Copyright (C) DeNACo.,Ltd. All Rights Reserved.
22
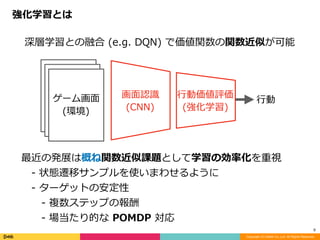
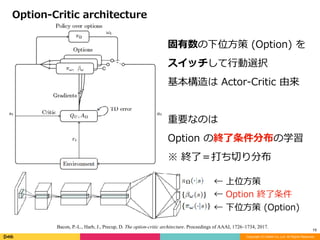
ハンドメイドな階層型強化学習
- h-DQN (Joshua B. Tenenbaum)
- SNN for HRL (Pieter Abbeel)
下位⽅策の異なる表現形式
- STRAW (Macro Action) 等
深層階層型強化学習のその他形式
→ 他にも⾊々あるし今後も出てくる可能性
(割と Option-Critic 強めではある)
Kulkarni, T. D., Narasimhan, K., Saeedi, A., Tenenbaum, J. B. Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and
Intrinsic Motivation. Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), 2016.
Florensa, C., Duan, Y., Abbeel, P. Stochastic Neural Networks for Hierarchical Reinforcement Learning. Proceedings of the International Conference on
Learning Representations (ICLR 2017), 2017.
Vezhnevets, A., Mnih, V., Agapiou, J., Osindero, S., Graves, A., Vinyals, O., Kavukcuoglu, K. Strategic Attentive Writer for Learning Macro-Actions.
ArXiv. Retrieved from https://arxiv.org/abs/1606.04695, 2016.
23.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
23
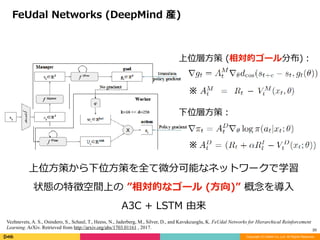
Option 打ち切り分布学習の理論拡張 (Peng Q(λ) のある種の近似)
- Learning with options that terminate off-policy
下位⽅策の学習に利⽤可能な後知恵強化学習 (UFVA 由来)
- Hindsight Experience Replay
- Hindsight Policy Gradients
- (類似) Importance Sampled Option-Critic for More Sample
Efficient Reinforcement Learning
汎化に対する解釈性の付与
- Successor Features for Transfer in Reinforcement Learning
- Hierarchical and Interpretable Skill Acquisition
in Multi-task Reinforcement Learning
HRL 論⽂紹介
24.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
24
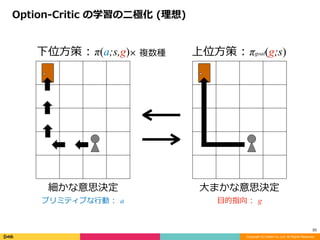
サブゴール = Option の打ち切り分布を如何に学習するか
Option-Critic だと学習される階層構造が⼆極化する危険
Option 打ち切り分布学習の理論拡張
25.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
25
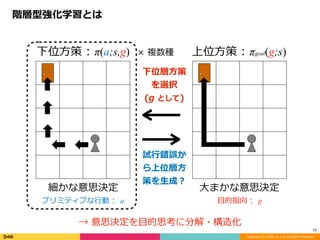
Option-Critic の学習の⼆極化 (理想)
× 複数種
細かな意思決定
プリミティブな⾏動 : a
⼤まかな意思決定
⽬的指向 : g
下位⽅策 : π(a;s,g) 上位⽅策 : πgoal(g;s)
26.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
26
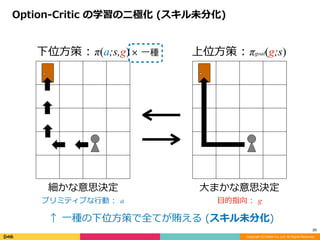
× ⼀種
Option-Critic の学習の⼆極化 (スキル未分化)
↑ ⼀種の下位⽅策で全てが賄える (スキル未分化)
細かな意思決定
プリミティブな⾏動 : a
⼤まかな意思決定
⽬的指向 : g
下位⽅策 : π(a;s,g) 上位⽅策 : πgoal(g;s)
27.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
27
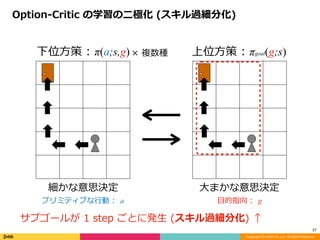
× 複数種
Option-Critic の学習の⼆極化 (スキル過細分化)
サブゴールが 1 step ごとに発⽣ (スキル過細分化) ↑
細かな意思決定
プリミティブな⾏動 : a
⼤まかな意思決定
⽬的指向 : g
下位⽅策 : π(a;s,g) 上位⽅策 : πgoal(g;s)
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
29
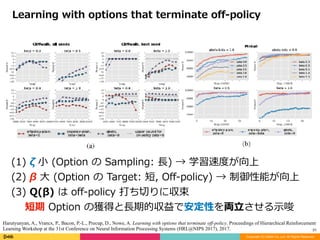
Learning with options that terminate off-policy
peng Q(λ) との対応から β の成分をパラメータを分離
実際の終了分布 ζ という概念の導⼊
Harutyunyan, A., Vrancx, P., Bacon, P.-L., Precup, D., Nowe, A. Learning with options that terminate off-policy. Proceedings of Hierarchical Reinforcement
Learning Workshop at the 31st Conference on Neural Information Processing Systems (HRL@NIPS 2017), 2017.
継続確率:
TD 誤差:
収益予測:
収益更新:
30.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
30
Learning with options that terminate off-policy
打ち切り時期に関して Sampling 分布 ζ と Target 分布 β が別
通常の Option-Critic は ζ = β
Harutyunyan, A., Vrancx, P., Bacon, P.-L., Precup, D., Nowe, A. Learning with options that terminate off-policy. Proceedings of Hierarchical Reinforcement
Learning Workshop at the 31st Conference on Neural Information Processing Systems (HRL@NIPS 2017), 2017.
← Target 分布使用
↑ Sampling 分布使用
31.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
31
Learning with options that terminate off-policy
(1) ζ ⼩ (Option の Sampling: ⻑) → 学習速度が向上
(2) β ⼤ (Option の Target: 短, Off-policy) → 制御性能が向上
(3) Q(β) は off-policy 打ち切りに収束
短期 Option の獲得と⻑期的収益で安定性を両⽴させる⽰唆
Harutyunyan, A., Vrancx, P., Bacon, P.-L., Precup, D., Nowe, A. Learning with options that terminate off-policy. Proceedings of Hierarchical Reinforcement
Learning Workshop at the 31st Conference on Neural Information Processing Systems (HRL@NIPS 2017), 2017.
32.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
32
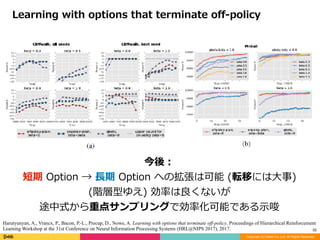
Learning with options that terminate off-policy
今後:
短期 Option → ⻑期 Option への拡張は可能 (転移には⼤事)
(階層型ゆえ) 効率は良くないが
途中式から重点サンプリングで効率化可能である⽰唆
Harutyunyan, A., Vrancx, P., Bacon, P.-L., Precup, D., Nowe, A. Learning with options that terminate off-policy. Proceedings of Hierarchical Reinforcement
Learning Workshop at the 31st Conference on Neural Information Processing Systems (HRL@NIPS 2017), 2017.
33.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
33
下位⽅策の学習に利⽤可能な後知恵強化学習
上位層⽅策と下位層⽅策 (複数) を両⽅が学習するから
学習が⾮常に困難 & 時間がかかる
→ 同時に複数の下位⽅策を学習して効率化
34.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
34
通常 RL の拡張アルゴリズム
Universal Value Function Approximators (UVFA)
→ 下位層⽅策と表現形式がほぼ同様
後知恵 (ある種の記憶改竄) による効率改善
→ HER, HPG
最初からゴール状態を定義して学習 ↓
下位⽅策の学習に利⽤可能な後知恵強化学習
35.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
35
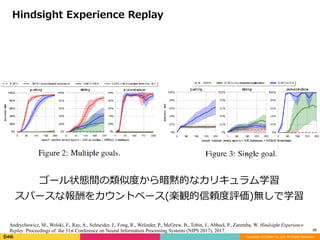
あらかじめゴールを決めて学習を開始
実際の結果系列から ”訪問状態がゴールだった” を書き換えて
経験再⽣して学習 (スパース報酬のための⼿法)
Hindsight Experience Replay
← 後知恵
(⽬的の記憶の改竄)
Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., McGrew, B., Tobin, J., Abbeel, P., Zaremba, W. Hindsight Experience
Replay. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
36.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
36
ゴール状態間の類似度から暗黙的なカリキュラム学習
スパースな報酬をカウントベース(楽観的信頼度評価)無しで学習
Hindsight Experience Replay
Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., McGrew, B., Tobin, J., Abbeel, P., Zaremba, W. Hindsight Experience
Replay. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
37.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
37
異なるゴールに向かって⽣成された軌跡を
⽅策分布の学習に利⽤ (近似版も提案)
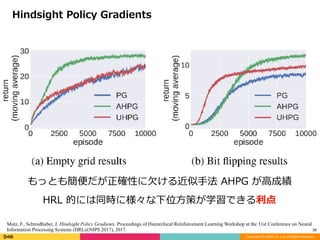
Hindsight Policy Gradients
↓
Importance sampling
Mutz, F., Schmidhuber, J. Hindsight Policy Gradients. Proceedings of Hierarchical Reinforcement Learning Workshop at the 31st Conference on Neural
Information Processing Systems (HRL@NIPS 2017), 2017.
いつもの⽅策勾配:
後知恵⽅策勾配:
38.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
38
もっとも簡便だが正確性に⽋ける近似⼿法 AHPG が⾼成績
HRL 的には同時に様々な下位⽅策が学習できる利点
Hindsight Policy Gradients
Mutz, F., Schmidhuber, J. Hindsight Policy Gradients. Proceedings of Hierarchical Reinforcement Learning Workshop at the 31st Conference on Neural
Information Processing Systems (HRL@NIPS 2017), 2017.
39.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
39
ゴール状態間の類似度から暗黙的なカリキュラム学習
→ 関数近似の恩恵
ゴールの定義が明確でなくとも学習が進む
→ 階層型強化学習との相性:良(はず)
(現状の Option-Critic にそのままは使えない)
HER と HPG の共通点
最初からゴール状態を定義して学習 ↓
40.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
40
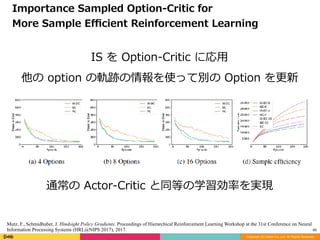
通常の Actor-Critic と同等の学習効率を実現
Importance Sampled Option-Critic for
More Sample Efficient Reinforcement Learning
IS を Option-Critic に応⽤
他の option の軌跡の情報を使って別の Option を更新
Mutz, F., Schmidhuber, J. Hindsight Policy Gradients. Proceedings of Hierarchical Reinforcement Learning Workshop at the 31st Conference on Neural
Information Processing Systems (HRL@NIPS 2017), 2017.
41.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
41
学習内容を汎化しやすい環境認識
あるいは
汎化しやすいスキル学習
課題の汎化を容易に
42.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
42
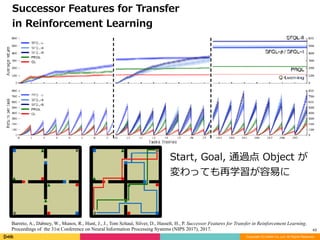
Successor Features for Transfer
in Reinforcement Learning
固定された報酬成分 ↓
タスク定義 ↑
報酬成分 = 収益成分=分解された特徴量 Φ
MDP を報酬予測から Φ の重み w を推定する逆問題化
→ 新しい MDP を再度の強化学習なしでも対処可能に
無更新 Bound:
Barreto, A., Dabney, W., Munos, R., Hunt, J., J., Tom Schaul, Silver, D., Hasselt, H., P. Successor Features for Transfer in Reinforcement Learning.
Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
43.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
43
Successor Features for Transfer
in Reinforcement Learning
Start, Goal, 通過点 Object が
変わっても再学習が容易に
Barreto, A., Dabney, W., Munos, R., Hunt, J., J., Tom Schaul, Silver, D., Hasselt, H., P. Successor Features for Transfer in Reinforcement Learning.
Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
44.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
44
スキルの ”意味” の学習
再利⽤可能性の向上
解釈可能な Option
45.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
45
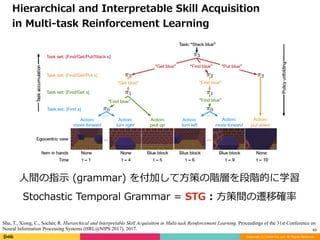
Hierarchical and Interpretable Skill Acquisition
in Multi-task Reinforcement Learning
Shu, T., Xiong, C., Socher, R. Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement Learning. Proceedings of the 31st Conference on
Neural Information Processing Systems (HRL@NIPS 2017), 2017.
⼈間の指⽰ (grammar) を付加して⽅策の階層を段階的に学習
Stochastic Temporal Grammar = STG : ⽅策間の遷移確率
46.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
46
Hierarchical and Interpretable Skill Acquisition
in Multi-task Reinforcement Learning
Shu, T., Xiong, C., Socher, R. Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement Learning. Proceedings of the 31st Conference on
Neural Information Processing Systems (HRL@NIPS 2017), 2017.
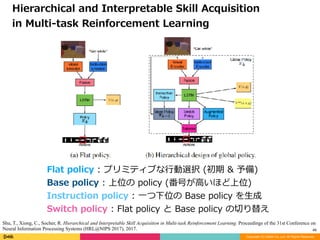
Flat policy : プリミティブな⾏動選択 (初期 & 予備)
Base policy : 上位の policy (番号が⾼いほど上位)
Instruction policy : ⼀つ下位の Base policy を⽣成
Switch policy : Flat policy と Base policy の切り替え
47.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
47
Hierarchical and Interpretable Skill Acquisition
in Multi-task Reinforcement Learning
Shu, T., Xiong, C., Socher, R. Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement Learning. Proceedings of the 31st Conference on
Neural Information Processing Systems (HRL@NIPS 2017), 2017.
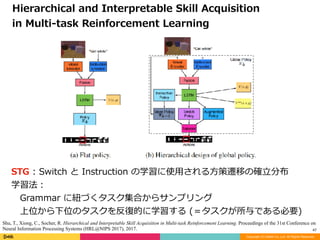
STG : Switch と Instruction の学習に使⽤される⽅策遷移の確⽴分布
学習法:
Grammar に紐づくタスク集合からサンプリング
上位から下位のタスクを反復的に学習する (=タスクが所与である必要)
48.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
48
Hierarchical and Interpretable Skill Acquisition
in Multi-task Reinforcement Learning
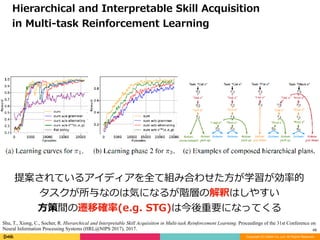
提案されているアイディアを全て組み合わせた⽅が学習が効率的
タスクが所与なのは気になるが階層の解釈はしやすい
⽅策間の遷移確率(e.g. STG)は今後重要になってくる
Shu, T., Xiong, C., Socher, R. Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement Learning. Proceedings of the 31st Conference on
Neural Information Processing Systems (HRL@NIPS 2017), 2017.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
50
階層型強化学習 = ⼈間的な⾏動学習には必要な要素
まだまだ萌芽的な研究領域
強化学習 + 深層学習 = 階層型への恩恵
数年前の Deep RL のように WS から
メインセッションに急成⻑していく可能性
雑感
51.
引⽤⽂献
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
51
[1] Bacon, P.-L., Harb, J., Precup, D. The option-critic architecture. Proceedings of AAAI, 1726–1734, 2017.
[2] Vezhnevets, A. S., Osindero, S., Schaul, T., Heess, N., Jaderberg, M., Silver, D., and Kavukcuoglu, K. FeUdal Networks for
Hierarchical Reinforcement Learning. ArXiv. Retrieved from http://arxiv.org/abs/1703.01161 , 2017.
[3] Kulkarni, T. D., Narasimhan, K., Saeedi, A., Tenenbaum, J. B. Hierarchical Deep Reinforcement Learning: Integrating
Temporal Abstraction and Intrinsic Motivation. Proceedings of the 30th Conference on Neural Information Processing Systems
(NIPS 2016), 2016.
[4] Florensa, C., Duan, Y., Abbeel, P. Stochastic Neural Networks for Hierarchical Reinforcement Learning. Proceedings of
the International Conference on Learning Representations (ICLR 2017), 2017.
[5] Vezhnevets, A., Mnih, V., Agapiou, J., Osindero, S., Graves, A., Vinyals, O., Kavukcuoglu, K. Strategic Attentive Writer for
Learning Macro-Actions. ArXiv. Retrieved from https://arxiv.org/abs/1606.04695, 2016.
[6] Harutyunyan, A., Vrancx, P., Bacon, P.-L., Precup, D., Nowe, A. Learning with options that terminate off-policy. Proceedings
of Hierarchical Reinforcement Learning Workshop at the 31st Conference on Neural Information Processing Systems
(HRL@NIPS 2017), 2017.
[7] Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., McGrew, B., Tobin, J., Abbeel, P., Zaremba, W.
Hindsight Experience Replay. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017),
2017.
[8] Mutz, F., Schmidhuber, J. Hindsight Policy Gradients. Proceedings of Hierarchical Reinforcement Learning Workshop at the
31st Conference on Neural Information Processing Systems (HRL@NIPS 2017), 2017.
[9] Goel, K., Brunskill, E. Importance Sampled Option-Critic for More Sample Efficient Reinforcement Learning. Proceedings
of Hierarchical Reinforcement Learning Workshop at the 31st Conference on Neural Information Processing Systems
(HRL@NIPS 2017), 2017.
[10] Barreto, A., Dabney, W., Munos, R., Hunt, J., J., Tom Schaul, Silver, D., Hasselt, H., P. Successor Features for Transfer in
Reinforcement Learning. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
[11] Shu, T., Xiong, C., Socher, R. Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement Learning.
Proceedings of the 31st Conference on Neural Information Processing Systems (HRL@NIPS 2017), 2017.
52.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
52
⾮ HRL の RL 論⽂もいくつか紹介
オマケ
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
54
Rollout するためには環境モデルが必要 (e.g. AlphaGo)
環境モデルを状態遷移のモデルから学習
しかし RL 精度×環境モデル学習で直列的に悪化
モデルフリー + モデルベース
55.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
55
Imagination-Augmented Agents
for Deep Reinforcement Learning
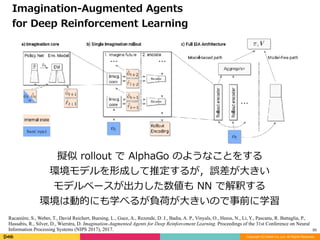
擬似 rollout で AlphaGo のようなことをする
環境モデルを形成して推定するが,誤差が⼤きい
モデルベースが出⼒した数値も NN で解釈する
環境は動的にも学べるが負荷が⼤きいので事前に学習
Racanière, S., Weber, T., David Reichert, Buesing, L., Guez, A., Rezende, D. J., Badia, A. P., Vinyals, O., Heess, N., Li, Y., Pascanu, R. Battaglia, P.,
Hassabis, R., Silver, D., Wierstra, D. Imagination-Augmented Agents for Deep Reinforcement Learning. Proceedings of the 31st Conference on Neural
Information Processing Systems (NIPS 2017), 2017.
56.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
56
Imagination-Augmented Agents
for Deep Reinforcement Learning
擬似 rollout で AlphaGo のようなことをする
環境モデルを形成して推定するが,誤差が⼤きい
モデルベースが出⼒した数値も NN で解釈する
環境は動的にも学べるが負荷が⼤きいので事前に学習
Racanière, S., Weber, T., David Reichert, Buesing, L., Guez, A., Rezende, D. J., Badia, A. P., Vinyals, O., Heess, N., Li, Y., Pascanu, R. Battaglia, P.,
Hassabis, R., Silver, D., Wierstra, D. Imagination-Augmented Agents for Deep Reinforcement Learning. Proceedings of the 31st Conference on Neural
Information Processing Systems (NIPS 2017), 2017.
57.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
57
環境の状態遷移サンプルは無限にある⽅が良い
記憶容量には限界が
→ 記憶の抽象化
記憶の抽象化
58.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
58
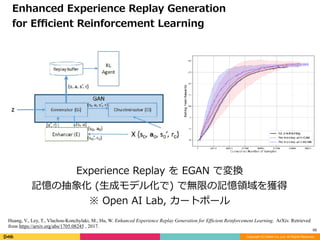
Experience Replay を EGAN で変換
記憶の抽象化 (⽣成モデル化で) で無限の記憶領域を獲得
※ Open AI Lab, カートポール
Enhanced Experience Replay Generation
for Efficient Reinforcement Learning
Huang, V., Ley, T., Vlachou-Konchylaki, M., Hu, W. Enhanced Experience Replay Generation for Efficient Reinforcement Learning. ArXiv. Retrieved
from https://arxiv.org/abs/1705.08245 , 2017.
59.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
59
ランダムな探索だと効率が悪い
関数近似による未知領域の過⼩評価を解決したい
→ 状態への訪問カウントで信頼度を評価 (楽観さ)
信頼度(訪問カウント)の評価は抽象化に向かない
→ ⼯夫が⾊々なされている
楽観的探索の⼯夫
60.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
60
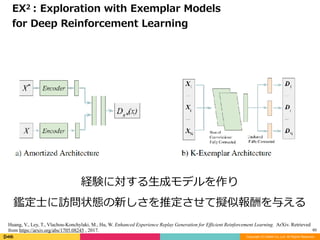
経験に対する⽣成モデルを作り
鑑定⼠に訪問状態の新しさを推定させて擬似報酬を与える
EX2 : Exploration with Exemplar Models
for Deep Reinforcement Learning
Huang, V., Ley, T., Vlachou-Konchylaki, M., Hu, W. Enhanced Experience Replay Generation for Efficient Reinforcement Learning. ArXiv. Retrieved
from https://arxiv.org/abs/1705.08245 , 2017.
61.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
61
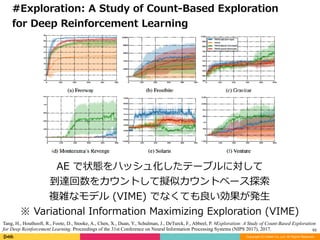
#Exploration: A Study of Count-Based Exploration
for Deep Reinforcement Learning
AE で状態をハッシュ化したテーブルに対して
到達回数をカウントして擬似カウントベース探索
複雑なモデル (VIME) でなくても良い効果が発⽣
※ Variational Information Maximizing Exploration (VIME)
Tang, H., Houthooft, R., Foote, D., Stooke, A., Chen, X., Duan, Y., Schulman, J., DeTurck, F., Abbeel, P. #Exploration: A Study of Count-Based Exploration
for Deep Reinforcement Learning. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
62.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
62
#Exploration: A Study of Count-Based Exploration
for Deep Reinforcement Learning
AE で状態をハッシュ化したテーブルに対して
到達回数をカウントして擬似カウントベース探索
複雑なモデル (VIME) でなくても良い効果が発⽣
※ Variational Information Maximizing Exploration (VIME)
Tang, H., Houthooft, R., Foote, D., Stooke, A., Chen, X., Duan, Y., Schulman, J., DeTurck, F., Abbeel, P. #Exploration: A Study of Count-Based Exploration
for Deep Reinforcement Learning. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
63.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
63
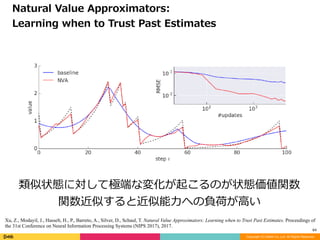
類似状態に対して極端な変化が起こるのが状態価値関数
関数近似すると近似能⼒への負荷が⾼い
価値関数の性質に由来する近似性能の向上
64.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
64
類似状態に対して極端な変化が起こるのが状態価値関数
関数近似すると近似能⼒への負荷が⾼い
Natural Value Approximators:
Learning when to Trust Past Estimates
Xu, Z., Modayil, J., Hasselt, H., P., Barreto, A., Silver, D., Schaul, T. Natural Value Approximators: Learning when to Trust Past Estimates. Proceedings of
the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
65.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
65
Natural Value Approximators:
Learning when to Trust Past Estimates
⾃然価値:
損失関数:
更新式の逆算から⾃然価値を表現
⾃然価値推定と通常価値推定との重み付け変数 β を学習
ある種の Semi-MDP にも使える
Xu, Z., Modayil, J., Hasselt, H., P., Barreto, A., Silver, D., Schaul, T. Natural Value Approximators: Learning when to Trust Past Estimates. Proceedings of
the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
66.
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
66
更新式の逆算から⾃然価値を表現
⾃然価値推定と通常価値推定との重み付け変数 β を学習
ある種の Semi-MDP にも使える
Natural Value Approximators:
Learning when to Trust Past Estimates
Xu, Z., Modayil, J., Hasselt, H., P., Barreto, A., Silver, D., Schaul, T. Natural Value Approximators: Learning when to Trust Past Estimates. Proceedings of
the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
引⽤⽂献
Copyright (C) DeNACo.,Ltd. All Rights Reserved.
68
[9] Racanière, S., Weber, T., David Reichert, Buesing, L., Guez, A., Rezende, D. J., Badia, A. P., Vinyals, O., Heess, N., Li, Y.,
Pascanu, R. Battaglia, P., Hassabis, R., Silver, D., Wierstra, D. Imagination-Augmented Agents for Deep Reinforcement
Learning. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
[10] Huang, V., Ley, T., Vlachou-Konchylaki, M., Hu, W. Enhanced Experience Replay Generation for Efficient Reinforcement
Learning. ArXiv. Retrieved from https://arxiv.org/abs/1705.08245 , 2017.
[11] Fu, J., Co-Reyes, J., Levine, S. EX2 : Exploration with Exemplar Models for Deep Reinforcement Learning. Proceedings of
the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
[12] Tang, H., Houthooft, R., Foote, D., Stooke, A., Chen, X., Duan, Y., Schulman, J., DeTurck, F., Abbeel, P. #Exploration: A
Study of Count-Based Exploration for Deep Reinforcement Learning. Proceedings of the 31st Conference on Neural Information
Processing Systems (NIPS 2017), 2017.
[13] Xu, Z., Modayil, J., Hasselt, H., P., Barreto, A., Silver, D., Schaul, T. Natural Value Approximators: Learning when to Trust
Past Estimates. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.




























![引⽤⽂献
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
51
[1] Bacon, P.-L., Harb, J., Precup, D. The option-critic architecture. Proceedings of AAAI, 1726–1734, 2017.
[2] Vezhnevets, A. S., Osindero, S., Schaul, T., Heess, N., Jaderberg, M., Silver, D., and Kavukcuoglu, K. FeUdal Networks for
Hierarchical Reinforcement Learning. ArXiv. Retrieved from http://arxiv.org/abs/1703.01161 , 2017.
[3] Kulkarni, T. D., Narasimhan, K., Saeedi, A., Tenenbaum, J. B. Hierarchical Deep Reinforcement Learning: Integrating
Temporal Abstraction and Intrinsic Motivation. Proceedings of the 30th Conference on Neural Information Processing Systems
(NIPS 2016), 2016.
[4] Florensa, C., Duan, Y., Abbeel, P. Stochastic Neural Networks for Hierarchical Reinforcement Learning. Proceedings of
the International Conference on Learning Representations (ICLR 2017), 2017.
[5] Vezhnevets, A., Mnih, V., Agapiou, J., Osindero, S., Graves, A., Vinyals, O., Kavukcuoglu, K. Strategic Attentive Writer for
Learning Macro-Actions. ArXiv. Retrieved from https://arxiv.org/abs/1606.04695, 2016.
[6] Harutyunyan, A., Vrancx, P., Bacon, P.-L., Precup, D., Nowe, A. Learning with options that terminate off-policy. Proceedings
of Hierarchical Reinforcement Learning Workshop at the 31st Conference on Neural Information Processing Systems
(HRL@NIPS 2017), 2017.
[7] Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., McGrew, B., Tobin, J., Abbeel, P., Zaremba, W.
Hindsight Experience Replay. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017),
2017.
[8] Mutz, F., Schmidhuber, J. Hindsight Policy Gradients. Proceedings of Hierarchical Reinforcement Learning Workshop at the
31st Conference on Neural Information Processing Systems (HRL@NIPS 2017), 2017.
[9] Goel, K., Brunskill, E. Importance Sampled Option-Critic for More Sample Efficient Reinforcement Learning. Proceedings
of Hierarchical Reinforcement Learning Workshop at the 31st Conference on Neural Information Processing Systems
(HRL@NIPS 2017), 2017.
[10] Barreto, A., Dabney, W., Munos, R., Hunt, J., J., Tom Schaul, Silver, D., Hasselt, H., P. Successor Features for Transfer in
Reinforcement Learning. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
[11] Shu, T., Xiong, C., Socher, R. Hierarchical and Interpretable Skill Acquisition in Multi-task Reinforcement Learning.
Proceedings of the 31st Conference on Neural Information Processing Systems (HRL@NIPS 2017), 2017.](https://image.slidesharecdn.com/hrlatnips2017plusv3pub-180123033658/85/NIPS2017-PFN-Hierarchical-Reinforcement-Learning-51-320.jpg)










![引⽤⽂献
Copyright (C) DeNA Co.,Ltd. All Rights Reserved.
68
[9] Racanière, S., Weber, T., David Reichert, Buesing, L., Guez, A., Rezende, D. J., Badia, A. P., Vinyals, O., Heess, N., Li, Y.,
Pascanu, R. Battaglia, P., Hassabis, R., Silver, D., Wierstra, D. Imagination-Augmented Agents for Deep Reinforcement
Learning. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
[10] Huang, V., Ley, T., Vlachou-Konchylaki, M., Hu, W. Enhanced Experience Replay Generation for Efficient Reinforcement
Learning. ArXiv. Retrieved from https://arxiv.org/abs/1705.08245 , 2017.
[11] Fu, J., Co-Reyes, J., Levine, S. EX2 : Exploration with Exemplar Models for Deep Reinforcement Learning. Proceedings of
the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.
[12] Tang, H., Houthooft, R., Foote, D., Stooke, A., Chen, X., Duan, Y., Schulman, J., DeTurck, F., Abbeel, P. #Exploration: A
Study of Count-Based Exploration for Deep Reinforcement Learning. Proceedings of the 31st Conference on Neural Information
Processing Systems (NIPS 2017), 2017.
[13] Xu, Z., Modayil, J., Hasselt, H., P., Barreto, A., Silver, D., Schaul, T. Natural Value Approximators: Learning when to Trust
Past Estimates. Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), 2017.](https://image.slidesharecdn.com/hrlatnips2017plusv3pub-180123033658/85/NIPS2017-PFN-Hierarchical-Reinforcement-Learning-68-320.jpg)

![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]What Matters In On-Policy Reinforcement Learning? A Large-Scale Empiri...](https://cdn.slidesharecdn.com/ss_thumbnails/20200619misono-200630053718-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)






