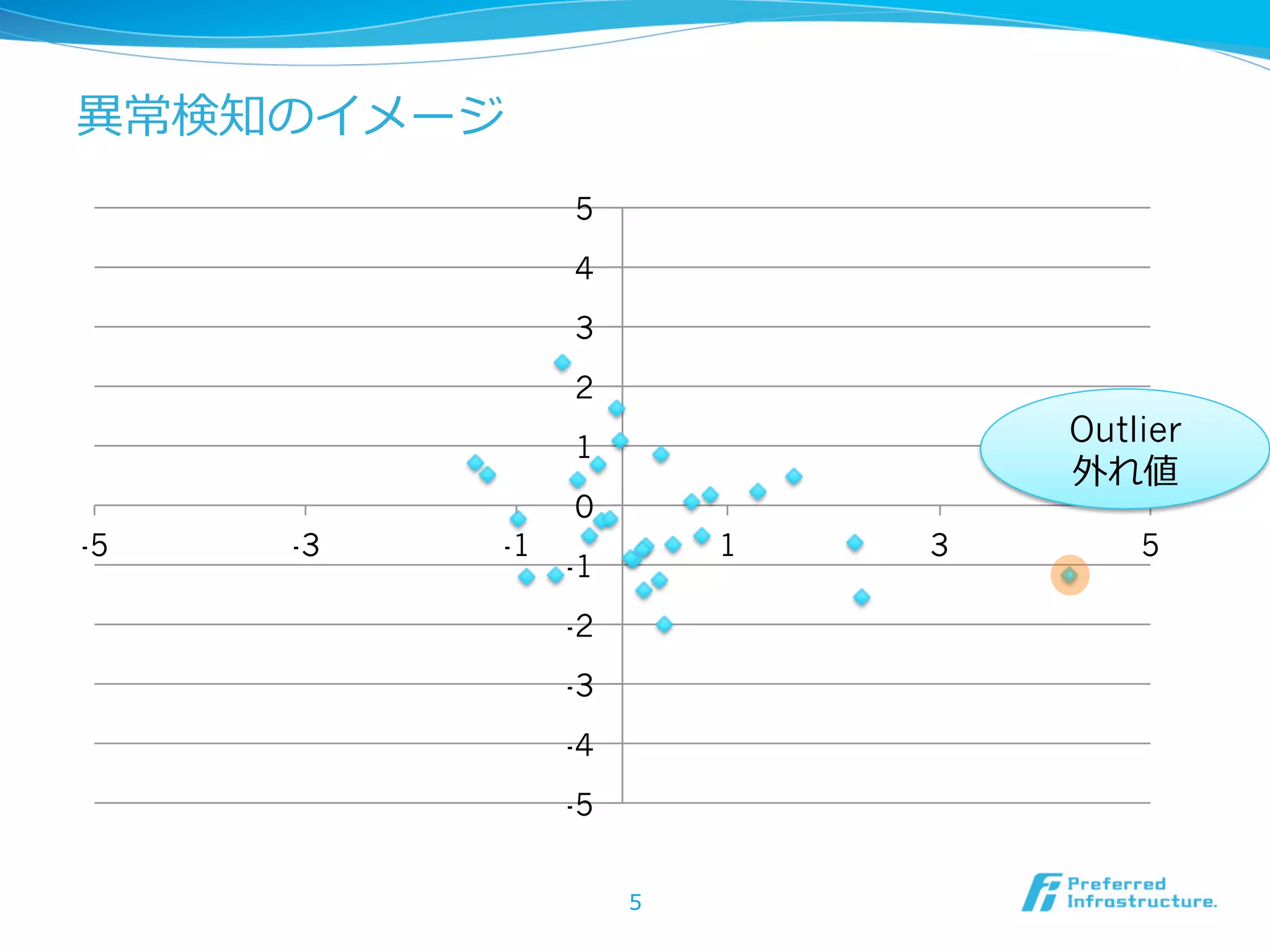
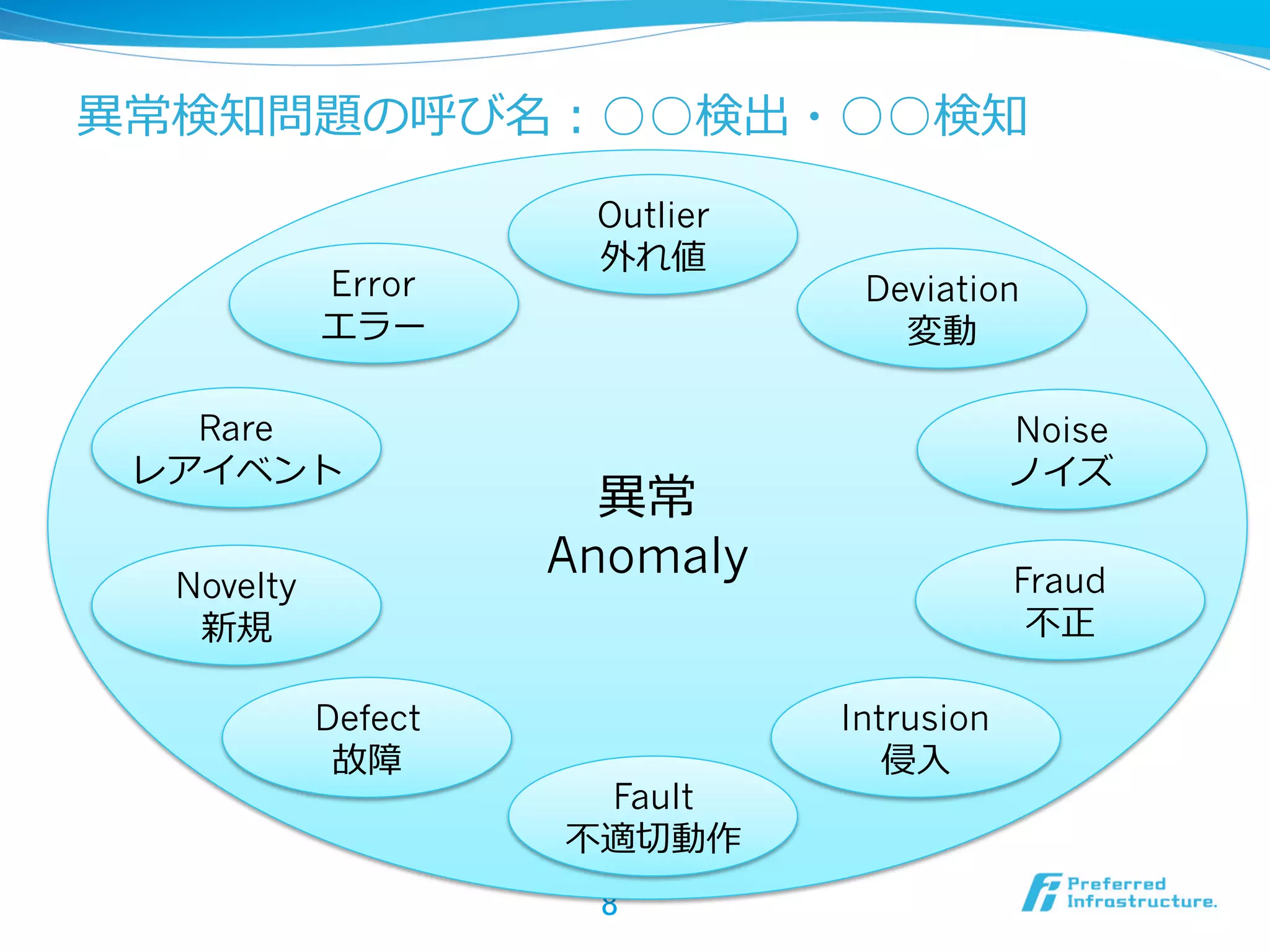
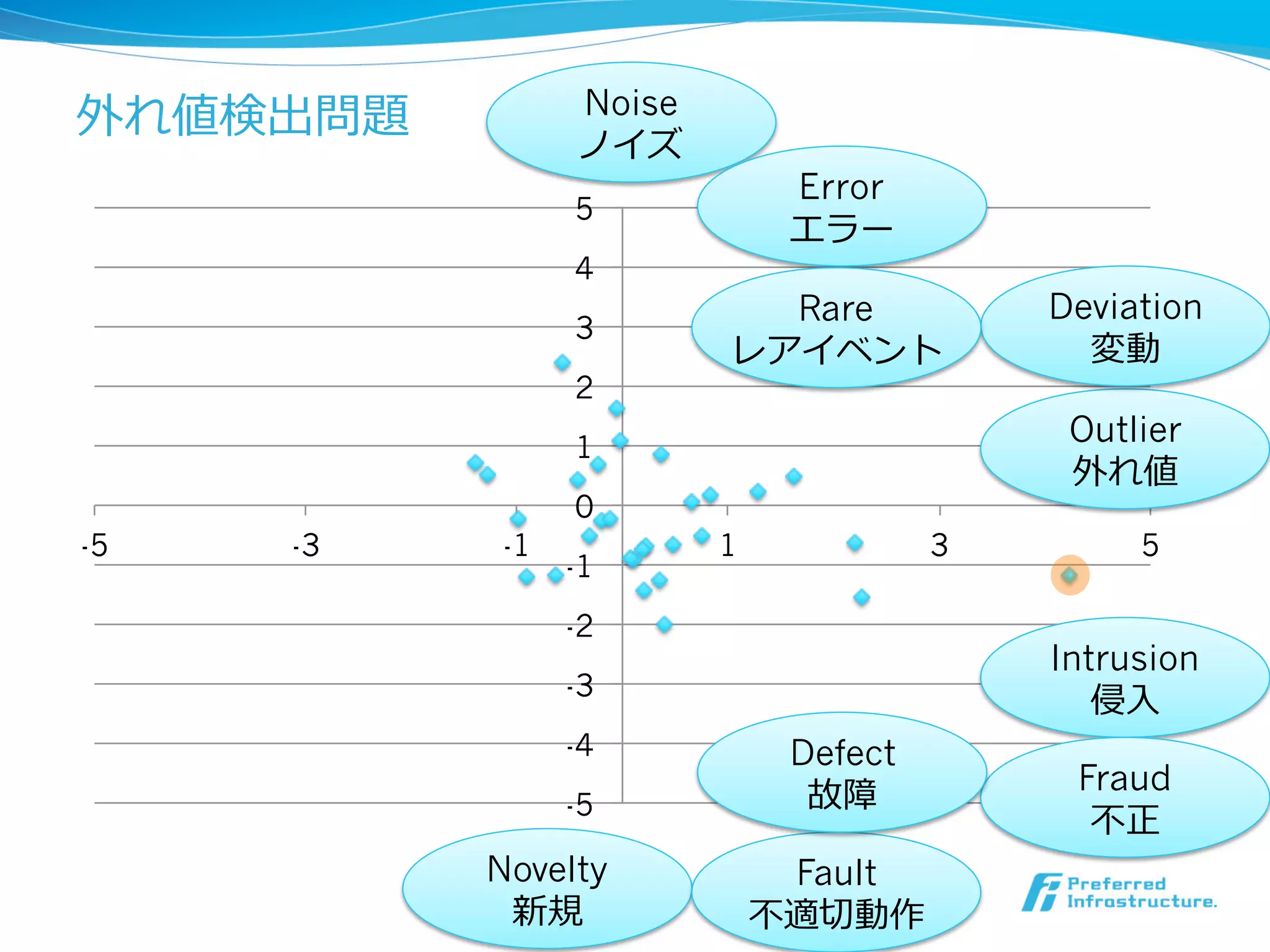
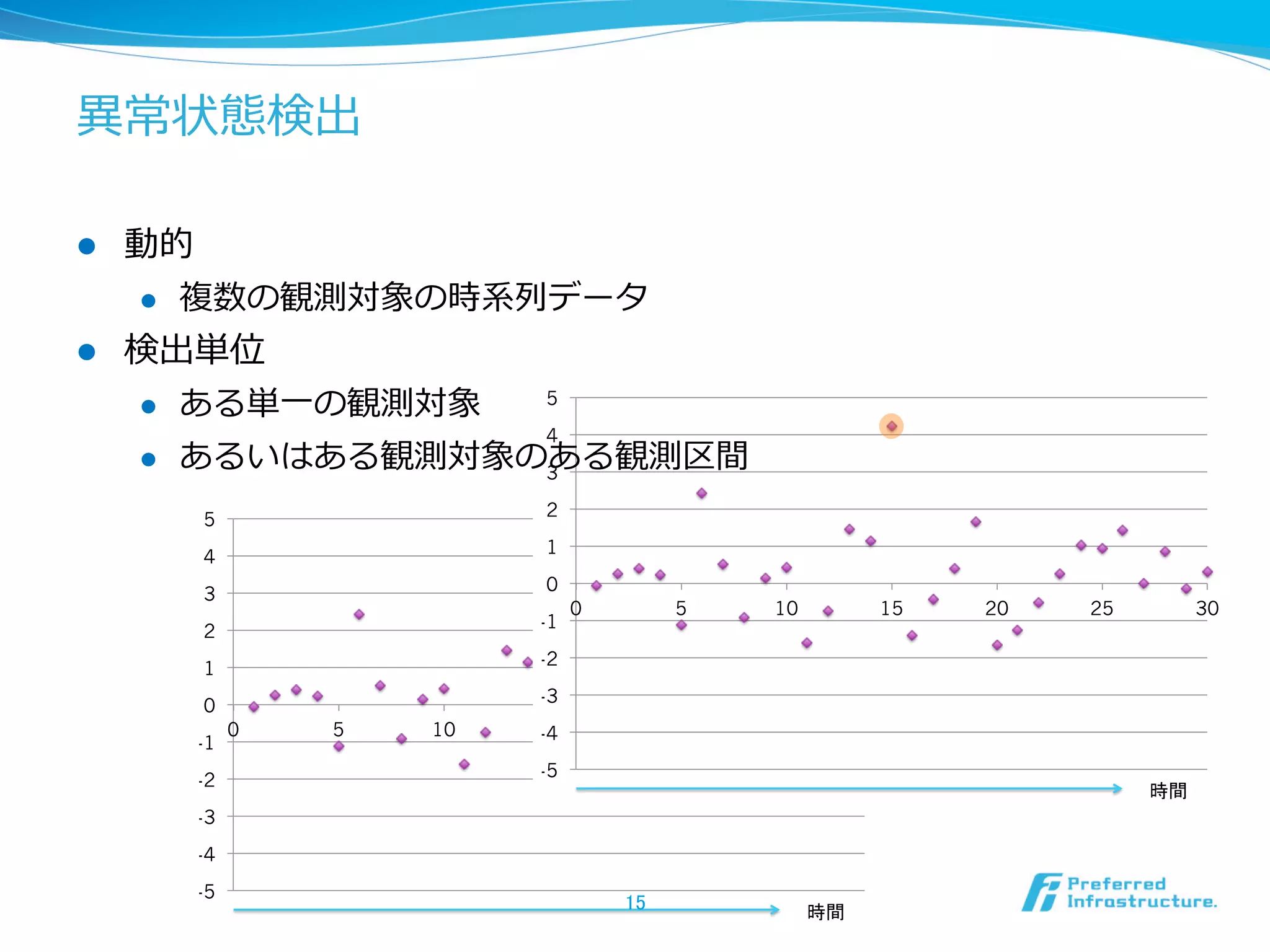
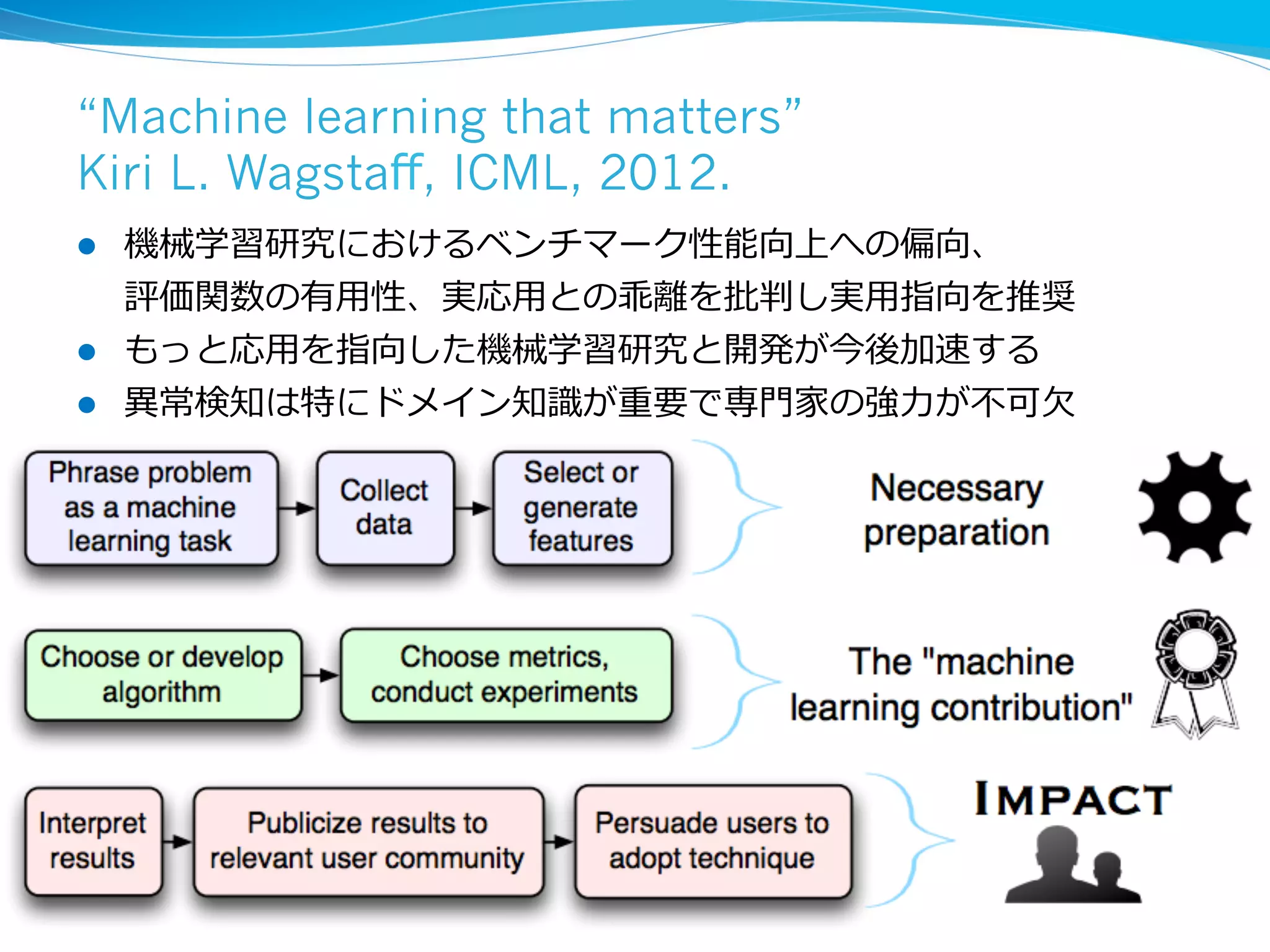
異異常・外れ値の定義:統⼀一的⾒見見解は無い
l Grubbs,
l
1969
“An outlyingobservation, or outlier, is one that appears to
deviate markedly from other members of the sample in
which it occurs.”
l Hawkins,
l
“An observation that deviates so much from other
observations as to arouse suspicion that is was generated by
a different mechanism.”
l Barnett
l
1980
& Lewis, 1994
“An observation (or subset of observations) which appears
to be inconsistent with the remainder of that set of data.”
10







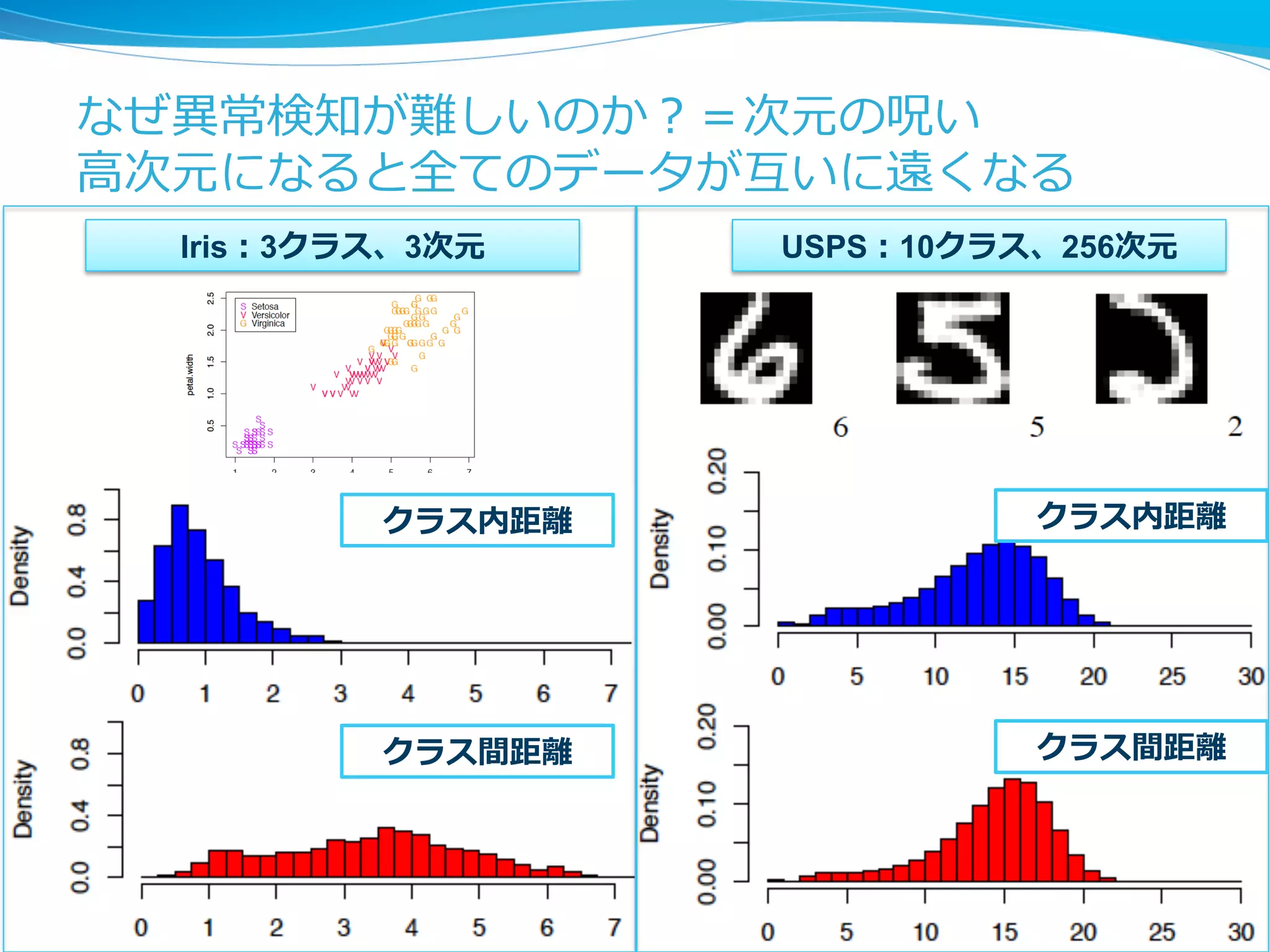
![異異常検知のアプローチ(1/3):統計ベース
l
基本⽅方針
l
データ⺟母集団の形状や確率率率分布に仮定を置く
l
データをモデルにフィッティング(パラメータを合わせる)
l
l
メリット
l
l
例例:正規分布なら平均と標準偏差を合わせる
データが仮定したモデルに従っていれば⾮非常に⾼高精度度を達成
デメリット
l
l
l
⼀一般にデータは綺麗麗な分布に従っていることは少ない
⾼高次元になると単純な分布であってもフィッティングが困難
代表的⼿手法
l
Minimum Volume Ellipsoid estimation [Rousseeuw, 1985]
l
Minimum Covariance Determinant [Rousseeuw, 1999]
l
多次元正規分布を仮定してマハラノビス距離離を使う
18](https://image.slidesharecdn.com/jubatuscasual2anomaly-131213225945-phpapp02/75/Jubatus-Casual-Talks-2-18-2048.jpg)
![異異常検知のアプローチ(2/3):ルールベース
l
基本⽅方針
l
l
l
既知の異異常サンプルを集める
それらを表す汎⽤用的なルールを決める(あるいは学習する)
メリット
l
l
l
専⾨門家が持つドメイン知識識をそのまま組み込むことができる
既知の異異常に良良く合致するルール集合を得ることができる
デメリット
l
l
l
背後のルールが複雑化しすぎると⼈人間では表現できない
未知の異異常に合致するルールを作ることは困難
代表的⼿手法
l
RIPPER [Cohen, Fast effective rule induction, Machine
Learning, 1995]
19](https://image.slidesharecdn.com/jubatuscasual2anomaly-131213225945-phpapp02/75/Jubatus-Casual-Talks-2-19-2048.jpg)

![One-class SVM [Schoelkopf et al., 1999]
l
l
l
Support Vector Machineの改変版
オリジナルデータ空間のサンプルを
カーネル関数で特徵空間に射影
元のSVMの⽬目的
l
l
2クラスを分類する境界⾯面を探す
OC-SVMの⽬目的
l
(1-ρ)割のサンプルを最⼩小の体積に
押し込める境界⾯面を探す
l
メリット
l
適切切なカーネル関数を設計する
ことで様々なデータに対応
Manevitz et al, One-Class SVMs for Document Classification, 2001
23](https://image.slidesharecdn.com/jubatuscasual2anomaly-131213225945-phpapp02/75/Jubatus-Casual-Talks-2-23-2048.jpg)
![LOF: Identifying Density-Based Local Outliers
[Breunig, SIGMOD2000]
l
LOF法は周辺のデータとの局所的な関係から異異常度度を計算
l
l
密度度ベースと書いてあるが実際には距離離計算のみから算出
⼀一般の距離離ベースの異異常値計算⼿手法とは違い、密集度度を考慮する
l 通常の異異常値≒周りのデータへの距離離
l LOF値≒周りのデータへの距離離×周りのデータの密集度度
特徴ベクトル
X1 (LOF値特大)
X1
分散したデータ集合
X2 (LOF値大)
X2
密集したデータ集合
X3
X3 (LOF値小)
24](https://image.slidesharecdn.com/jubatuscasual2anomaly-131213225945-phpapp02/75/Jubatus-Casual-Talks-2-24-2048.jpg)
![l
既存⼿手法:外れ値検出へ帰着
l
l
normal
多次元センサーデータからの
異異常状態検出⼿手法
滑滑⾛走窓⽅方式による移動平均
最新⼿手法: 近傍保存原理理による相関異異常検知
[井⼿手, 2009]
l
変数間の相関関係をグラフで表し
faulty
正常時と⽐比較
25](https://image.slidesharecdn.com/jubatuscasual2anomaly-131213225945-phpapp02/75/Jubatus-Casual-Talks-2-25-2048.jpg)
![最新⼿手法:サンプリングによる超⾼高速異異常検知
[Sugiyama&Borgwardt, NIPS2013]
l
K=4
前処理理
l
元データから少数K (5〜~100個)
をあらかじめサンプリング(紫)
l
異異常値計算
l
l
l
各サンプリング点への距離離計算
最⼩小値を異異常度度とみなす(半径)
メリット
l
サンプリングはたったの⼀一回
l
K回の距離離計算のみで超⾼高速
l
任意の距離離尺度度を利利⽤用可能
l
だいたいK=20くらいで最⾼高性能
l
l
正常点
うまくいく理理論論的な説明付き
ご本⼈人によるコード(CとR)
l
26
https://github.com/mahito-sugiyama/sampling-outlier-detection/
異異常点](https://image.slidesharecdn.com/jubatuscasual2anomaly-131213225945-phpapp02/75/Jubatus-Casual-Talks-2-26-2048.jpg)
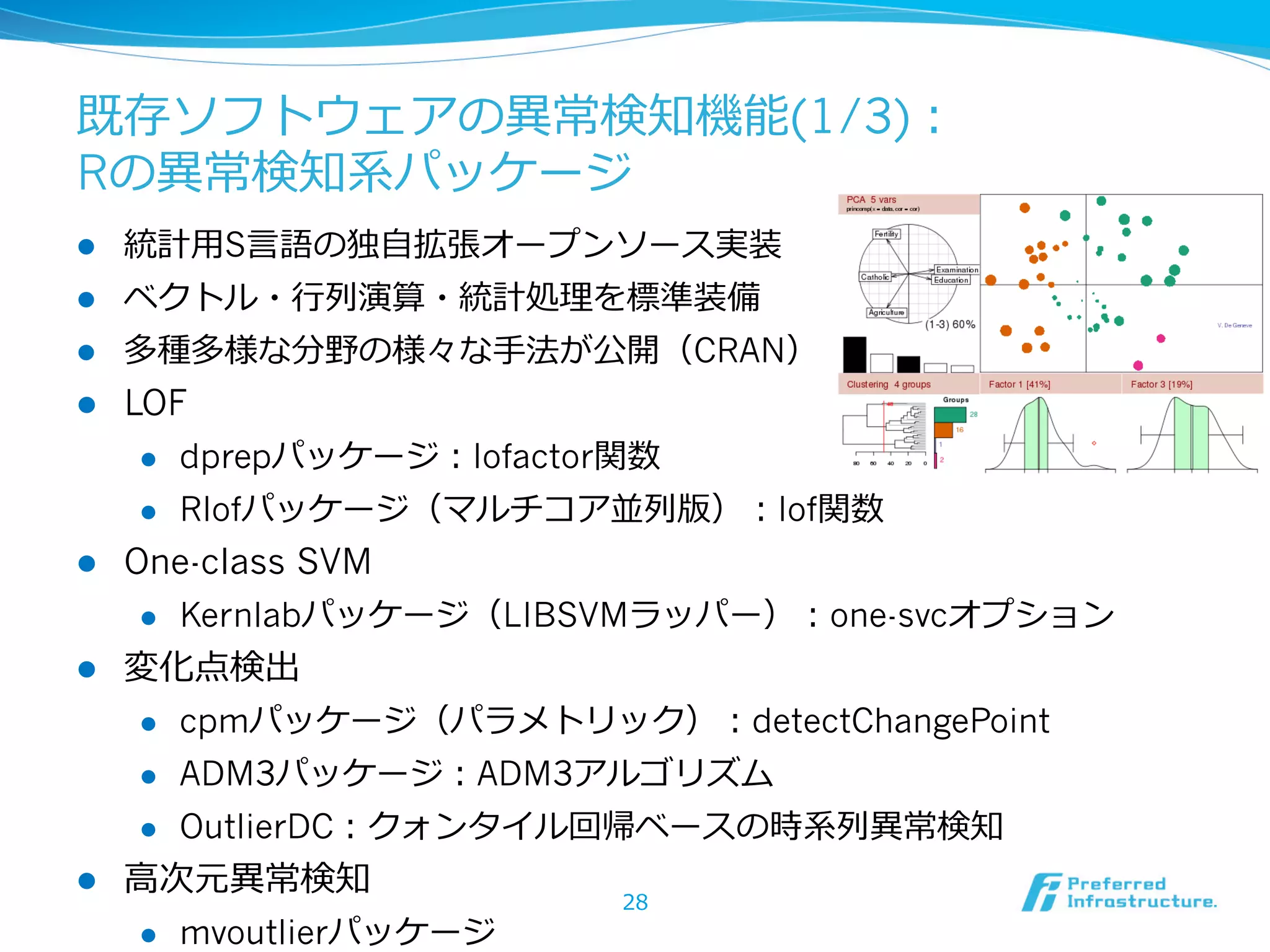














![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)





















































