18
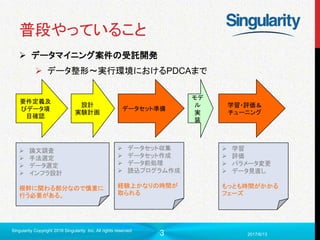
PLSAの特徴
各文章のベクトルは最終的に(p(z1, d),p(z2, d), p(z3, d) …p(zk, d))
で表される。
ベクトルの意味もわかりやすく、LSAよりも精度が高い
p(w|z)を高い順にソートすればトピックごとの特徴単語もわかる。
LSAと同じように、文章ベクトル化以外にレコメンドなどにも使える
しかし、トピックの生起が文章依存のため、新規文章を扱うことができな
い
2017/6/13
Singularity Copyright 2016 Singularity Inc. All rights reserved
この文章がトピック1である確率
19.
19
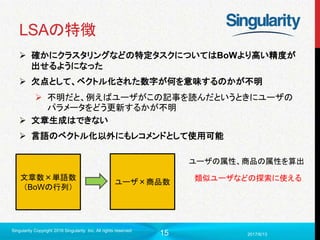
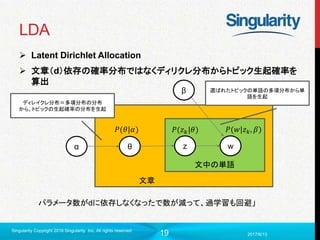
LDA
Latent DirichletAllocation
文章(d)依存の確率分布ではなくディリクレ分布からトピック生起確率を
算出
2017/6/13
Singularity Copyright 2016 Singularity Inc. All rights reserved
文中の単語
文章
z w
β
θα
パラメータ数がdに依存しなくなったで数が減って、過学習も回避」
𝑃(𝑤|𝑧 𝑘, 𝛽)𝑃(𝑧 𝑘|𝜃)𝑃(𝜃|𝛼)
ディレイクレ分布=多項分布の分布
から、トピックの生起確率の分布を生起
選ばれたトピックの単語の多項分布から単
語を生起
20.
20
LDAの特徴
推定した分布を事前分布として用いれば新規文章も扱える
PLSAはLDAの特殊な時の形
もちろん直接解けないので、本論文は変分ベイズで解いている
もっと簡単にMCMCを用いてサンプリングするのが一般的
どの手法にも言えることなのだが、確率を扱うために短文には弱い
最近では画像のトピック推定などにも用いられている
LDAと深層学習を組み合わせたり、単語の並びを考慮した亜種がかな
り存在する
2017/6/13
Singularity Copyright 2016 Singularity Inc. All rights reserved
21.
21
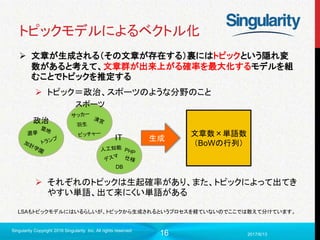
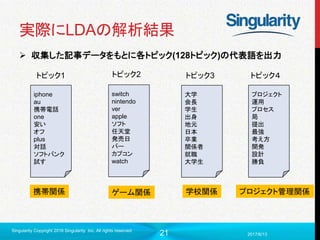
実際にLDAの解析結果
収集した記事データをもとに各トピック(128トピック)の代表語を出力
2017/6/13
Singularity Copyright2016 Singularity Inc. All rights reserved
iphone
au
携帯電話
one
安い
オフ
plus
対話
ソフトバンク
試す
トピック1
switch
nintendo
ver
apple
ソフト
任天堂
発売日
バー
カプコン
watch
携帯関係 ゲーム関係
トピック2
大学
会長
学生
出身
地元
日本
卒業
関係者
就職
大学生
トピック3
学校関係
プロジェクト
運用
プロセス
局
提出
最強
考え方
開発
設計
勝負
トピック4
プロジェクト管理関係
22.
22
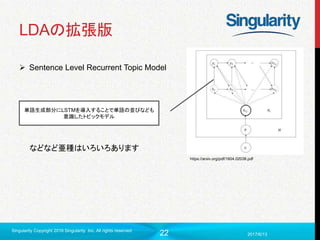
LDAの拡張版
2017/6/13
Singularity Copyright 2016Singularity Inc. All rights reserved
https://arxiv.org/pdf/1604.02038.pdf
Sentence Level Recurrent Topic Model
単語生成部分にLSTMを導入することで単語の並びなども
意識したトピックモデル
などなど亜種はいろいろあります
23.
23
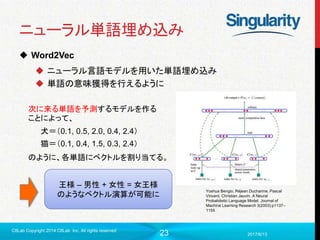
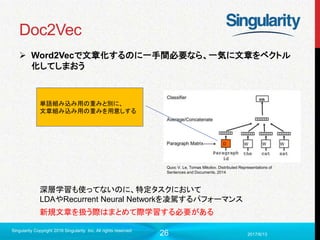
ニューラル単語埋め込み
Word2Vec
ニューラル言語モデルを用いた単語埋め込み
単語の意味獲得を行えるように
2017/6/13
C8Lab Copyright 2014 C8Lab Inc. All rights reserved
Yoshua Bengio, Réjean Ducharme, Pascal
Vincent, Christian Jauvin. A Neural
Probabilistic Language Model. Journal of
Machine Learning Research 3(2003):p1137–
1155
犬=(0.1, 0.5, 2.0, 0.4, 2.4)
猫=(0.1, 0.4, 1.5, 0.3, 2.4)
次に来る単語を予測するモデルを作る
ことによって、
のように、各単語にベクトルを割り当てる。
王様 – 男性 + 女性 = 女王様
のようなベクトル演算が可能に
24.
24
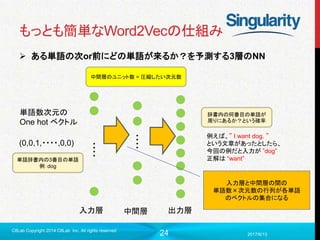
もっとも簡単なWord2Vecの仕組み
ある単語の次or前にどの単語が来るか?を予測する3層のNN
2017/6/13
C8Lab Copyright2014 C8Lab Inc. All rights reserved
・
・
・
・
・
・
・
・
入力層 出力層中間層
単語数次元の
One hot ベクトル
(0,0,1,・・・・,0,0)
単語辞書内の3番目の単語
例:dog
中間層のユニット数 = 圧縮したい次元数
辞書内の何番目の単語が
周りにあるか?という確率
例えば、” I want dog. ”
という文章があったとしたら、
今回の例だと入力が ”dog”
正解は “want”
入力層と中間層の間の
単語数×次元数の行列が各単語
のベクトルの集合になる
29
オレのヨメの特徴
現在βテスト中
ニュース記事に限らず2chやQiitaやarxivなど様々なフィードを推薦し
ます
現時点取得元サイト数:727サイト
一週間あたり取得記事数:約50000件
推薦ロジックはキーワード&LDAベースでリアルタイムに新規記事を
ユーザに推薦
webバックエンドはGAE + Data Store / GO
分析、レコメンド基盤はGCE + Google Big Query
現在Web版のみ
2017/6/13
Singularity Copyright 2016 Singularity Inc. All rights reserved
30.
30
正式リリース版に向けて
レコメンドの精度確認及びチューニング
スマホアプリ開発
記事データ及びユーザアクションの収集
タスク志向型会話AIによる記事推薦が目標
将来的には今話題になってることに対する雑談機能も追加予定
2017/6/13
Singularity Copyright 2016 Singularity Inc. All rights reserved
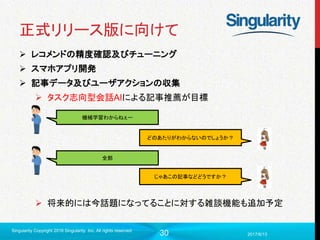
機械学習わからねぇー
どのあたりがわからないのでしょうか?
全部
じゃあこの記事などどうですか?
31.
31 2017/6/13
C8Lab Copyright2014 C8Lab Inc. All rights reserved
ご静聴ありがとうございました!
できれば使って見ていただけると嬉しいです!
https://orenoyome.jp












































![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)


![[第2版]Python機械学習プログラミング 第8章](https://cdn.slidesharecdn.com/ss_thumbnails/20181015-181029035714-thumbnail.jpg?width=640&height=640&fit=bounds)
![[最新版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180607030706-thumbnail.jpg?width=640&height=640&fit=bounds)





















