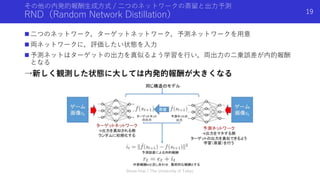
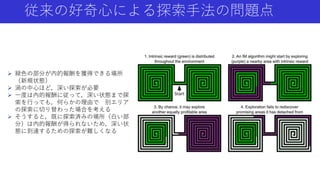
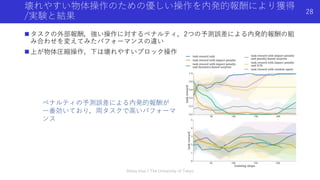
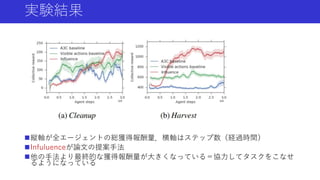
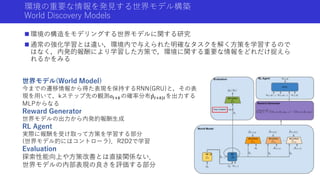
本資料は2019年11月15日~11月16日に行われた統計・機械学習若手シンボジウムで今井が行った招待公演「強化学習エージェントの内発的動機付けによる探索とその応用」で使用した資料を,自主公開版として一部修正したものです. いわゆる内発的報酬(Intrinsic Reward)を用いた強化学習の手法について,近年(〜2019年)の手法や内容をまとめたものになります.































![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] マルチエージェント強化学習と心の理論](https://cdn.slidesharecdn.com/ss_thumbnails/0917imai-211210044729-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Model-Based Reinforcement Learning via Meta-Policy Optimization](https://cdn.slidesharecdn.com/ss_thumbnails/model-basedreinforcementlearningviameta-policyoptimization-190705000247-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning to Adapt: Meta-Learning for Model-Based Control](https://cdn.slidesharecdn.com/ss_thumbnails/20180511dl-180511004107-thumbnail.jpg?width=640&height=640&fit=bounds)
