GPT4とは
• GPTの歴史
– GPT(2018,著者4名)
• Improving Language Understanding by Generative Pre-Training
– Pre-training + Fine-tuning 最高👍
– GPT2(2018, 著者6名)
• Language Models are Unsupervised Multitask Learners
– Pre-training + Zero-shot prompting 最高👍
– GPT3(2020, 著者31名)
• Language Models are Few-Shot Learners
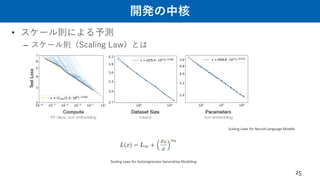
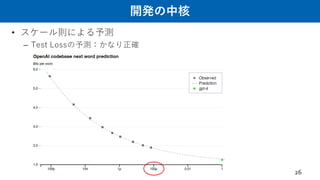
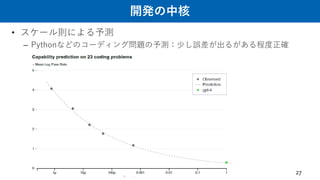
– Pre-Training + Few-shot In-context Learning 最高👍 スケーリング則の発見🔥
– GPT3.5 [URL]: InstructGPT & ChatGPT(2022, 著者20名)
• Training language models to follow instructions with human feedback
– Pre-Training + Instruction Following 最高👍
– GPT4(2023, 著者?名)
• GPT-4 Technical Report
– Pre-Training + Instruction Following やっぱり最高🔥🔥🔥 6
7.
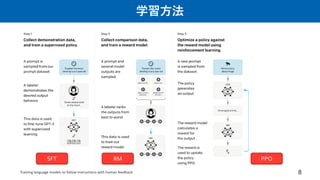
学習方法
• 第一段階:事前学習
– 手法:predictionof the next word.
– データ:
• a large dataset of text from the Internet
• データセットから性的コンテンツのサンプルをフィルタリング
– 分類器や語彙ベースの特定手法を用いてフィルタリング
• 第二段階:RLHF
– 手法:SFT -> RM (+RBRMs+Hullcination対策) -> PPO
– データ:
• プロンプトデータ
– The main dataset comes from our production traffic (with consent from users).
– We use prompts written by our red teamers, model-generated synthetic prompts, and prompts from other internal or public datasets.
• デモデータ+報酬ラベル
– from human trainers.
• 本番環境:Content Classifier for system safety
※ Finished training in August of 2022.
7
学習方法
• Hullcination対策
– open-domainhallucinations
• collect real-world ChatGPT data that has been flagged by users as being not factual,
and collect additional labeled comparison data that we use to train our reward models.
– closed-domain hallucinations
• use GPT-4 itself to generate synthetic data -> mix into RM dataset
• zero-shot?
11
12.
学習方法
• Content Classifierfor system safety
– 目的:有害コンテンツを含むユーザ入力をブロックする
– OpenAI constantly developing and improving these classifiers.
– Moderation API
– Classifierの学習自体にGPT4を活用している
• 分類ルールをプロンプトとして与えて、間違ってラベル付けされたテストデータをZero-
shot classificationで特定
• Few-shot classificationで学習データのラベル付け
12
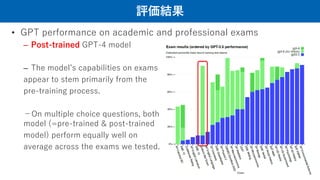
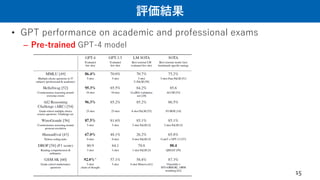
評価結果
• GPT performanceon academic and professional exams
– Post-trained GPT-4 model
– The model’s capabilities on exams
appear to stem primarily from the
pre-training process.
-On multiple choice questions, both the base GPT-4 model and the RLHF
model (=pre-trained & post-trained
model) perform equally well on
average across the exams we tested.
14
評価結果
• Truthful QA
–To tests the model’s ability to separate fact from an adversarially-selected
set of incorrect statements
– after RLHF post-training we observe large improvements over GPT-3.5.
16
17.
評価結果
• GPT performanceon academic and professional exams
– Contamination Check
• For test data appearing in the training set
• Using substring match
– 学習データと評価データを前処理(空白や記号を除去)
– 各評価データについて、50文字の部分文字列を3回、無作為に選択する
– サンプリングされた3つの評価用部分文字列のいずれかが、学習データに存在するかをチェック
– 存在が確認された評価データを除外して再評価する
• False Positive や False Negativeの可能性あり
– The RLHF post-training dataset is vastly smaller than the pretraining set
and unlikely to have any particular question contaminated. However we did
not check explicitly.
17
18.
評価結果
• Visual Inputs
–The standard test-time techniques developed for language models (e.g.
few-shot prompting, chain-of-thought, etc) are similarly effective
18
19.
評価結果
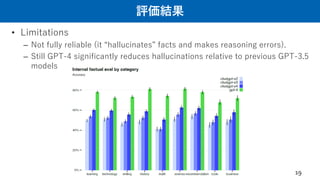
• Limitations
– Notfully reliable (it “hallucinates” facts and makes reasoning errors).
– Still GPT-4 significantly reduces hallucinations relative to previous GPT-3.5
models
19
20.
評価結果
• Limitations
– GPT-4generally lacks knowledge of events that have occurred after the
vast majority of its pre-training data cuts off in September 2021.
– 多くの領域で能力を発揮しているとは思えないような単純な推論ミスをするこ
ともある
– ユーザーから明らかに間違ったことを言われても、過度に騙されることもある
– 人間と同じように難しい問題で失敗することもある.
• 例: 作成したコードにセキュリティの脆弱性を持ち込むことも.
20
21.
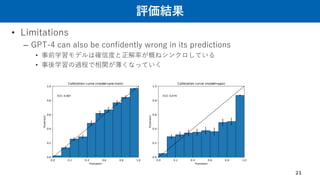
評価結果
• Limitations
– GPT-4can also be confidently wrong in its predictions
• 事前学習モデルは確信度と正解率が概ねシンクロしている
• 事後学習の過程で相関が薄くなっていく
21
22.
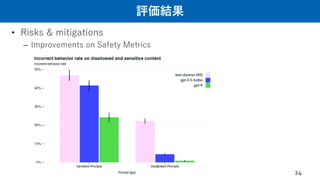
評価結果
• Risks &mitigations
– Adversarial Testing via Domain Experts
• GPT4特有の問題への対応
– long-term AI alignment risks, cybersecurity, 個人情報, and international security
• 50以上の領域の専門家からのアドバイスや訓練データを改善に利用している
22
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
GPT-4Technical Report
Takeshi Kojima, Matsuo Lab](https://image.slidesharecdn.com/dl20230428v1-230505064312-1d5655e9/85/DL-GPT-4Technical-Report-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
GPT-4Technical Report
Takeshi Kojima, Matsuo Lab](https://image.slidesharecdn.com/dl20230428v1-230505064312-1d5655e9/75/DL-GPT-4Technical-Report-1-2048.jpg)




![GPT4とは
• GPTの歴史
– GPT(2018, 著者4名)
• Improving Language Understanding by Generative Pre-Training
– Pre-training + Fine-tuning 最高👍
– GPT2(2018, 著者6名)
• Language Models are Unsupervised Multitask Learners
– Pre-training + Zero-shot prompting 最高👍
– GPT3(2020, 著者31名)
• Language Models are Few-Shot Learners
– Pre-Training + Few-shot In-context Learning 最高👍 スケーリング則の発見🔥
– GPT3.5 [URL]: InstructGPT & ChatGPT(2022, 著者20名)
• Training language models to follow instructions with human feedback
– Pre-Training + Instruction Following 最高👍
– GPT4(2023, 著者?名)
• GPT-4 Technical Report
– Pre-Training + Instruction Following やっぱり最高🔥🔥🔥 6](https://image.slidesharecdn.com/dl20230428v1-230505064312-1d5655e9/85/DL-GPT-4Technical-Report-6-320.jpg)




















![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)







![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]It's not just size that maters small language models are also few sho...](https://cdn.slidesharecdn.com/ss_thumbnails/itsnotjustsizethatmaterssmalllanguagemodelsarealsofew-shotlearners-210910034516-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Shaping Belief States with Generative Environment Models for RL](https://cdn.slidesharecdn.com/ss_thumbnails/20190705suzuki-191204061058-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)





























