Downloaded 19 times
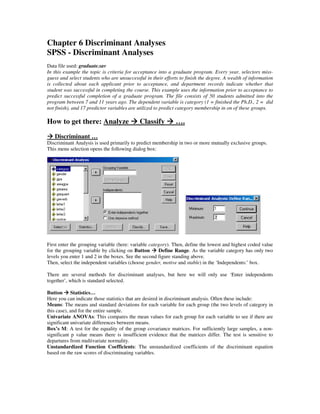
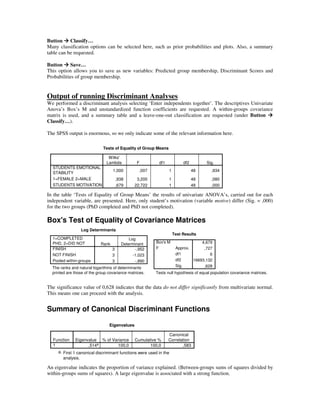

This summary analyzes a document describing the use of discriminant analysis in SPSS to predict whether graduate students will successfully complete their PhD programs based on information collected before acceptance. It identifies key outputs of the discriminant analysis including tests showing one predictor variable significantly differs between groups, coefficients of the discriminant function, group centroids, and a classification results table showing around 80% of students were correctly classified.

























![37109163 progress-of-life-insurance-in-india-since-2000[1]](https://cdn.slidesharecdn.com/ss_thumbnails/37109163-progress-of-life-insurance-in-india-since-20001-121105111515-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





























































