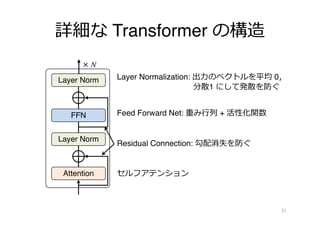
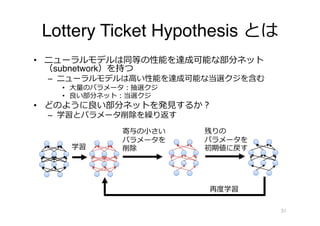
すべてのタスクを⾏うモデルも
• ⼤規模コーパスで⾔語モデルを学習
• 応⽤タスクでの学習なしに適⽤可能に
–問題の説明 + 問題を⼊⼒
5
ウンベルト・エー
コの新作,『バウ
ドリーノ』は農⺠
の⼦が……
Baudolino, a new
novel by Umberto
Eco, is the story of
a peasant boy ……
⼤量の⽂書で
⾔語モデルを学習
English to Japanese:
Where is my cat?
私の猫はどこですか︖
Summarization:
ウンベルト・エーコの新作,『バウドリーノ』は農⺠
の⼦バウドリーノがバルバロッサとも呼ばれる……
エーコの新作,
史実と想像⼒のまじわる冒険物語
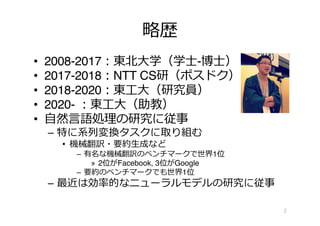
Recurrent Neural Network(RNN)
• 埋め込み(またはベクトル)と⾃⾝の出⼒を⼊⼒
– 原型は1980年代に提案される
• 様々な発展型が存在
21
RNN
Where is my cat
RNN RNN RNN
出⼒を次のタイムステップ
の⼊⼒としても使⽤
時刻 t の埋め込みを et 出⼒を ht
活性化関数を f とし
重み⾏列を W, U とすると
ht = f (W et + U ht-1)
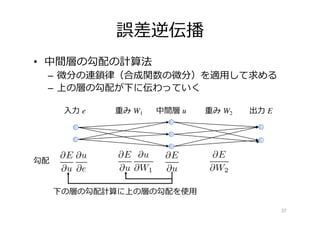
22.
語順が変わると違う結果に
• ⼊⼒が whereis の場合
– where を⼊⼒︓h0 = f (W ewhere)
– is を⼊⼒︓ h1 = f (W eis + U h0)
= f (W eis + U f (W ewhere))
• ⼊⼒が is where の場合
– is を⼊⼒︓h0 = f (W eis)
– where を⼊⼒︓h1 = f (W ewhere + U h0)
= f (W ewhere + U f (W eis))
22
23.
RNNの問題点
• 情報を⻑期間保持できない
– 式︓ht= f (W et + U ht-1)
– 活性化関数 f は多くの場合 tanh
• tanh︓値域は -1 から 1
• 値域が⼤きい活性化関数を使うと発散する危険がある
• 過去の⼊⼒に何度も tanh が適⽤される
– ht = f (W et + U ht-1)
= f (W et + U f (W et-1 + U ht-2))
= f (W et + U f (W et-1 + U f (W et-2 + U ht-3))) = …
– tanh を繰り返す → 値が減少 → 過去の情報が消失
23
24.
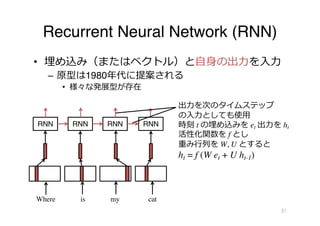
改善モデル︓LSTM
• RNNの問題点︓過去の情報が消失
– tanhを繰り返すことで値が減衰していく
• 解決法︓値を保持する部分を⽤意する
– メモリセル︓ct ,ゲート︓
24
Ct
LSTM
活性化関数として
シグモイド(σ)を使⽤
閾値が 0 から 1 のベクトル
it
ft
ot
ft = σ (Wf et + Uf ht-1)
it = σ (Wi et + Ui ht-1)
ot = σ (Wo et + Uo ht-1)
It = tanh(WI et + UI ht-1)
ct = ft × ct-1 + it × It
ht = ot × tanh(ct)
25.
LSTMの挙動
• ゲートの全要素が常に 1の場合
– メモリセルに過去の全ての情報 It が⾜される
– ct = ft × ct-1 + it × It = ct-1 + It
= ct-2 + It-1 + It = ct-3 + It-2 + It-1 + It = …
→ 過去の全ての情報が保持される
= 単純なRNNよりも⻑期間情報を保持可能
• 実際には各ゲートの値で情報を調整する
– ⼊⼒ゲート it ︓⼊⼒する情報の量を調整
– 忘却ゲート ft ︓メモリセルから情報を消す調整
– 出⼒ゲート ot ︓出⼒する情報の量を調整
25
26.
それでも⻑過ぎる系列は難しい
• 英-⽇翻訳で考えると
– Istarted reading Baudolino, written by Umberto Eco,
because I found it at the library yesterday. を訳す
• 最初の情報を最後まで格納しなければならない
– 理論的には可能だが難しい
• 例えば f の値が常に 0.9 だとしても 20 ステップ後には 0.1
• 20 ステップ前の⼊⼒の情報は失われる
– 実際にはもう少し複雑
26
LSTM
I started reading 昨⽇ 読み 始めた
… …
LSTM LSTM LSTM
… LSTM LSTM
…
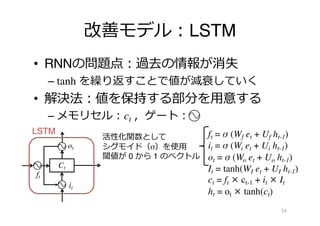
RNN・LSTM の問題
• 系列を計算し終えるまでが遅い
–時間に依存するので並列計算ができない
– RNN: ht = f (W et + U ht-1)
– LSTM: It = tanh(WI et + UI ht-1)
29
LSTM
I started
LSTM
started の時点の⼊⼒は I を⼊⼒した計算結果
パラメータの学習
• パラメータ(重み⾏列)はランダムに初期化
– 初期は出⼒もランダム
–良い出⼒のニューラルネットをどう得るか︖
• 学習︓訓練データを再現するパラメータを求める
– 正確には訓練事例との誤差を最⼩化する
– 翻訳の場合︓対訳の⽂対が訓練データ
• 数⼗万以上の⽂対が必要
34
英-⽇翻訳の訓練データ
I have a dog
I have read the book
…
⽝を飼ってます
その本は読み終わった
…
35.
データ数が多いほど性能も良い
• 訓練データが⼤きいほど性能向上
– 翻訳の訓練に使⽤する対訳⽂数を変えると……
35
Because30 years
ago, I'm from New
Jersey, and I was six,
and I lived there in my
parents' house in a
town called Livingston,
and this was my
childhood bedroom.
30年前 私は
ジャージー出⾝で
6歳でした 両親の
家にはLiventとい
う町に住んでいま
した これは ⼦ど
もの寝室でした
30 年前 私は
ニュージャージー
出⾝で6歳でした
両親の住むリビン
グトンという町に
住んでいました こ
れは⼦供の頃の寝
室です
およそ30年前
スズズズズズズ
ズズで 私の頃
です
翻訳元の英⽂
1万 10万 20万
36.
(確率的)勾配降下法
• 学習の⽬的︓訓練事例との誤差を最⼩化
• まずは⽬的関数(誤差)Eを定義
– 翻訳の場合︓正解の単語を出⼒する確率を最⼤化
• 確率 p の最⼤化=負の対数尤度 - log p の最⼩化
• E を最⼩に近づけていく
– 値が⼩さくなる点(極⼩点)を探す
– モデルの勾配を計算 → 下げる⽅向にパラメータ w を動かす
36
確率的勾配降下法の⼿続き
1. 訓練事例から少数の事例をサンプル
2. E を計算
3. 勾配計算
4. パラメータの更新
5. 1. に戻る
勾配 を計算
減少させる側に動かす
⾏きたい点
事前学習モデルとは
• 事前学習モデル︓ELMo, BERT,GPT, …
– ⼤量の⽂書でモデルを学習
– 対象タスクでパラメータを調整(ファインチューニング)
• 対象タスクが翻訳の場合
39
ウンベルト・エー
コの新作,『バウ
ドリーノ』は農⺠
の⼦が……
Baudolino, a new
novel by Umberto
Eco, is the story of
a peasant boy ……
対訳⽂でパラメータを調整
Where is my cat?
私の猫はどこですか︖
ウンベルト・エー
コの新作,『バウ
ドリーノ』は農⺠
の⼦が……
Baudolino, a new
novel by Umberto
Eco, is the story of
a peasant boy ……
⼤量の⽂書で
⾔語モデルを学習
40.
事前学習モデルとは
• 事前学習モデル︓ELMo, BERT,GPT, …
– ⼤量の⽂書でモデルを学習
– 対象タスクでパラメータを調整(ファインチューニング)
• 対象タスクが翻訳の場合
40
ウンベルト・エー
コの新作,『バウ
ドリーノ』は農⺠
の⼦が……
Baudolino, a new
novel by Umberto
Eco, is the story of
a peasant boy ……
対訳⽂でパラメータを調整
Where is my cat?
私の猫はどこですか︖
ウンベルト・エー
コの新作,『バウ
ドリーノ』は農⺠
の⼦が……
Baudolino, a new
novel by Umberto
Eco, is the story of
a peasant boy ……
⼤量の⽂書で
⾔語モデルを学習 なぜ⾔語モデルを
学習すると良い︖
41.
おさらい︓データ数が多いほど性能も良い
• 訓練データが⼤きいほど性能向上
– 翻訳の訓練に使⽤する対訳⽂数を変えると……
41
Because30 years
ago, I'm from New
Jersey, and I was six,
and I lived there in my
parents' house in a
town called Livingston,
and this was my
childhood bedroom.
30年前 私は
ジャージー出⾝で
6歳でした 両親の
家にはLiventとい
う町に住んでいま
した これは ⼦ど
もの寝室でした
30 年前 私は
ニュージャージー
出⾝で6歳でした
両親の住むリビン
グトンという町に
住んでいました こ
れは⼦供の頃の寝
室です
およそ30年前
スズズズズズズ
ズズで 私の頃
です
翻訳元の英⽂
1万 10万 20万
⾔語モデルの訓練データは構築が容易
• ⾔語モデル︓⾃然⾔語としての確からしさを計算
– 同時確率を条件付き確率の積で計算
•⾔語モデルの学習︓各⽂脈(単語列)の次に出現する単語を予測
• 任意の(⾃然⾔語の)⽂書=⾔語モデルの訓練データ
– Wikipediaの⽂書がそのまま(追加でタグ付けなどなしに)使える︕
43
Encoder-Decoder
RNN Encoder-Decoder
P(I have a dream) > P(a have I dream) > P(fuga spam hoge)
:
• RNN
•
P(I have a dream)
= P(I)P(have | I)P(a | I have)P(dream | I have a)
I have a dream
何らかのニューラルネット
I have a
I have a dream
<BOS>
I have a
dream that
one day …
44.
44
何らかのニューラルネット
I have a
Ihave a dream
<BOS>
何らかのニューラルネット
MASK MASK a
I have
<BOS>
マスクド⾔語モデル(BERT系)
⼊⼒の⼀部をマスクし,その単語を予測
⼊⼒系列 X について次を最⼤化
マスクする単語を
ランダムに選択
マスクされた
単語を予測
⾔語モデル(GPT系)
与えられた⽂脈に対し次の単語を予測
⼊⼒系列 X について次を最⼤化
k-1から1つ前までの
単語を⽂脈とする
⽂脈の次の
単語を予測
• 学習⽅法で 2種に⼤別
– 構造は主に Transformer
有名な事前学習モデル
蒸留(Distillation)
• 学習済みモデルの出⼒を⼩規模モデルで再現
– ⾔語モデルの学習を例に
•系列変換タスク⽤の⼿法は次スライドで
48
Baudolino, a new
novel by Umberto
Eco, is the story of
a peasant boy ……
元となるモデル
(教師モデル)
の学習
⼩さなモデル
(⽣徒モデル)
の学習
Baudolino, a new
novel by Umberto
Eco, is the story of
a peasant boy ……
Baudolino, a new
Baudolino, a new
novel
⽂脈を⼊⼒し,
次の単語を予測
Baudolino, a new
novel 教師モデルの
出⼒を再現する
ように学習
通常の学習
(次の単語
を予測)
49.
系列変換タスクでの蒸留
• 教師モデルの⽣成した系列で⽣徒モデルを学習
– 経験的に性能が良く,実装も楽
49
1.通常の訓練データで
教師モデルを学習
ウンベルト・エー
コの新作,『バウ
ドリーノ』は農⺠
の⼦が……
Baudolino, a new
novel by Umberto
Eco, is the story of
a peasant boy ……
『バウドリーノ』
(ウンベルト・
エーコの新作)は
農⺠の⼦が…
Baudolino, a new
novel by Umberto
Eco, is the story of
a peasant boy ……
2. 教師モデルで
訓練データを再⽣成
Baudolino, a new
novel by Umberto
Eco, is the story of
a peasant boy ……
『バウドリーノ』
(ウンベルト・
エーコの新作)は
農⺠の⼦が…
3. 教師モデルの
⽣成した訓練データで
⽣徒モデルを学習








![内積を⽤いて表現してみる
• 先の 1層ニューラルネットは内積で書ける
9
⼊⼒︓
⽂中の名詞
重み︓
判定への寄与度
⾮線形変換︓
シグモイドで確率化
⽝
草原
⽯
1 / (1 + e-x)
2.8
0.0
-3.1
[2.8 0.0 -3.1]
x1
x2
x3
x1
x2
x3
[
]
= 2.8 × x1 + 0.0 × x2 -3.1 × x3
重み・⼊⼒を w,x ベクトルとすると w・x(内積)
シグモイド関数を
適⽤する直前までを
数式で表すと](https://image.slidesharecdn.com/lectureingunmalab202112174up-211220093012/85/slide-9-320.jpg)
![複数出⼒・多層への拡張
• 複数次元のベクトルを出⼒する
– 重みベクトルを重み⾏列にする
• 3次元ベクトル → 2次元ベクトル︓2 × 3次元の重み⾏列
• 多層にする
– 複数の重み⾏列を⽤意する
– ⾏列積 → 活性化関数(⾮線形変換)→ ⾏列積 → …
• 複雑なネットワークでも基本は同じ
10
w11 w12 w13
w21 w22 w23
x1
x2
x3
[
]
w11 × x1 + w12 × x2 + w13 × x3
w21 × x1 + w22 × x2 + w23 × x3
=
2 × 3 の⾏列
[ ]](https://image.slidesharecdn.com/lectureingunmalab202112174up-211220093012/85/slide-10-320.jpg)

![⾃然⾔語処理に適⽤したい
• 問題点︓⽂をどう⼊⼒するか︖
– ニューラルネットワークの⼊⼒はベクトル
– ⾃然⾔語の⽂はベクトルではない
• どのようにベクトル化するか︖
• 単純な解決法︓Bag-of-Wordsベクトルで表現
– 単語の出現頻度を要素としたベクトル
• Where is my cat →
12
[0 0 1 … 1 … 1 … 1 … 0 0 0]
a the is my cat
where](https://image.slidesharecdn.com/lectureingunmalab202112174up-211220093012/85/slide-12-320.jpg)












![情報伝達の経路を短くする
• アテンションを使う
– 翻訳では対応する語の間に経路をつくる
• 実際には各ノードの重み(対応する確率)を計算して接続
27
LSTM
I started reading 昨⽇ 読み 始めた
… …
LSTM LSTM LSTM
… LSTM LSTM
…
アテンション
o1
o2
…
[
]
[ ot ]
a1
a2
…
[
]
ot へのアテンション︓
出⼒ ot 間の
内積から確率を計算
アテンションを使った接続
対応する確率の重み付き和
各出⼒間の
内積計算
計算結果の
確率化
softmax 関数
を使⽤](https://image.slidesharecdn.com/lectureingunmalab202112174up-211220093012/85/slide-27-320.jpg)
























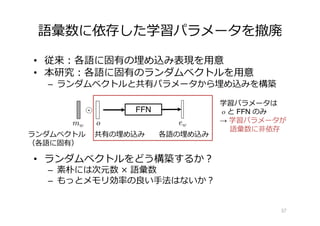
![従来の軽量化︓⾏列分解的な⼿法
• 埋め込み⾏列を複数の⾏列に分解
– ⼩さな次元数 × 語彙数の⾏列を⾏列演算で拡張
• 2 つに分解する [Lan+ 20]
• より複雑な分解 [Mehta+ 20]
• 問題点︓語彙数に依存した⾏列は必要
– 語彙数は数万〜数⼗万=巨⼤な⾏列が存在
• 語彙数に依存した学習パラメータを撤廃できないか︖
56
次元数×語彙数 ×
=
次元数×語彙数
×
=
× 結合](https://image.slidesharecdn.com/lectureingunmalab202112174up-211220093012/85/slide-56-320.jpg)














![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)













![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)
![Graph-to-Sequence Learning using Gated Graph Neural Networks. [ACL'18] 論文紹介](https://cdn.slidesharecdn.com/ss_thumbnails/graph2sequencelearningusinggatedgraphneuralnetworkacl18-190507010338-thumbnail.jpg?width=640&height=640&fit=bounds)















