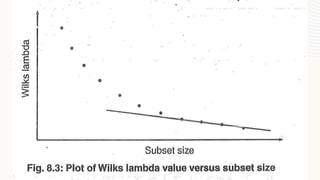
Discriminant analysis is a statistical technique used to predict group memberships for categorical dependent variables based on interval independent variables. It is distinguished from binary logistic regression by its ability to handle more than two categories and relies on several assumptions, including multivariate normality and homogeneous variances. The model provides insights into variable contributions and classification accuracy while requiring careful selection of predictors to avoid multicollinearity.






![BOX’s M-Test
𝑯𝑶: 𝜮𝟏 = 𝜮𝟐=….= 𝜮𝑳
𝑯𝟏: 𝜮𝒍 ≠ 𝜮𝒎 for at least one pair of (l,m) is statistically different [ 𝒍 ≠ m]
Statistic D=(1-u)M
M= -2ln[ 𝒊=𝑙
𝑳
(
|𝑺𝒍|
|𝑺𝒑𝒐𝒐𝒍𝒆𝒅|
)
(𝒏𝒍−𝟏)
𝟐 ] (Log we used here for our convenience.)
u=[ 𝑙
1
(𝑛𝑙−1)
−
1
𝑙(𝑛𝑙−1)
] [
2𝑝2+3𝑝−1
6(𝑝+1)(𝐿−1)
]
Reject 𝑯𝒐 when D > 𝝌𝟐
𝜶,𝒗
D.F.= v
v =
1
2
p(p + 1)(L − 1)](https://image.slidesharecdn.com/discriminantanalysis-230506091321-40ca7ac5/85/Discriminant-analysis-pptx-6-320.jpg)







![Let 𝑿𝒍 𝒏𝒍 × 𝒑 be the 𝑙-th data matrix [𝒍 = 𝟏, 𝟐, … , 𝒌] from 𝑵𝒑 𝝁𝒍, 𝜮𝒍 .
Assume that 𝜮𝟏 = 𝜮𝟐 = ⋯ = 𝜮𝒌. If 𝑿𝒍 = 𝑿𝟏𝒍𝑿𝟐𝒍 ⋯ 𝑿𝒑𝒍
′
be the data vector
and 𝒇𝒍 𝑿𝒍 be the density function of 𝑿𝒍, then the objective of the
discriminant analysis is to identify the 𝒇𝒍 𝑿𝒍 of an object on the basis of the
values of 𝒑 variables of 𝑿. The identification is done in such a way that the
error of identification is minimum.
Let us explain the technique by an example. Consider that a doctor needs to
examine many patients to diagnose their diseases. Different patients are
suffering from different diseases and the symptoms of the diseases are also
different. The symptoms help the doctor to diagnose the disease correctly
which in turn makes the patient cure. The treatment of the patient
becomes easier if the diagnosis of the disease is made correctly.
Justification of Discriminant Analysis and Selection of
Variables](https://image.slidesharecdn.com/discriminantanalysis-230506091321-40ca7ac5/85/Discriminant-analysis-pptx-15-320.jpg)
![𝑫 = 𝜷𝟎 + 𝜷𝟏𝒙𝟏 + 𝜷𝟐𝒙𝟐 + ⋯ + 𝜷𝒑𝒙𝒑
Let us consider that the total sample objects of size 𝒏 are to be divided into two
groups of sizes 𝒏𝟏 and 𝒏𝟐 such that 𝒏 = 𝒏𝟏 + 𝒏𝟐. Let us assume that 𝒍-th [𝒍 = 𝟏, 𝟐]
group of sample observations have the p.d.f. 𝒇𝒍(𝒙), where 𝒍-th population has mean
vector 𝝁𝒍. Now, if it is observed that the null hypothesis 𝑯𝟎: 𝝁𝟏 = 𝝁𝟐 is rejected, the
discriminant analysis can be performed.
The rejection of 𝑯𝟎: 𝝁𝟏 = 𝝁𝟐 = ⋯ = 𝝁𝒌 does not mean that the means of 𝒋-th variable [𝒋 =
𝟏, 𝟐, … , 𝒑] for all 𝒌 samples are heterogeneous. If some of the means, assume that the means of
𝒑𝟏 < 𝒑 variables, are homogeneous, the above hypothesis may be rejected and decision will be
made in favor of discriminant analysis. However, the homogeneity in the variables in 𝒌 groups
has nothing to contribute to discriminate among groups.
Thus, even if the hypothesis of equality of group means is rejected, it needs a decision regarding
the inclusion of variables for discriminant analysis. Let 𝝁𝒍𝒋(𝒍 = 𝟏, 𝟐, … , 𝒌; 𝒋 = 𝟏, 𝟐, … , 𝒑) be the
mean of 𝑗-th variable of 𝑙-th sample. The 𝑗-th variable should be included in the analysis if the
null hypothesis
𝑯𝟎: 𝝁𝟏𝒋 = 𝝁𝟐𝒋 = ⋯ = 𝝁𝒌𝒋](https://image.slidesharecdn.com/discriminantanalysis-230506091321-40ca7ac5/85/Discriminant-analysis-pptx-16-320.jpg)