Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.Copyright (C) 2018 DeNA Co.,Ltd. All Rights Reserved.
Batch Reinforcement Learning
強化学習アーキテクチャ勉強会
January., 2020
Takuma Oda
Mobility Intelligence Development Dept.
Automotive Business Unit
DeNA Co., Ltd.
2.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
目次
2
背景
なぜ従来のアルゴリズムでは学習できないのか?
アルゴリズム紹介:NAS, BCQ, BEAR-QL
1
2
3
まとめ4
3.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
目次
3
背景
なぜ従来のアルゴリズムでは学習できないのか?
アルゴリズム紹介:NAS, BCQ, BEAR-QL
1
2
3
まとめ4
4.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
Challenges of Real-World Reinforcement Learning
1. Training off-line from the fixed logs of an external behavior policy.
2. Learning on the real system from limited samples.
3. High-dimensional continuous state and action spaces.
4. Safety constraints that should never or at least rarely be violated.
5. Tasks that may be partially observable, alternatively viewed as non-stationary or
stochastic.
6. Reward functions that are unspecified, multi-objective, or risk-sensitive.
7. System operators who desire explainable policies and actions.
8. Inference that must happen in real-time at the control frequency of the system.
9. Large and/or unknown delays in the system actuators, sensors, or rewards.
G. Dulac-Arnold, D. Mankowitz, and T. Hester. Challenges of Real-World Reinforcement Learning.
arXiv e-prints, art. arXiv:1904.12901, Apr 2019.
5.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
Challenges of Real-World Reinforcement Learning
1. すでに収集された固定のログから学習
2. 高次元、連続的な状態、行動空間
3. 安全面における制約
4. 部分観測タスク
5. 報酬設計:複数の目的関数、リスク選好
6. 方策の説明可能性
7. 推論の応答性
8. 状態、行動、報酬取得の大幅な遅れ
6.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
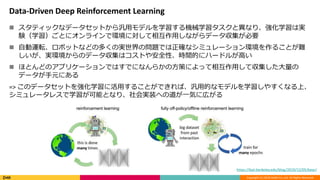
Data-Driven Deep Reinforcement Learning
スタティックなデータセットから汎用モデルを学習する機械学習タスクと異なり、強化学習は実
験(学習)ごとにオンラインで環境に対して相互作用しながらデータ収集が必要
自動運転、ロボットなどの多くの実世界の問題では正確なシミュレーション環境を作ることが難
しいが、実環境からのデータ収集はコストや安全性、時間的にハードルが高い
ほとんどのアプリケーションではすでになんらかの方策によって相互作用して収集した大量の
データが手元にある
=> このデータセットを強化学習に活用することができれば、汎用的なモデルを学習しやすくなる上、
シミュレータレスで学習が可能となり、社会実装への道が一気に広がる
https://bair.berkeley.edu/blog/2019/12/05/bear/
7.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
Batch RL / Fully Off-policy RL
環境との相互作用を一切行わず、固定のデータセット(過去に別の方策を使って収集した報酬を
含むデータ)のみから最適な方策を学習
e.g. 人間の行動、すでにデプロイされたヒューリスティックな方策など
Behavioral cloning / Imitation Learning / Inverse RL
⁃ 報酬データが得られない場合やデータ収集用の方策の質が高ければ有効なアプローチ
⁃ Distributional shiftに対応するため、GAILなど多くのアルゴリズムでは追加のデータ収集が必要
“Off-policy” Deep RL
⁃ Fully off-policyの条件下では上手く学習が進まない
8.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
目次
8
背景
なぜ従来のアルゴリズムでは学習できないのか?
アルゴリズム紹介:NAS, BCQ, BEAR-QL
1
2
3
まとめ4
9.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
“Off-policy” Deep RL
前提知識
⁃ Q-learningのようなoff-policyアルゴリズムは、原則としては、どのような方策でデータ収集を
行っても最適な方策の学習が可能
⁃ 近年のモダンなoff-policy deep RL アルゴリズムはExperience Memoryにデータを貯めておき、
データ収集と学習を交互に行う
⁃ 行動方策は near-on-policy exploratory policy: e.g) e-greedy
10.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
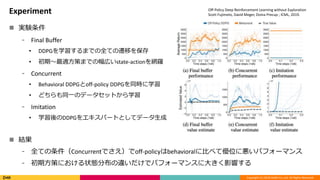
Experiment
実験条件
⁃ Final Buffer
• DDPGを学習するまでの全ての遷移を保存
• 初期〜最適方策までの幅広いstate-actionを網羅
⁃ Concurrent
• Behavioral DDPGとoff-policy DDPGを同時に学習
• どちらも同一のデータセットから学習
⁃ Imitation
• 学習後のDDPGをエキスパートとしてデータ生成
結果
⁃ 全ての条件(Concurrentでさえ)でoff-policyはbehavioralに比べて優位に悪いパフォーマンス
⁃ 初期方策における状態分布の違いだけでパフォーマンスに大きく影響する
Off-Policy Deep Reinforcement Learning without Exploration
Scott Fujimoto, David Meger, Doina Precup ; ICML, 2019.
11.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
Mean squared Bellman error
Bellman equation
Mean squared Bellman error
⁃ 多くのアルゴリズム(DDPG, SAC)では学習する価値関数のロス関数としてMSBEを用いる
⁃ バッチデータのサンプルで計算されたロスはバッチ中の状態行動分布( state-action visitation
distribution)で平均されている
⁃ 本来最小化したいロスは学習中の方策における状態行動分布で平均されたもの
12.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
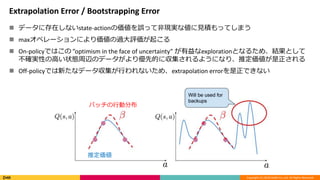
Extrapolation Error / Bootstrapping Error
データに存在しないstate-actionの価値を誤って非現実な値に見積もってしまう
maxオペレーションにより価値の過大評価が起こる
On-policyではこの ”optimism in the face of uncertainty” が有益なexplorationとなるため、結果として
不確実性の高い状態周辺のデータがより優先的に収集されるようになり、推定価値が是正される
Off-policyでは新たなデータ収集が行われないため、extrapolation errorを是正できない
バッチの行動分布
推定価値
13.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
目次
13
背景
なぜ従来のアルゴリズムでは学習できないのか?
アルゴリズム紹介:NAS, BCQ, BEAR-QL
1
2
3
まとめ4
14.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
Reinforcement Learning from Imperfect Demonstrations
Y Gao, J Lin, F Yu, S Levine, T Darrell ; ICML, 2018.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
Normalized Actor-Critic
Soft Q-learningとの違いは勾配のみ
予めReplay bufferとして収集したデモンスト
レーションデータを用意しておく
17.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
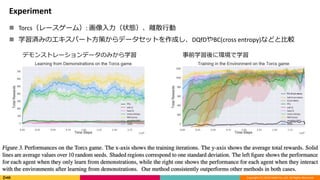
Experiment
Torcs(レースゲーム): 画像入力(状態)、離散行動
学習済みのエキスパート方策からデータセットを作成し、DQfDやBC(cross entropy)などと比較
デモンストレーションデータのみから学習 事前学習後に環境で学習
18.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
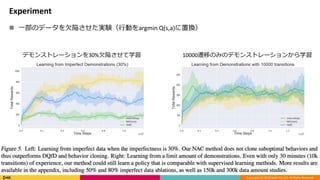
Experiment
一部のデータを欠陥させた実験(行動をargmin Q(s,a)に置換)
デモンストレーションを30%欠陥させて学習 10000遷移のみのデモンストレーションから学習
19.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
Off-Policy Deep Reinforcement Learning without Exploration
Scott Fujimoto, David Meger, Doina Precup ; ICML, 2019.
20.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
Method
方針
⁃ バッチデータの状態行動分布からサンプリングし、その中で最も価値の高い行動を選択
Generative Model
⁃ バッチデータの行動方策を再現する生成モデル(Conditional VAE)を学習する
Perturbation network
⁃ (行動が連続値であるため)生成モデルのサンプリングを抑えるためにサンプリングされた
行動値aから[-Φ, Φ]の範囲で最も行動価値が高い行動値に調整する
⁃ DDPGと同様にQ-networkの出力を最大化するように学習
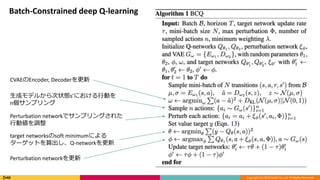
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
Batch-Constrained deep Q-learning
CVAEのEncoder, Decoderを更新
生成モデルから次状態s’における行動を
n個サンプリング
Perturbation networkでサンプリングされた
行動値を調整
target networksのsoft minimumによる
ターゲットを算出し、Q-networkを更新
Perturbation networkを更新
23.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
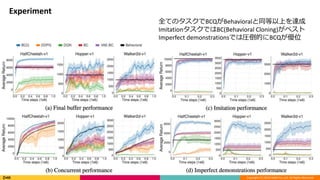
Experiment
全てのタスクでBCQがBehavioralと同等以上を達成
ImitationタスクではBC(Behavioral Cloning)がベスト
Imperfect demonstrationsでは圧倒的にBCQが優位
24.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
Stabilizing Off-Policy Q-Learning via Bootstrapping
Error Reduction
Aviral Kumar, Justin Fu, George Tucker, and Sergey Levine; NeurIPS, 2019.
25.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
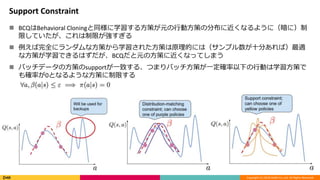
Support Constraint
BCQはBehavioral Cloningと同様に学習する方策が元の行動方策の分布に近くなるように(暗に)制
限していたが、これは制限が強すぎる
例えば完全にランダムな方策から学習された方策は原理的には(サンプル数が十分あれば)最適
な方策が学習できるはずだが、BCQだと元の方策に近くなってしまう
バッチデータの方策のsupportが一致する、つまりバッチ方策が一定確率以下の行動は学習方策で
も確率が0となるような方策に制限する
26.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
Maximum Mean Discrepancy (MMD)
どのように学習方策に対してSupport constraintを適応できるか
サンプルした行動間のMMD距離をsupport constraint充足の指標に使う
少ないサンプル数(<10)で計算したMMDにより二つの分布のサポートの違いを判別可能であるこ
とを実験的に確認(サンプル数が多すぎると分布一致の制約となってしまう)
MMDがε以下という制約のもと、Dual gradient descentで方策のパラメータを更新
27.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
BEAR Q-learning
5. BCQを拡張して、K個のQ-networkのsot minimumをターゲットとして使う
8. MMD制約のもとDual gradient descentで方策のパラメータを更新
28.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
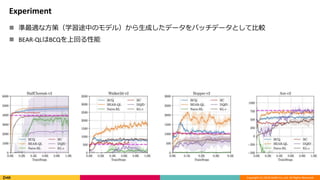
Experiment
準最適な方策(学習途中のモデル)から生成したデータをバッチデータとして比較
BEAR-QLはBCQを上回る性能
29.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
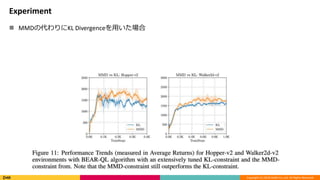
Experiment
MMDの代わりにKL Divergenceを用いた場合
30.
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
目次
30
背景
なぜ従来のアルゴリズムでは学習できないのか?
アルゴリズム紹介:NAS, BCQ, BEAR-QL
1
2
3
まとめ4
Copyright (C) 2018DeNA Co.,Ltd. All Rights Reserved.
参考文献
G. Dulac-Arnold, D. Mankowitz, and T. Hester. Challenges of Real-World Reinforcement Learning. ICML, 2019.
Yang Gao, Huazhe Xu, Ji Lin, Fisher Yu, Sergey Levine, and Trevor Darrell. Reinforcement learning from imperfect
demonstrations. ICML, 2018.
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. ICML,
2019.
Aviral Kumar, Justin Fu, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error
reduction. NeurIPS, 2019.















![Copyright (C) 2018 DeNA Co.,Ltd. All Rights Reserved.
Method
方針
⁃ バッチデータの状態行動分布からサンプリングし、その中で最も価値の高い行動を選択
Generative Model
⁃ バッチデータの行動方策を再現する生成モデル(Conditional VAE)を学習する
Perturbation network
⁃ (行動が連続値であるため)生成モデルのサンプリングを抑えるためにサンプリングされた
行動値aから[-Φ, Φ]の範囲で最も行動価値が高い行動値に調整する
⁃ DDPGと同様にQ-networkの出力を最大化するように学習](https://image.slidesharecdn.com/20200107rlarchbachrl-200107101533/85/Batch-Reinforcement-Learning-20-320.jpg)









![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)




















