Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Deep Learning JP
PPTX, PDF
2,079 views
【DL輪読会】A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
2022/12/2 Deep Learning JP http://deeplearning.jp/seminar-2/
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 55 times
1
/ 21
2
/ 21
3
/ 21
4
/ 21
5
/ 21
6
/ 21
7
/ 21
8
/ 21
Most read
9
/ 21
10
/ 21
11
/ 21
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
Most read
18
/ 21
19
/ 21
20
/ 21
21
/ 21
Most read
More Related Content
PDF
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
PDF
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
PPTX
【DL輪読会】ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Deep Learning JP
PPTX
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
PPTX
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...
by
Deep Learning JP
【DL輪読会】ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Deep Learning JP
【DL輪読会】DayDreamer: World Models for Physical Robot Learning
by
Deep Learning JP
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
What's hot
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
PDF
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PPTX
【DL輪読会】DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Dri...
by
Deep Learning JP
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PDF
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
PDF
【DL輪読会】A Path Towards Autonomous Machine Intelligence
by
Deep Learning JP
PDF
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
PDF
HiPPO/S4解説
by
Morpho, Inc.
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
PPTX
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PDF
Data-Centric AIの紹介
by
Kazuyuki Miyazawa
PPTX
モデル高速化百選
by
Yusuke Uchida
PDF
Active Learning 入門
by
Shuyo Nakatani
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
近年のHierarchical Vision Transformer
by
Yusuke Uchida
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
by
Deep Learning JP
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
【DL輪読会】DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Dri...
by
Deep Learning JP
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
Word Tour: One-dimensional Word Embeddings via the Traveling Salesman Problem...
by
joisino
【DL輪読会】A Path Towards Autonomous Machine Intelligence
by
Deep Learning JP
[DL輪読会]ICLR2020の分布外検知速報
by
Deep Learning JP
HiPPO/S4解説
by
Morpho, Inc.
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
by
Deep Learning JP
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
Data-Centric AIの紹介
by
Kazuyuki Miyazawa
モデル高速化百選
by
Yusuke Uchida
Active Learning 入門
by
Shuyo Nakatani
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
Similar to 【DL輪読会】A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PPTX
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
PDF
LSTM (Long short-term memory) 概要
by
Kenji Urai
PPTX
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
PPTX
「解説資料」ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Takumi Ohkuma
PPTX
【論文読み会】Pyraformer_Low-Complexity Pyramidal Attention for Long-Range Time Seri...
by
ARISE analytics
PPTX
Icml2018読み会_overview&GANs
by
Kentaro Tachibana
PDF
機械学習を使った時系列売上予測
by
DataRobotJP
PDF
時系列問題に対するCNNの有用性検証
by
Masaharu Kinoshita
PDF
時系列分析入門
by
Miki Katsuragi
PPTX
「解説資料」MetaFormer is Actually What You Need for Vision
by
Takumi Ohkuma
PPTX
Qlik Predictによる多変量時系列予測:複雑な要因を織り込んだビジネス予測を実践
by
QlikPresalesJapan
PDF
NIPS2019 Amazon「think globally, act locally : a deep neural network approach...
by
SaeruYamamuro
PDF
自己教師あり学習を導入したWavelet Vision TransformerによるDeepfake検出の高精度化
by
MILab
PPTX
NeurIPS2019参加報告
by
Masanari Kimura
PDF
SOINN F-1 (Aug. 2021)
by
SOINN
PDF
GTC 2016 ディープラーニング最新情報
by
NVIDIA Japan
PDF
Mln23 aws forecast-report1
by
Akihiro Horikawa
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...
by
SSII
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
LSTM (Long short-term memory) 概要
by
Kenji Urai
[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...
by
Yusuke Iwasawa
「解説資料」ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
by
Takumi Ohkuma
【論文読み会】Pyraformer_Low-Complexity Pyramidal Attention for Long-Range Time Seri...
by
ARISE analytics
Icml2018読み会_overview&GANs
by
Kentaro Tachibana
機械学習を使った時系列売上予測
by
DataRobotJP
時系列問題に対するCNNの有用性検証
by
Masaharu Kinoshita
時系列分析入門
by
Miki Katsuragi
「解説資料」MetaFormer is Actually What You Need for Vision
by
Takumi Ohkuma
Qlik Predictによる多変量時系列予測:複雑な要因を織り込んだビジネス予測を実践
by
QlikPresalesJapan
NIPS2019 Amazon「think globally, act locally : a deep neural network approach...
by
SaeruYamamuro
自己教師あり学習を導入したWavelet Vision TransformerによるDeepfake検出の高精度化
by
MILab
NeurIPS2019参加報告
by
Masanari Kimura
SOINN F-1 (Aug. 2021)
by
SOINN
GTC 2016 ディープラーニング最新情報
by
NVIDIA Japan
Mln23 aws forecast-report1
by
Akihiro Horikawa
More from Deep Learning JP
PDF
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】Deep Transformers without Shortcuts: Modifying Self-attention for Fait...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】VIP: Towards Universal Visual Reward and Representation via Value-Impl...
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
1.
A Time Series
is Worth 64 Words: Long-term Forecasting with Transformers 岡田 領 / Ryo Okada
2.
書誌情報 • ICML2023 Boarerline •
多変量時系列予測と自己教師あり学習のための効果的なTransformer(パッチ分割とチャネ ル独立) • (タイトルはVITの”An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”より) • 時系列長期予測.評価は高くないが,性能が出ている.
3.
背景と関連研究 • 時系列でのTransformer • Informer,
Autoformer, FEDFormer.. • Attentionの複雑性を軽減し,長期予測で性能向上,有効性が示されてきた • Are Transformers Effective for Time Series Forecasting?, 2022.5 Arxiv • 非常に単純な線形モデルがTransformerモデルを超える性能 • 時系列予測におけるTransformerの有用性に疑問を投げかけている • Accepted to AAAI 2023
4.
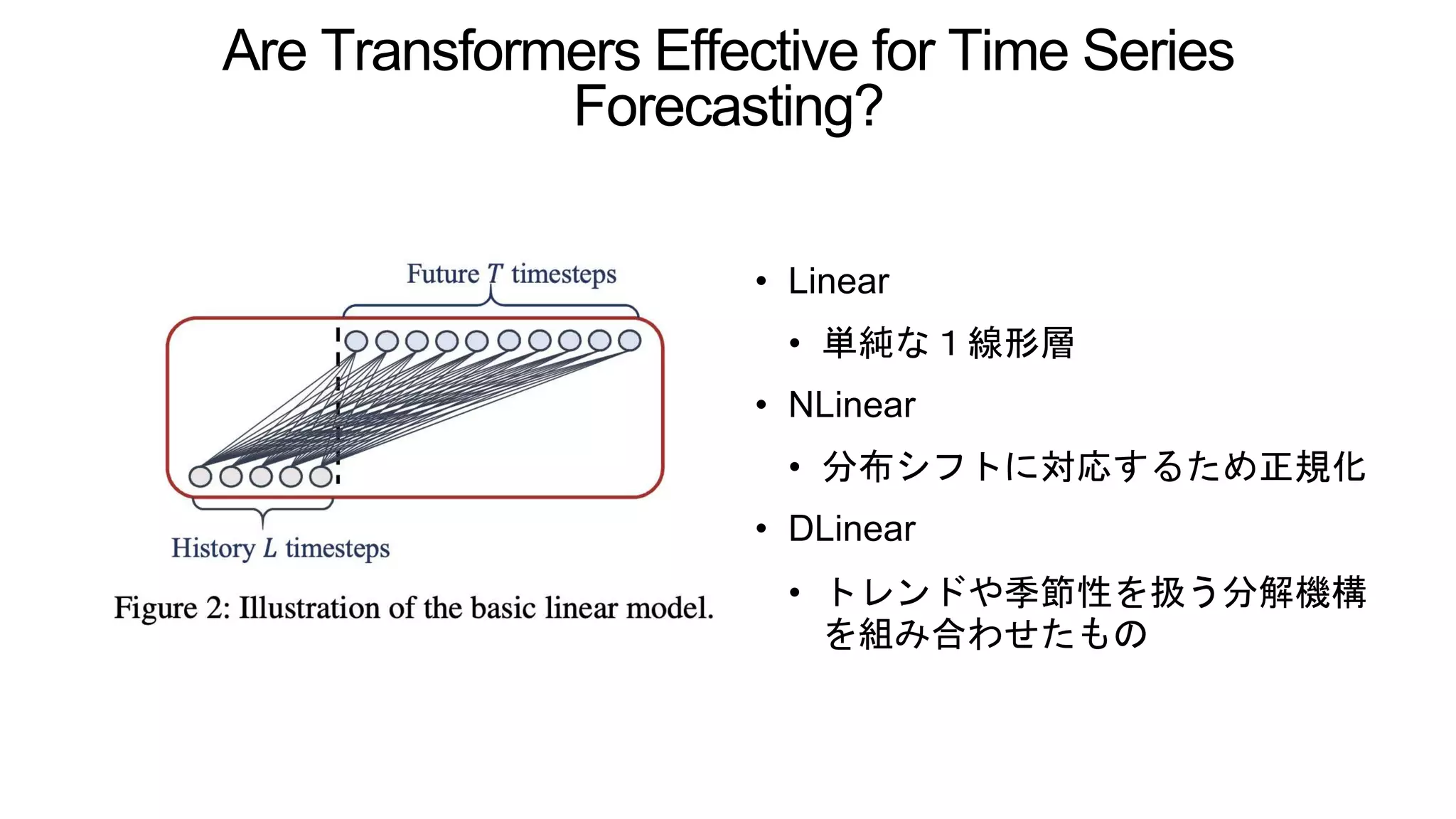
Are Transformers Effective
for Time Series Forecasting? • Itelated multi-step予測(IMS) • 1ステップ毎の予測器を学習し,反復してマルチステップの予測に適用 • 長期予測において誤差が蓄積していく欠点 • Direct multi-step 予測(DMS) • 一度にマルチステップ分予測するように学習 • 今までTransformerベースモデルと比較されていた非Transformerベースライ ンは自己回帰,IMS予測のもの • 単純な線形のDMSモデルを用意して,Transformerベースと比較.
5.
Are Transformers Effective
for Time Series Forecasting? • Linear • 単純な1線形層 • NLinear • 分布シフトに対応するため正規化 • DLinear • トレンドや季節性を扱う分解機構 を組み合わせたもの
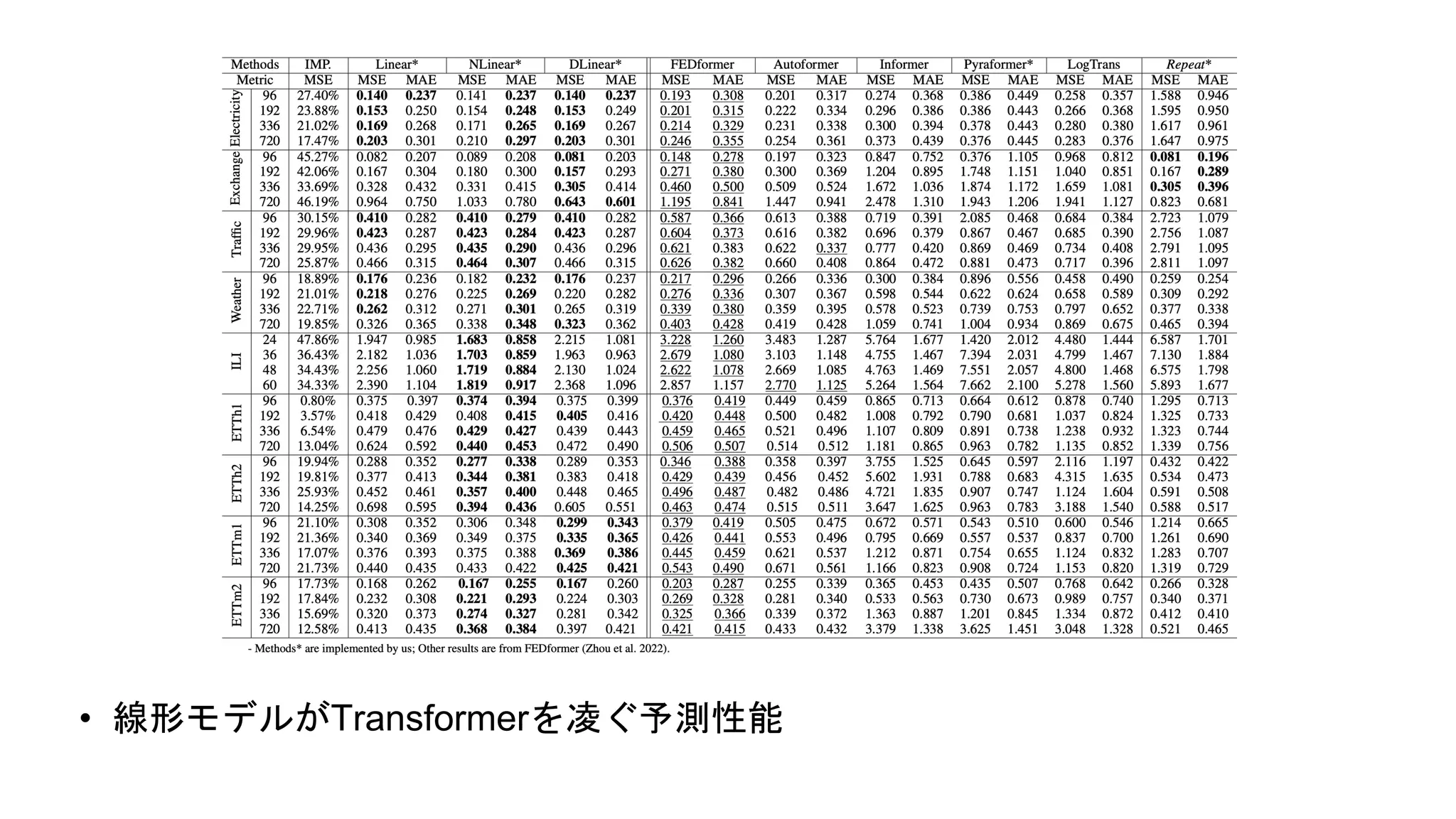
6.
• 線形モデルがTransformerを凌ぐ予測性能
7.
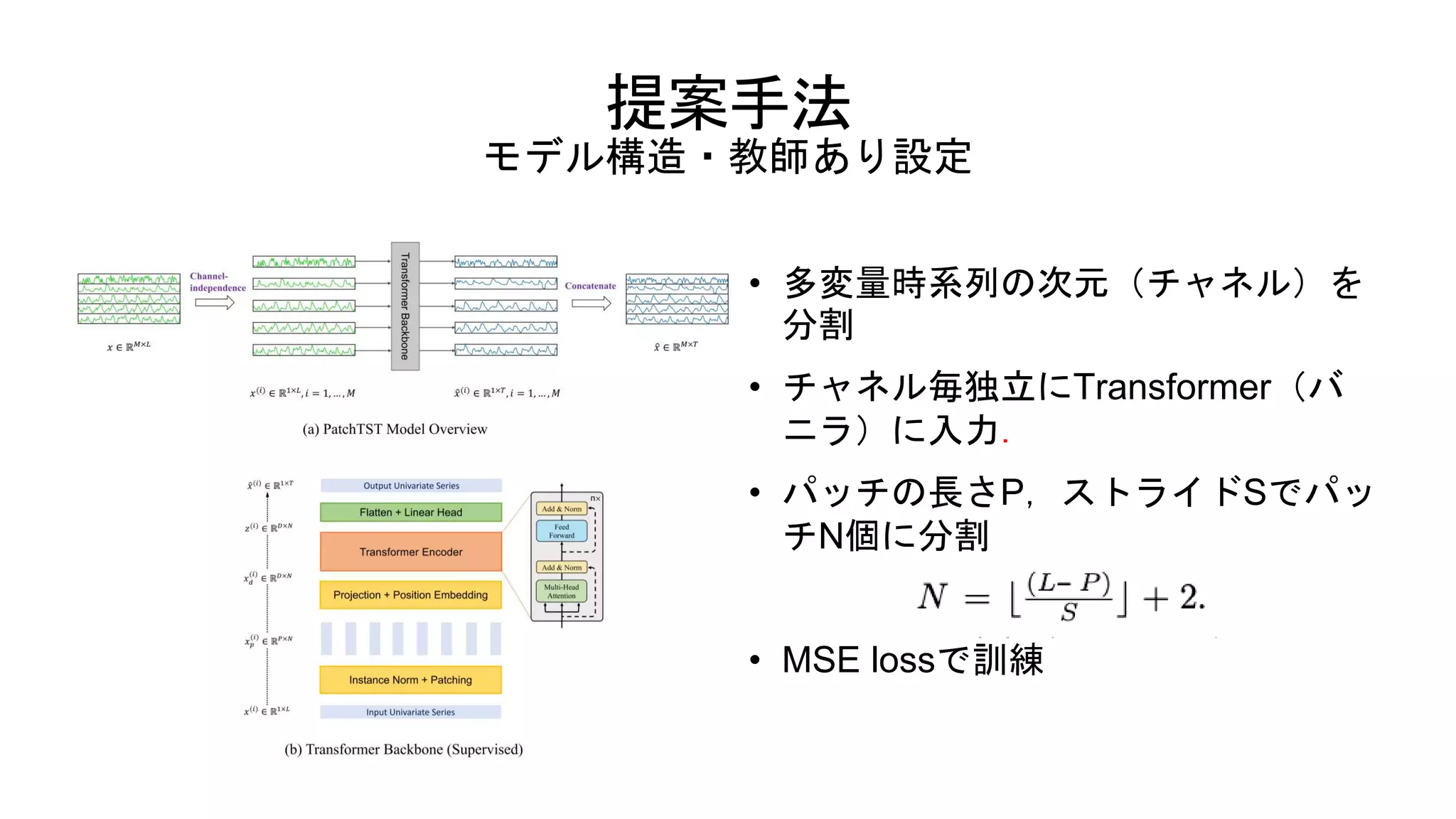
今回紹介する論文の概要 • 本論文ではパッチ分割とチャネル独立によってTransformerの有効性を再度示す • PatchTSTの提案 •
時系列のTransformerで用いられてこなかったパッチ分割 • パッチの塊に分割することで計算量が分割分削減される • 入力系列が短くなるので長期の履歴も参照しやすくなる • パッチをマスクすることで自己教師あり学習にも効果 • (多変量時系列を分割して)単時系列でTransformerに入力する • 単時系列にすることでアテンションマップの柔軟性が上がる(系列ごと個別に パターン化できる) • 複雑性が落ちるので,学習が容易になる(少ないデータで収束)
8.
提案手法 モデル構造・教師あり設定 • 多変量時系列の次元(チャネル)を 分割 • チャネル毎独立にTransformer(バ ニラ)に入力. •
パッチの長さP,ストライドSでパッ チN個に分割 • MSE lossで訓練
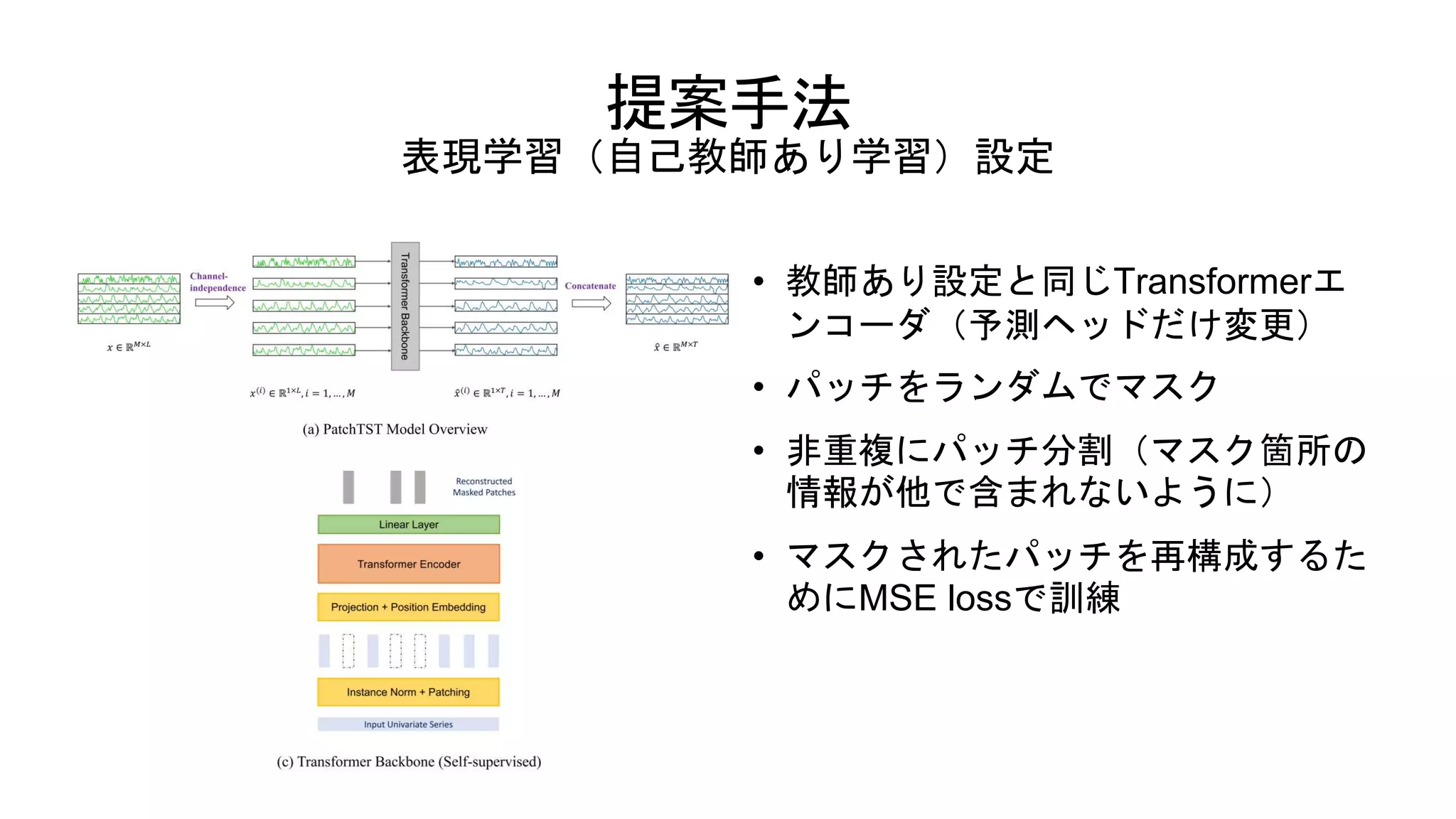
9.
提案手法 表現学習(自己教師あり学習)設定 • 教師あり設定と同じTransformerエ ンコーダ(予測ヘッドだけ変更) • パッチをランダムでマスク •
非重複にパッチ分割(マスク箇所の 情報が他で含まれないように) • マスクされたパッチを再構成するた めにMSE lossで訓練
10.
実験 • 多変量の時系列予測の評価 • ベースライン •
SOTAトランスフォーマーベースモデル • FEDformer, Autoformer, Informer, Pyraformer, LogTrans • 非トランスフォーマー • DLinear • MSEとMAEで評価
11.
実験結果 多変量長期予測 • 多変量の長期予測 • 提案手法は全てのtransfomer ベースモデルのベースライン を凌駕 •
大規模データセット( Weather、Traffic、Electricity )やILIデータセットにおいて DLinearモデルより優れた性能
12.
実験 • 表現学習の設定 • 自己教師あり事前学習を100エポック学習 •
その後,2つのパターンで教師あり学習(それぞれ評価) • Linear Probing:モデルヘッドのみ20エポック学習 • End2end fine tuning: • モデルヘッドを10エポック更新 • ネットワーク全体を20エポック学習
13.
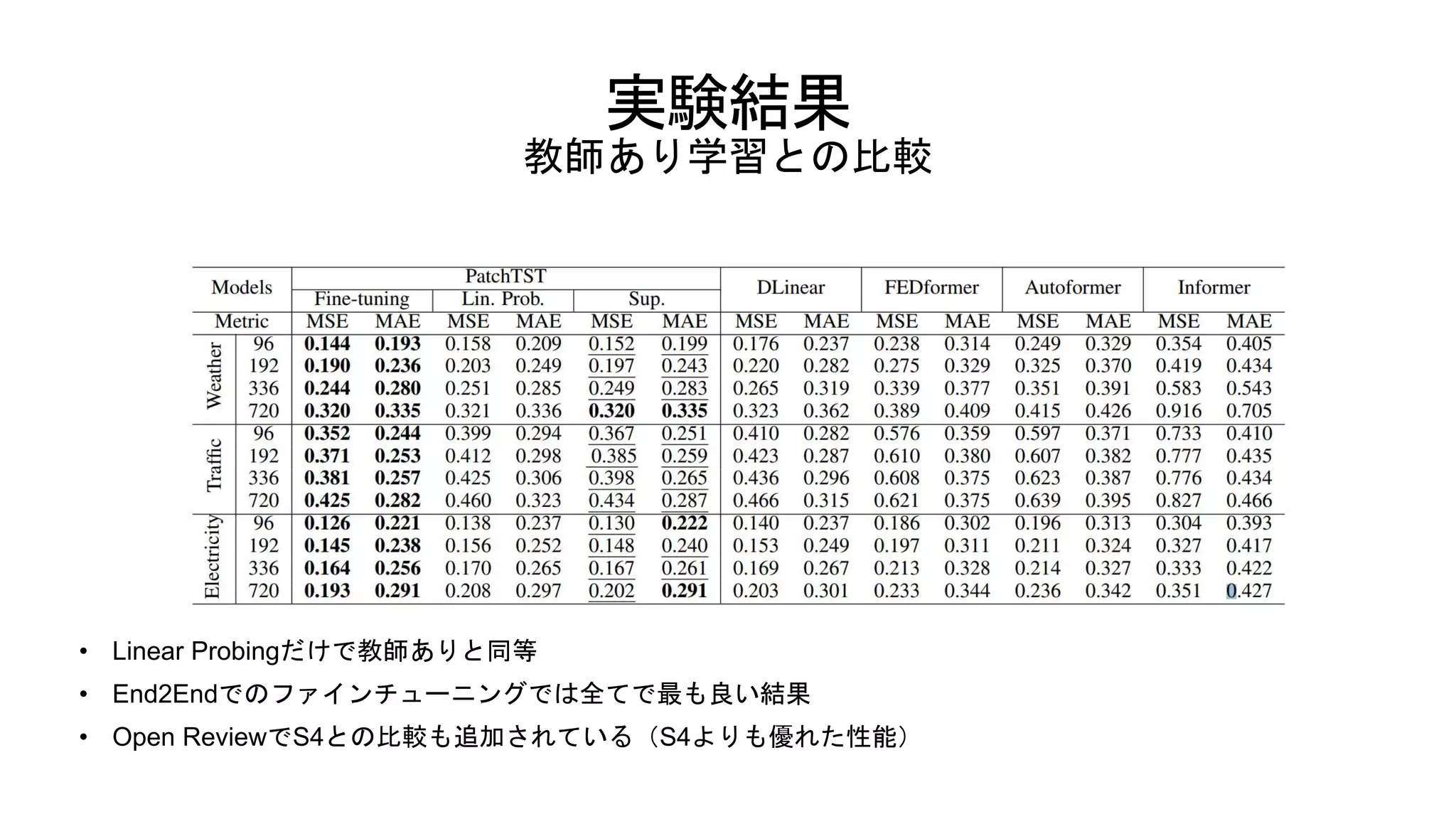
実験結果 教師あり学習との比較 • Linear Probingだけで教師ありと同等 •
End2Endでのファインチューニングでは全てで最も良い結果 • Open ReviewでS4との比較も追加されている(S4よりも優れた性能)
14.
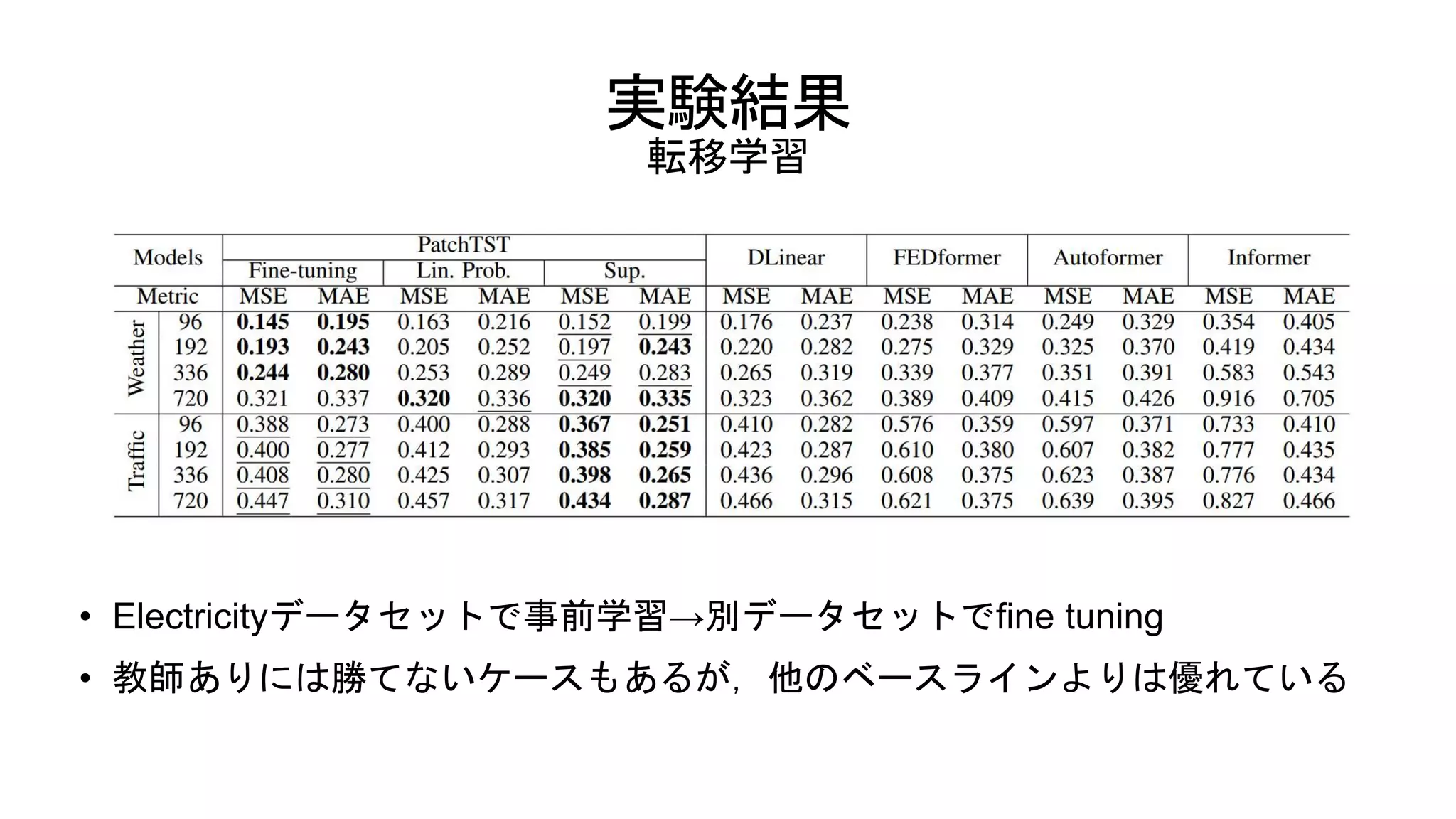
実験結果 転移学習 • Electricityデータセットで事前学習→別データセットでfine tuning •
教師ありには勝てないケースもあるが,他のベースラインよりは優れている
15.
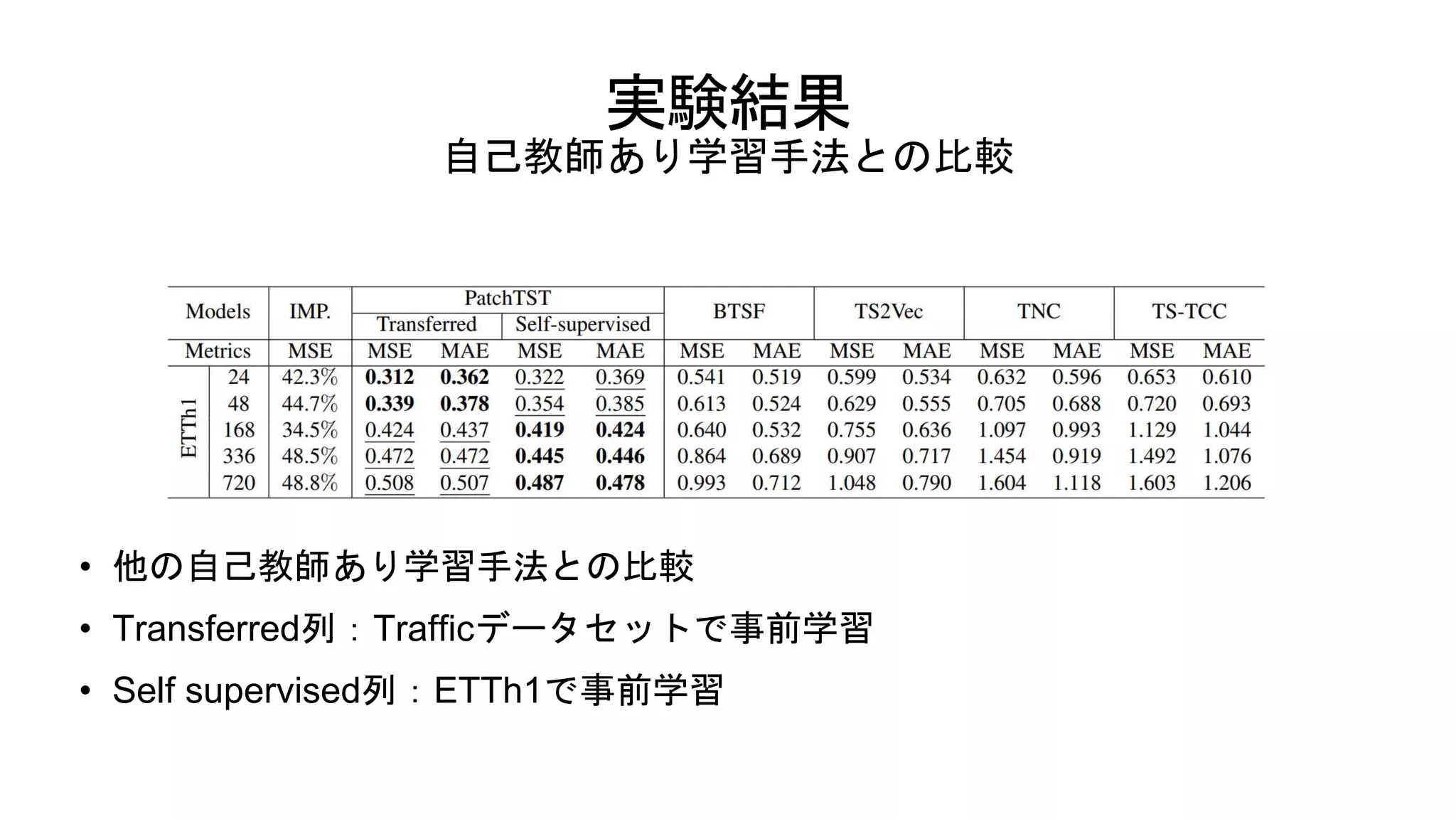
実験結果 自己教師あり学習手法との比較 • 他の自己教師あり学習手法との比較 • Transferred列:Trafficデータセットで事前学習 •
Self supervised列:ETTh1で事前学習
16.
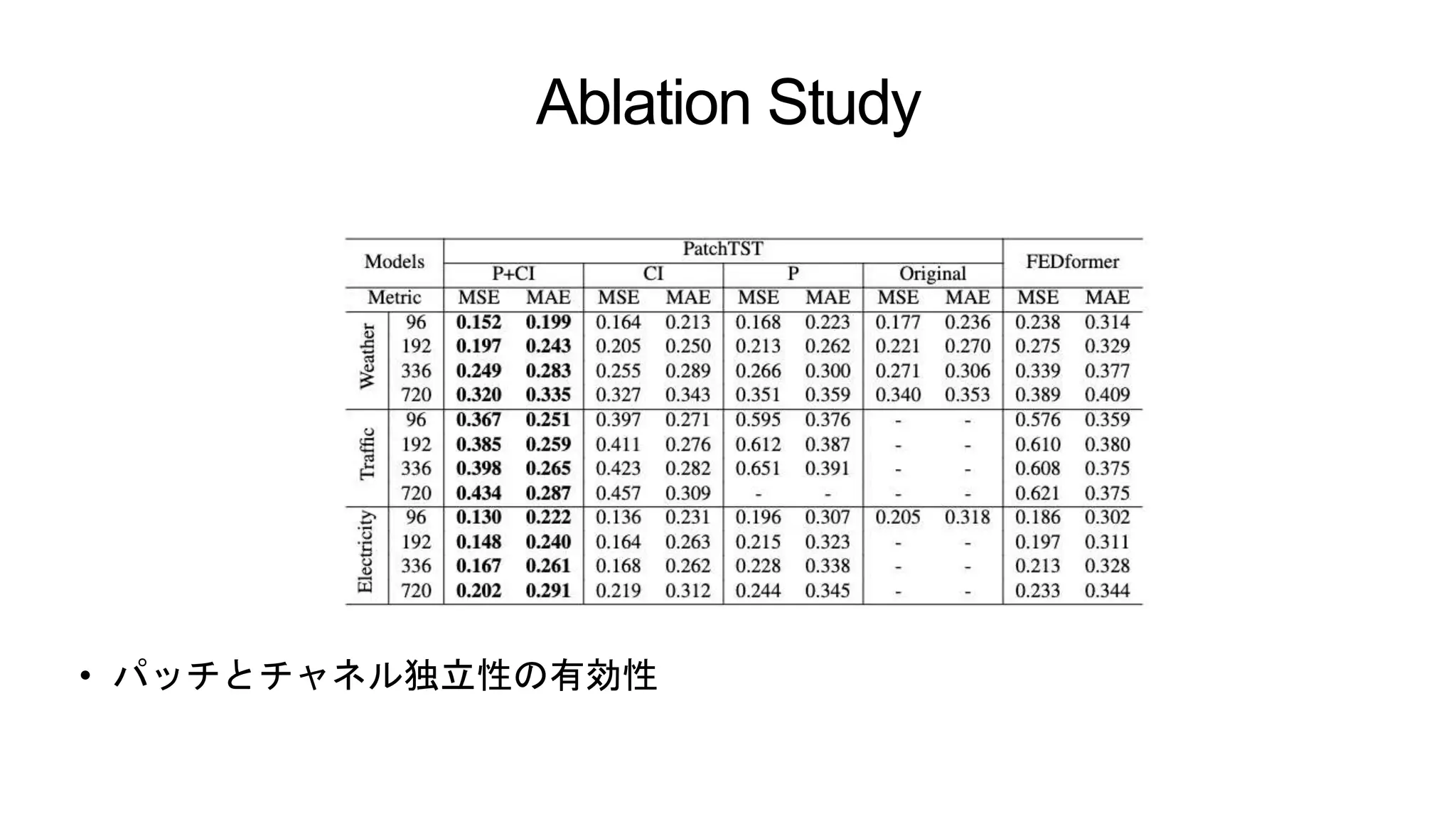
Ablation Study • パッチとチャネル独立性の有効性
17.
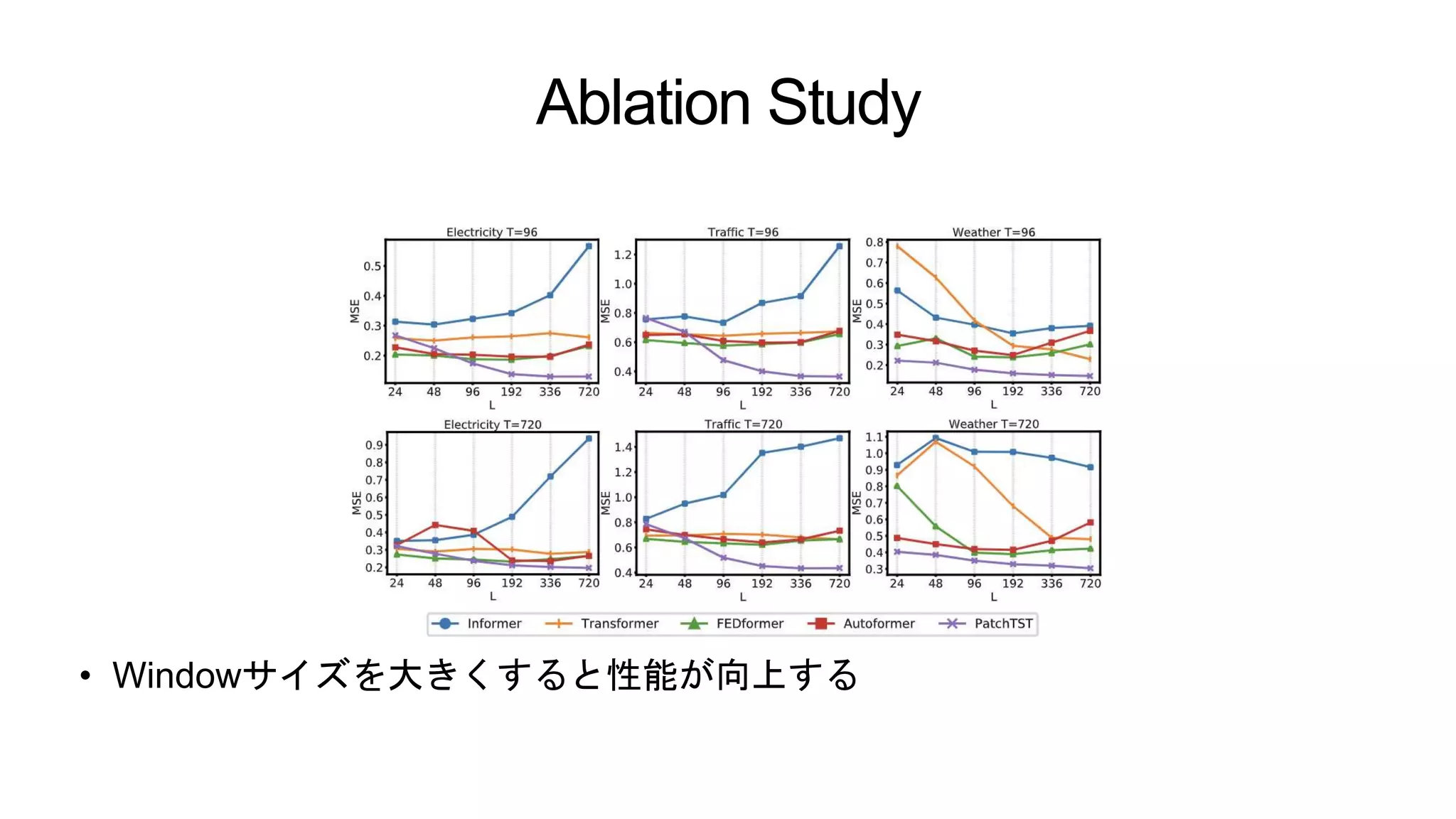
Ablation Study • Windowサイズを大きくすると性能が向上する
18.
まとめ • 多変量時系列予測と自己教師あり学習のための効果的なTransformer(Patch TST) • 時系列のパッチ分割 •
チャネル独立に予測 • 表現学習の時はパッチをマスクして予測 • 長期予測で既存のベースラインより優れた性能 • 表現学習,転移学習の有効性も示した. • シンプル.結果はよい.チャネル独立がデータセットの性質によって本当に 汎用性があるのかが気になる.
19.
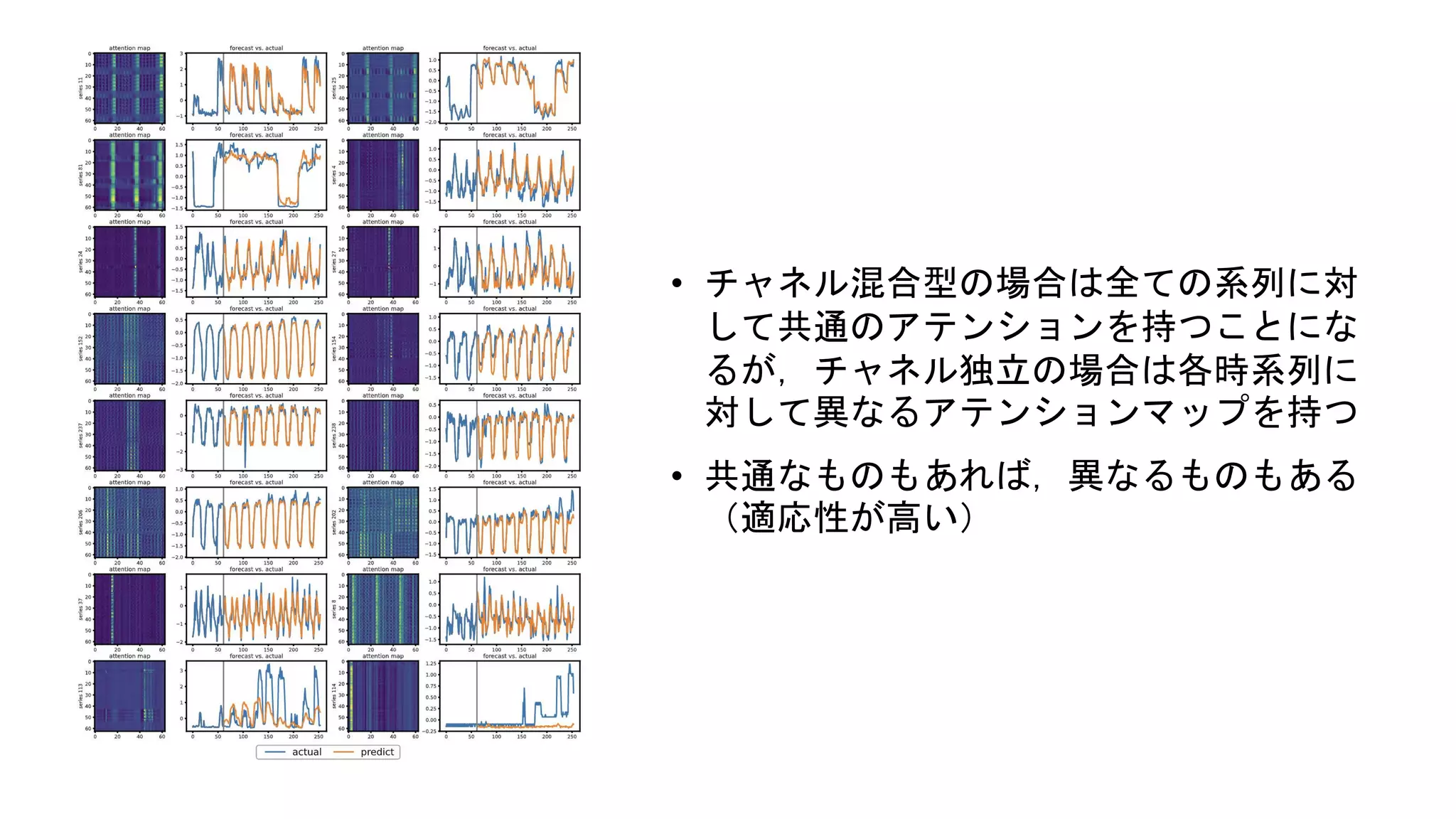
Appendix(Open Reviewの指摘) チャネル独立の有用性 • 適応性 •
チャネル混合型は多くの学習データを必要とする • チャネル独立はオーバーフィットしづらい
20.
• チャネル混合型の場合は全ての系列に対 して共通のアテンションを持つことにな るが,チャネル独立の場合は各時系列に 対して異なるアテンションマップを持つ • 共通なものもあれば,異なるものもある (適応性が高い)
21.
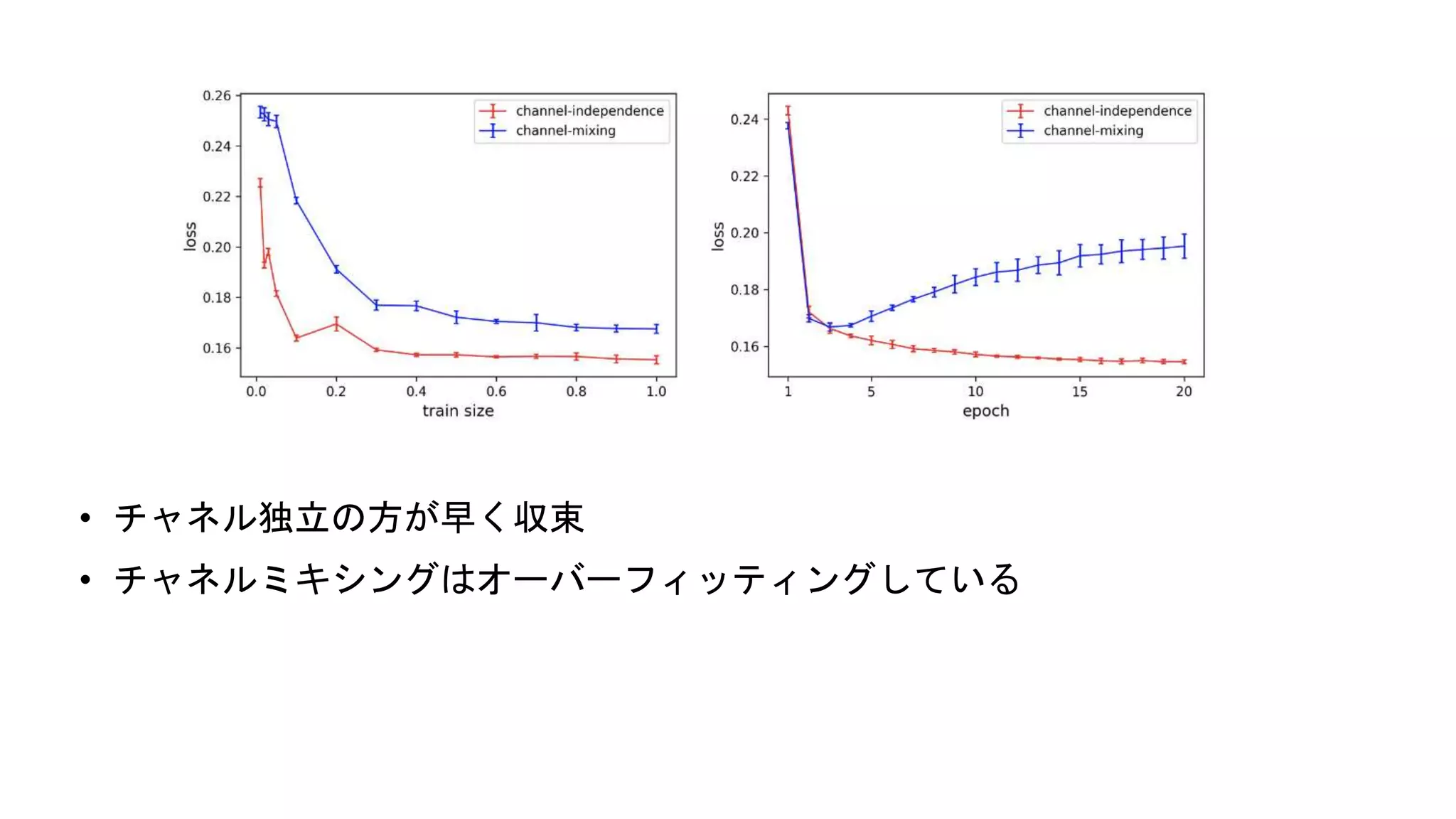
• チャネル独立の方が早く収束 • チャネルミキシングはオーバーフィッティングしている
Download













![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)










![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)

































