のより前の単語列
= 𝑃% 𝒚& ,
(+'
)*'
𝑃% 𝒚(| 𝒀,(, 𝑿
確率1になるの
で消去できる
(から導出できる式)
23.
22
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
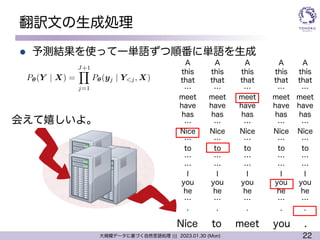
翻訳文の生成処理
l 予測結果を使って一単語ずつ順番に単語を生成
Nice
会えて嬉しいよ。
A
this
that
…
meet
have
has
…
Nice
…
to
…
…
I
you
he
…
.
to meet you .
A
this
that
…
meet
have
has
…
Nice
…
to
…
…
I
you
he
…
.
A
this
that
…
meet
have
has
…
Nice
…
to
…
…
I
you
he
…
.
A
this
that
…
meet
have
has
…
Nice
…
to
…
…
I
you
he
…
.
A
this
that
…
meet
have
has
…
Nice
…
to
…
…
I
you
he
…
.
<latexit sha1_base64="mEmrdHku5GSk+HbY+wFCnC1Api8=">AAAC73ichVFNSxxBEK0Zk/gRE1e9CF4GxWAwLDWBoIjCohfjaf1Yd8Uxw8xsq73OlzO9C+vQf8CrBw+BEAM5SO7+gVxyDngQ8geCR4XkkENqZpdIotEaevrV63rVryk7dHksEM8VtePBw0edXd09j3ufPO3L9Q+sxUE9cljJCdwgqthWzFzus5LgwmWVMGKWZ7usbO/Op+flBotiHvirohmyTc/a9vkWdyxBlJlzi2Zi2F5iiB0mLCnH02RdaobHq1qKK/K5ps1qRhgF1TfJ4oQuzaQ2q0vtNmFTmrVr6TqVztTkiz99zNwo5jEL7SbQ22C08PrwW6Gz3FsMcqdgQBUCcKAOHjDwQRB2wYKYvg3QASEkbhMS4iJCPDtnIKGHtHWqYlRhEbtL/23KNtqsT3naM87UDt3i0opIqcEYnuEJXuIX/ITf8dd/eyVZj9RLk3a7pWWh2XcwtPLjXpVHu4Cda9WdngVswVTmlZP3MGPSVzgtfWP/6HJlenkseYYf8IL8H+M5fqYX+I0r5+MSW357hx+bvEgaj/7vMG6CtZd5/VUel2hOc9CKLhiGERinaUxCARagCCXq/hV+KoqiqnvqkfpOfd8qVZW2ZhD+CvXkN/i8u+A=</latexit>
P✓(Y | X) =
J+1
Y
j=1
P✓(yj | Y<j, X)
24.
23
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]
25
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]
27.
26
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
低頻度語/語彙爆発 問題
l トークン単位として「単語」を利用する場合
l 全ての単語を語彙に含めると語彙数が爆発的に増加
• Zipfの法則,低頻度の単語が膨大に存在
l 対策:ある閾値以下の出現頻度の単語を語彙に
含めない
• 語彙に含まれない単語は未知語 (<unk>) とする
Vocab
0 <unk>
...
3 on
…
102 Had
…
1643 news
…
7321 little
…
14852 finance
…
44622 markets
…
128321 economic
…
Economic news had little effect on financial markets
<unk> news had little effect on <unk> markets
(Economic と financial が低頻度語だとする)
頻度順に
よる語彙
の閾値
未知語 <unk> が性能を大きく下げる要因
(低頻度語や語彙爆発はNLP分野でのNeural Era以前からある課題)
例
28.
27
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
解決策:Subword
l 低頻度語は部分単語の系列とみなす
l 利点
l 未知語を限りなくゼロに近づけることが可能
l 個々の部分単語は複数の単語の部分単語で共有されることで出
現頻度も相対的に高くなる
l (典型的な方法を用いると) 語彙サイズを自由に設計可能
• 現在は 32,000 や 64,000 などが用いられることが多い
Economic news had little effect on financial markets
Eco ̲nom ̲ic news had little effect on fin ̲an ̲cial mark ̲ets
部分単語
に分割
サブワードに分割する方法を採用する場合 Vocab
0 <unk>
...
3 on
…
102 Had
…
1643 news
…
7321 little
…
32000 ̲ets
29.
28
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
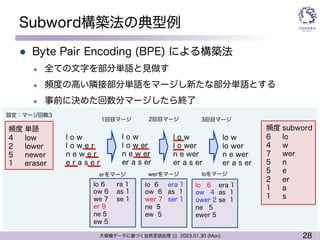
Subword構築法の典型例
l Byte Pair Encoding (BPE) による構築法
l 全ての文字を部分単語と見做す
l 頻度の高い隣接部分単語をマージし新たな部分単語とする
l 事前に決めた回数分マージしたら終了
erをマージ
lo 6
ow 6
we 7
er 9
ne 5
ew 5
ra 1
as 1
se 1
頻度
4
2
5
1
単語
low
lower
newer
eraser
l o w
l o w e r
n e w e r
e r a s e r
l o w
l o w er
n e w er
er a s er
lo w
lo wer
n e wer
er a s er
lo 6
ow 6
wer 7
ne 5
ew 5
era 1
as 1
ser 1
lo 6
ow 4
ower 2
ne 5
ewer 5
era 1
as 1
se 1
l o w
l o wer
n e wer
er a s er
werをマージ loをマージ
設定:マージ回数3
1回目マージ 2回目マージ 3回目マージ
頻度
6
4
7
5
5
2
1
1
subword
lo
w
wer
n
e
er
a
s
30.
29
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Subwordの重要さ
l (前述の通り) 長年のNLPの課題を克服
l やや地味? だが現在のNLP技術を支える要素技術
l 元々はニューラル翻訳の性能向上のための一つの手法として提
案 => 現在NLPの中心的な技術となっている言語モデルにおい
てほぼ必ず利用
l 言語モデルの最終的な性能を決める要因の一つ
• Subwordの作り方を変えるだけでも言語モデルの性能が大きく変化
31.
30
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]
32.
31
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Transformer
l 深層学習で現在最も注目されているモデル
l 2017年に登場
l 元々は主に機械翻訳のモデルとして提案
[引用] https://arxiv.org/abs/1706.03762
33.
32
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Transformer
l 深層学習で現在最も注目されているモデル
l 2018年:言語モデルBERTのベースモデルとして採用
=> 言語モデル (BERT) がNLPの
中心的技術になるに伴って広く
利用されるように
l BERT後に登場する言語モデルのほぼ
全てがTransformerをベースモデル
として採用
• e.g., GPT-3, T5, PaLM
https://arxiv.org/abs/1810.04805v2
34.
33
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
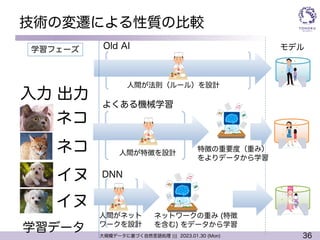
Transformer
l 深層学習で現在最も注目されているモデル
l 2020年: ViT => 画像処理でもTransformer
l 既に
l 音声処理でもTransformer
l 音楽でもTransformer
画像をメッシュに切って
それぞれの部分を自然
言語で言うところの単語
に見立てて入力
なんでも Transformer ??
35.
34
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
ニューラル以前の方法との比較
l 深層学習 / 深層ニューラルネットワーク
Deep learning/Deep neural networks (DNNs)
Neural Era ?
Before Neural Era ?
2014?
37
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
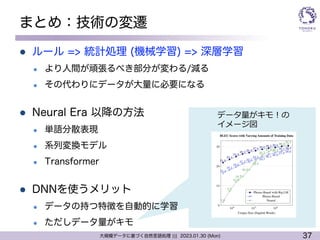
まとめ:技術の変遷
l ルール => 統計処理 (機械学習) => 深層学習
l より人間が頑張るべき部分が変わる/減る
l その代わりにデータが大量に必要になる
l Neural Era 以降の方法
l 単語分散表現
l 系列変換モデル
l Transformer
l DNNを使うメリット
l データの持つ特徴を自動的に学習
l ただしデータ量がキモ
データ量がキモ︕の
イメージ図
39.
38
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
l 0. 自己紹介
l 1. 導入:自然言語処理とは?
l 2. 技術の変遷 ルール => 統計処理 => 深層学習
l 3. 言語モデルに基づく言語処理
l 4. 巨大言語モデル(大規模化)
l 5. まとめ
40.
39
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]
43
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
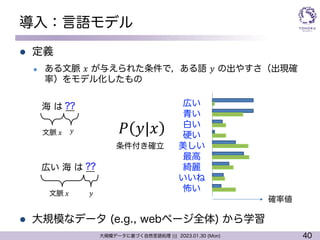
言語モデルをニューラルネットで近似
l Pros
l 𝑛-gramモデルよりも圧倒的に次の単語の予測性能が向上
l 未知の文脈に対しても(何かしら)予測可能
l Cons
l 計算コストが比較的高い
グーグル で 検索 し め 頻度0
(ニューラル言語モデル)
グーグル で 検索 し め った (に)
45.
44
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
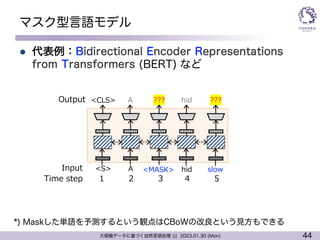
マスク型言語モデル
l 代表例:Bidirectional Encoder Representations
from Transformers (BERT) など
???
<MASK>
hid ???
<S>
<CLS>
A
A
hid slow
1 2 3 4 5
Output
Input
Time step
*) Maskした単語を予測するという観点はCBoWの改良という見方もできる
46.
45
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
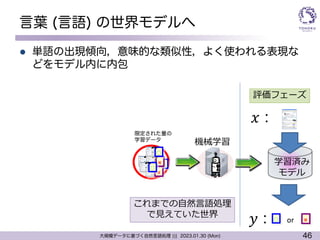
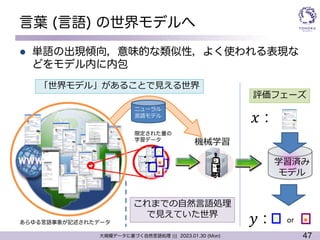
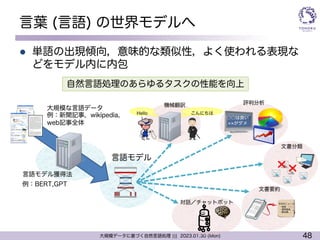
言葉 (言語) の世界モデルへ
l ニューラル言語モデルの学習データ => (ただの) 文章
l 文章データはweb上などに非常に多く存在
=> 深層学習をするには非常に適した状況
l 大量の学習データを使うことで予測性能が劇的に向上
l 文章の成り立ちを覚える
l DNNの特性
l 似ているものと似ていないものを判別可能
50
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
何が根本的に変わったか?
l 自然言語処理の正解データはコストが高いという課題
l 専門的な知識が必要 (な場合が多い)
l 事前学習済み言語モデル+少量のタスク特化の学習デー
タによる適応学習(fine-tuning)
l 自然言語処理の難しさの一つを克服
52.
51
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
[余談]
l 最近はleft-to-right型の言語モデルが主流
l Why : 生成できることがキモ
l 単一のモデルで複数のタスクに対応可能
単一の言語モデル
[入力文章] [定型フレーズ] [予測]
感情分析 この 映画は 良い [sentiment] positive
⽇本で⼀番⾼い⼭は [QA] 富⼠⼭
翻訳 I would like to have an
aisle seat, please.
質問応答
[En-ja] 通路側の席をお願
いします.
複数のタスク
53.
52
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
まとめ
l 言語モデル
l ある文脈 𝑥 が与えられた条件で,ある語 𝑦 の出やすさ(出現確
率)をモデル化したもの
l ニューラル言語モデル
l DNNで言語モデルの確率を近似したもの
l 言語の世界モデル
l 大量のデータで学習したニューラル言語モデル
• 単語の出現傾向,意味的な類似性などをモデル内に内包
l あらゆる言語処理タスクの基盤技術に
54.
53
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
l 0. 自己紹介
l 1. 導入:自然言語処理とは?
l 2. 技術の変遷 ルール => 統計処理 => 深層学習
l 3. 言語モデルに基づく言語処理
l 4. 巨大言語モデル(大規模化)
l 5. まとめ
55.
54
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]
56.
55
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
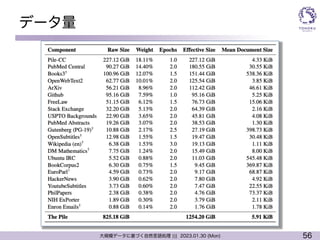
ニューラル言語モデルのスケール則
l 学習データ量が増えれば性能向上
l データ量と性能をプロットした際に対数スケールで線形の関係
(Scaling Laws)
Data size
(log-scale)
多
少
性能
低
高
101 102 103 104 105 106
データ量はとにかく多くすればよい
なぜか成り立つ
[Kaplan+, 2020] Scaling Laws for
Neural Language Models,
arXiv:2001.08361
[Hoffmann+, 2022] Training
Compute-Optimal Large Language
Models, arXiv:2203.15556
60
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
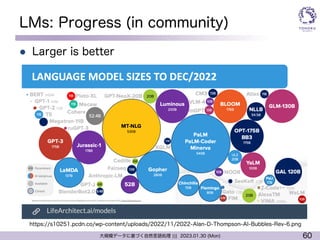
LMs: Progress (in community)
l Larger is better
https://s10251.pcdn.co/wp-content/uploads/2022/11/2022-Alan-D-Thompson-AI-Bubbles-Rev-6.png
63
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]
65.
64
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
方法論の変化
l 巨大言語モデル (Large Language Model: LLM)
l 実行するために膨大な計算リソースが必要
l 一般の企業/研究室での再学習は実行不可能
膨大な時間が必要
(e.g., 1~2ヶ月 with 1,024 x A100)
膨大な資金が必要
(e.g., $10-20M )
「適応学習 (fine-tuning)」=> 「プロンプト」という考え
66
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
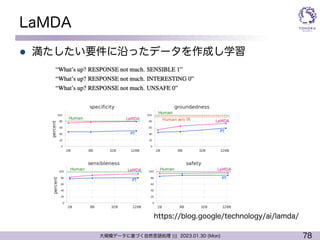
大規模言語モデルの能力を引き出す
l モデルパラメタを変更(学習)しなくても問題が解ける!?
l 前提:事前学習にて既に学習されている
è (基本的に) 学習されていないものは解けない
l コンテキストやラベル情報を使うことで出力を「制御」
68.
67
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Prompt engineering vs fine-tuning
l なぜ prompt という概念が出てきたのか?
l 巨大言語モデル
l 学習に大きな計算環境が必要
l 一般の計算機環境では実行不可能
l 学習(モデルパラメタの更新)せずに問題を解きたい
69.
68
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
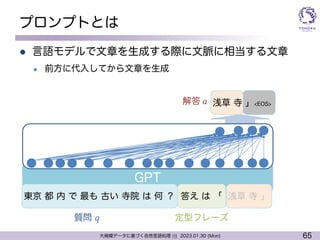
プロンプトでできること例
l ラベルで何を出すべきか制御
l 例題を与えると「解き方」を模倣?
l 文脈をつかってその気にさせる
日本で一番高い山は [QA] 富士山
質問応答:
次の質問に答えよ.
Q:世界で一番高い山は? A:エベレスト
Q:日本で一番長い川は? A:信濃川
Q:日本で一番高い山は? A:
A:はい,今日はいい天気だね.散歩に行きたね
B:いいですね!少し遠出してxx公園までどう?
A:それもいいけど,今の季節は桜を見に行きたいな.
B:
73
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
[参考] 対話もできる?
l 豊富な知識を背景にした高度な対話
l e.g., Wikipedia的な知識, 特定人物になりきる
Scaling Language Models: Methods, Analysis & Insights
from Training Gopher, DeepMind Blog 2021/12/8
75
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
注意点
l 巨大言語モデルも万能ではない...
l 従来と比較して計算リソースが大量に必要
l 結果は学習に使ったデータに大きく依存
l よく語られる実例は「良い例」だけを提示(している場合があ
る)
l 良い結果を得るための調整は職人芸
l どのような問題に,どのように利用するか
の見極めが重要 ( => 勘所を養う必要性)
77.
76
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]
79
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
ChatGPT
l 人間のフードバックによる強化学習 / Reinforcement
Learning from Human Feedback (RLHF)
https://openai.com/blog/chatgpt/
1. 人間が作った
チャットデー
タで普通に学
習
2. モデルを実行
してデータを
収集し人間が
ランキング
3. 人間がランキ
ングしたデー
タを使って強
化学習
81.
80
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
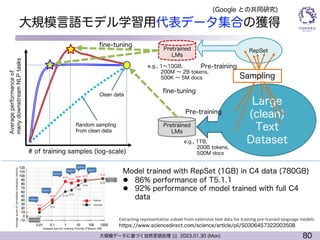
大規模言語モデル学習用代表データ集合の獲得
Large
(clean)
Text
Dataset
Pretrained
LMs
Pretrained
LMs
RepSet
Sampling
Average
performance
of
many
downstream
NLP
tasks
# of training samples (log-scale)
Random sampling
from clean data
Clean data
Pre-training
Pre-training
fine-tuning
fine-tuning
e.g., 1TB,
200B tokens,
500M docs
e.g., 1〜10GB,
200M 〜 2B tokens,
500K 〜 5M docs
RandSet
RepSet
Dataset size for training PreLMs (Filesize; GB)
w/o PreLM
Full C4
data
Average
score
of
normalized
evaluation
metrics
RepSet-5
RepSet-6
RepSet-4
RepSet-3
RepSet-2
RepSet-1
Model trained with RepSet (1GB) in C4 data (780GB)
l 86% performance of T5.1.1
l 92% performance of model trained with full C4
data
(Google との共同研究)
Extracting representative subset from extensive text data for training pre-trained language models
https://www.sciencedirect.com/science/article/pii/S0306457322003508
82.
81
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
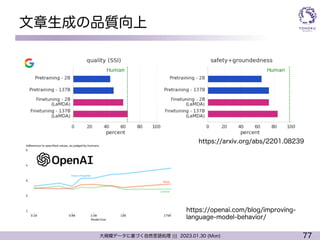
まとめ: 大規模言語モデル (LLM)
l 言語モデル
l 現在の文脈から次の単語を予測するモデル
l 言語の世界モデル
• 基本的に単語分散表現の上位互換のようなもの
l 現在の深層学習による言語モデルは人が書く文章を模倣できる
レベルに到達
=> ただし,万能というわけではない
l 量から質へ
l 最近の研究のフォーカスは品質に移りつつある?
83.
82
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
l 0. 自己紹介
l 1. 導入:自然言語処理とは?
l 2. 技術の変遷 ルール => 統計処理 => 深層学習
l 3. 言語モデルに基づく言語処理
l 4. 巨大言語モデル(大規模化)
l 5. まとめ
84.
83
大規模データに基づく自然言語処理 ||| 2023.01.30(Mon)
まとめ
l 自然言語処理
l AI関連の研究分野の一つ 「言葉」を対象にとした技術の総称
l DNNの発展により急速に発展している研究分野
l 現在の肝は大規模データと言語モデル => 量から質への転換?
l 実社会での適応例も豊富
l 応用と研究分野がとても近い
l ただし,まだできないことも多い
l 常識/実世界へのグラウンディング
l (まだまだ) AI研究のフロンティア:言葉を自在に操るAIはAI研
究の究極のゴールの一つ







![12
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
自然言語処理 x 深層学習 (DNN)
l 深層学習 (DNN) がAI関連技術の現在の主流
l 発端:音声認識 / 画像認識 2011〜
l 自然言語処理 2014〜
• 音声認識や画像認識などに比べると成功したのはだいぶ遅い
l Speech recognition
[Seide+, Interspeach11]
Improved 33%
l Image recognition
Won the first place [ILSVRC12]
Improved more than 10%
[参考資料] https://jsai-deeplearning.github.io/support/nnhistory.pdf](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-13-320.jpg)
![13
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-14-320.jpg)
![14
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-15-320.jpg)

![18
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-19-320.jpg)
![19
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
系列変換モデル
l 処理手順
l 入力文をDNNに入力
l その情報に基づいて出力文を先頭から一単語ずつ予測して出力
入力
[子犬] [隠れた] BOS
A
A
puppy hid
puppy
quickly
hid quickly
EOS
[は] [素早く]
BOS
出力](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-20-320.jpg)

![23
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-24-320.jpg)

![25
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-26-320.jpg)



![30
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-31-320.jpg)
![31
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
Transformer
l 深層学習で現在最も注目されているモデル
l 2017年に登場
l 元々は主に機械翻訳のモデルとして提案
[引用] https://arxiv.org/abs/1706.03762](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-32-320.jpg)




![39
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-40-320.jpg)



![49
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
[余談] 翻訳モデルと言語モデルの関係
l 翻訳の確率モデルは言語モデルに対する条件付き確率モ
デル
⾔語モデル:
翻訳モデル:
<latexit sha1_base64="vBx2H+BCUKXtn7gWNGtLQQoCzKw=">AAAC2nichVG/axRBFP6y0SQmMTljI9gshkgkcLwNiCIGDm3U6pJ4uUg2Lrt7k2Qu+4vduYNz2cZOLRUsrBQsxN4uVRr/gRQBOytRqwg2Fr7dPRATTd4yO9/75n1vvuE5kScTRbQ/oA2eOj00PHJmdGz87MRk5dzUShJ2Ylc03NAL41XHToQnA9FQUnliNYqF7TueaDrbt/PzZlfEiQyD+6oXiXXf3gzkhnRtxZRVadat1HT81FRbQtlZNpsnD7Ir+oJuRnHYepjemzMyK20vGJn+r9peZrV105ctvVRa6c02y63KNFWpCP0oMPpgunb3+afacHO8HlY+wEQLIVx04EMggGLswUbC3xoMECLm1pEyFzOSxblAhlHWdrhKcIXN7Db/Nzlb67MB53nPpFC7fIvHK2aljhnao3d0QB/pPX2hX//tlRY9ci893p1SKyJr8umF5Z8nqnzeFbb+qI71rLCB64VXyd6jgslf4Zb67qOXB8s3lmbSy/SGvrL/17RPu/yCoPvDfbsoll4d48dhLxmPxzg8jKNgZb5qXK3SIs/pFsoYwUVcwixP4xpquIM6Gtx9B5/xDd81U3usPdGelaXaQF9zHn+F9uI3/lK11A==</latexit>
P✓(Y ) =
J+1
Y
j=1
P✓(yj | Y<j)
<latexit sha1_base64="mEmrdHku5GSk+HbY+wFCnC1Api8=">AAAC73ichVFNSxxBEK0Zk/gRE1e9CF4GxWAwLDWBoIjCohfjaf1Yd8Uxw8xsq73OlzO9C+vQf8CrBw+BEAM5SO7+gVxyDngQ8geCR4XkkENqZpdIotEaevrV63rVryk7dHksEM8VtePBw0edXd09j3ufPO3L9Q+sxUE9cljJCdwgqthWzFzus5LgwmWVMGKWZ7usbO/Op+flBotiHvirohmyTc/a9vkWdyxBlJlzi2Zi2F5iiB0mLCnH02RdaobHq1qKK/K5ps1qRhgF1TfJ4oQuzaQ2q0vtNmFTmrVr6TqVztTkiz99zNwo5jEL7SbQ22C08PrwW6Gz3FsMcqdgQBUCcKAOHjDwQRB2wYKYvg3QASEkbhMS4iJCPDtnIKGHtHWqYlRhEbtL/23KNtqsT3naM87UDt3i0opIqcEYnuEJXuIX/ITf8dd/eyVZj9RLk3a7pWWh2XcwtPLjXpVHu4Cda9WdngVswVTmlZP3MGPSVzgtfWP/6HJlenkseYYf8IL8H+M5fqYX+I0r5+MSW357hx+bvEgaj/7vMG6CtZd5/VUel2hOc9CKLhiGERinaUxCARagCCXq/hV+KoqiqnvqkfpOfd8qVZW2ZhD+CvXkN/i8u+A=</latexit>
P✓(Y | X) =
J+1
Y
j=1
P✓(yj | Y<j, X)
このX部分が増
えただけの違い
=>
条件付き確率に
なった
=>
条件とは翻訳元
の⽂
翻訳は条件付き⾔語モデル](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-50-320.jpg)

![51
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
[余談]
l 最近はleft-to-right型の言語モデルが主流
l Why : 生成できることがキモ
l 単一のモデルで複数のタスクに対応可能
単一の言語モデル
[入力文章] [定型フレーズ] [予測]
感情分析 この 映画は 良い [sentiment] positive
⽇本で⼀番⾼い⼭は [QA] 富⼠⼭
翻訳 I would like to have an
aisle seat, please.
質問応答
[En-ja] 通路側の席をお願
いします.
複数のタスク](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-52-320.jpg)


![54
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-55-320.jpg)
![55
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
ニューラル言語モデルのスケール則
l 学習データ量が増えれば性能向上
l データ量と性能をプロットした際に対数スケールで線形の関係
(Scaling Laws)
Data size
(log-scale)
多
少
性能
低
高
101 102 103 104 105 106
データ量はとにかく多くすればよい
なぜか成り立つ
[Kaplan+, 2020] Scaling Laws for
Neural Language Models,
arXiv:2001.08361
[Hoffmann+, 2022] Training
Compute-Optimal Large Language
Models, arXiv:2203.15556](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-56-320.jpg)
![57
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
[余談]
l Similar tendency with scaling law 14 years ago
[ACL-2008]
Not neural models,
but linear modes](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-58-320.jpg)
![58
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
ニューラル言語モデルのスケール則
l モデルパラメタ数が増えれば性能向上
l モデルパラメタ数と性能をプロットした際に対数スケールで線
形の関係
[Kaplan+, 2020] Scaling Laws for
Neural Language Models,
arXiv:2001.08361
[Hoffmann+, 2022] Training
Compute-Optimal Large Language
Models, arXiv:2203.15556
(Scaling Laws)
Param. size
(log-scale)
多
少
性能
低
高
101 102 103 104 105 106
データ量もパラメタ数も,とにかく多くすればよい?
なぜか成り立つ](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-59-320.jpg)
![59
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
パラメタ数の推移
[引用] https://developer.nvidia.com/blog/
言語モデルのパラメタ数
は年々10倍に増加
PaLM (540B)
BLOOM (176B)
GLM (130B)
OPT (175B)
🌸
2022年の進捗](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-60-320.jpg)
![61
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
大規模言語モデルの到達点
l 人間が書く文章にせまる自動文章生成
オープンAIが開発した言語モデル「GPT-
3」を使って作成された偽ブログ記事が、
ハッカー・ニュースで1位を獲得した。記
事を投稿した大学生は単純な手法を使い、
「ほんの数時間」で記事を作成したという。
[引用]
https://www.technologyreview.jp/s/216514
/a-college-kids-fake-ai-generated-blog-
fooled-tens-of-thousands-this-is-how-he-
made-it/
人工知能を研究している非営利団体OpenAIが
開発した言語モデル「GPT-3」を使用して、
何者かが海外掲示板のRedditに1週間近く投
稿を続けていたことが分かりました。GPT-3
による投稿は、最終的に開発者の手によって
停止されましたが、発覚するまでの間GPT-3
は誰にも気付かれることなく、Redditユー
ザーと言葉を交わしていたと報じられていま
す。
[引用]
https://news.livedoor.com/article/detail/19025
490/
文章生成AI「GPT-3」がReddit
で1週間誰にも気付かれず人間と
会話していたことが判明
GPT-3:言語モデルの名前](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-62-320.jpg)
![62
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
[参考]
l GPT-JT:小さいモデルでも性能が高い場合もある](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-63-320.jpg)
![63
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-64-320.jpg)



![68
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
プロンプトでできること例
l ラベルで何を出すべきか制御
l 例題を与えると「解き方」を模倣?
l 文脈をつかってその気にさせる
日本で一番高い山は [QA] 富士山
質問応答:
次の質問に答えよ.
Q:世界で一番高い山は? A:エベレスト
Q:日本で一番長い川は? A:信濃川
Q:日本で一番高い山は? A:
A:はい,今日はいい天気だね.散歩に行きたね
B:いいですね!少し遠出してxx公園までどう?
A:それもいいけど,今の季節は桜を見に行きたいな.
B:](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-69-320.jpg)
![69
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
PaLM
[引用] https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-70-320.jpg)
![70
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
[参考] 冗談を理解?
[引用] https://nazology.net/archives/107210
[元記事] https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-71-320.jpg)
![71
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
[参考] 冗談を理解?
[引用] https://nazology.net/archives/107210
[元記事] https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-72-320.jpg)
![72
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
[参考] 計算ができる?
[引用] https://nazology.net/archives/107210](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-73-320.jpg)
![73
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
[参考] 対話もできる?
l 豊富な知識を背景にした高度な対話
l e.g., Wikipedia的な知識, 特定人物になりきる
Scaling Language Models: Methods, Analysis & Insights
from Training Gopher, DeepMind Blog 2021/12/8](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-74-320.jpg)
![74
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
言語モデルは「理解」しているのか?
[引用] https://nazology.net/archives/107210
実際に「jokeの理解」や「計算」が人間と同
じ意味でできているわけではない
基本的には学習に使った文章をニューラル
ネットの中で可能な限り「丸覚え」しており
うまく組み合わせて模倣している
表層的な意味で正しければ良い場面か
処理の過程も含めて理解が必要な場面か
それによって「できている」の解釈は変わる](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-75-320.jpg)

![76
大規模データに基づく自然言語処理 ||| 2023.01.30 (Mon)
Annual Technology Trends in NLP
l 2013 Neural word embeddings / 単語分散表現
l 2014 Neural encoder-decoder / 系列変換器
l 2015 Attention mechanism / 注意機構
l 2016 Subword / 部分単語
l 2017 Transformer / 自己注意型ネットワーク
l 2018 Neural language models / ニューラル言語モデル
l 2019 Masked neural LMs / マスク型言語モデル
l 2020 Large LMs: GPT-3 / 巨大言語モデル
l 2021 Prompt tuning/engineering / プロンプト開発
l 2022 (Generation quality enhancement / 言語生成品質の向上)
l 2023 (???)
[my personal choice]](https://image.slidesharecdn.com/20230130udacresearchtalkjspublic-230207214833-2bd5b696/85/slide-77-320.jpg)











![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)

![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)

