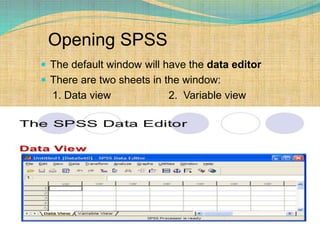
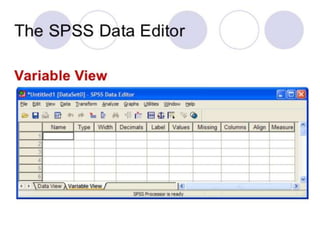
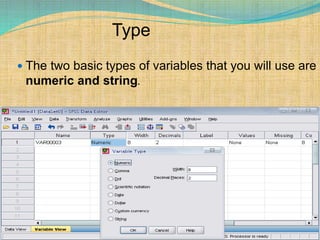
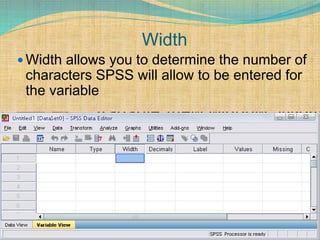
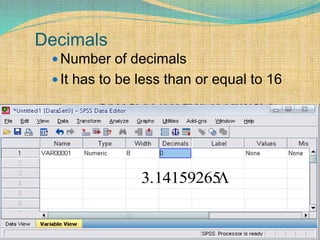
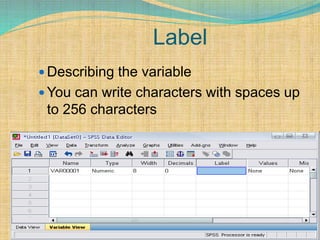
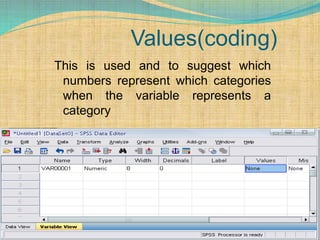
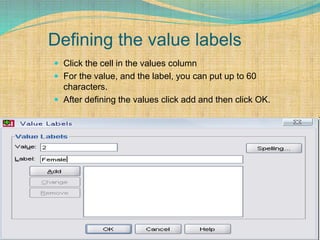
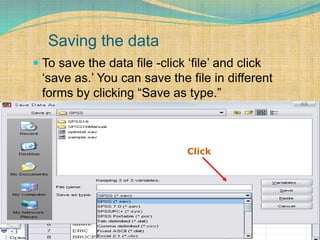
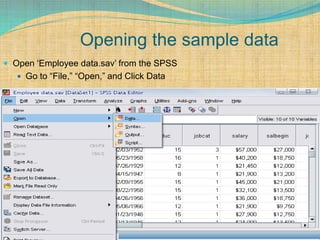
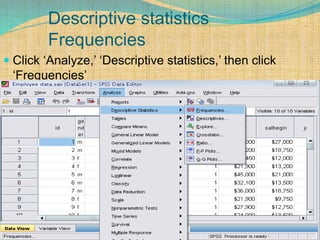
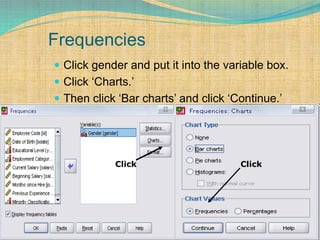
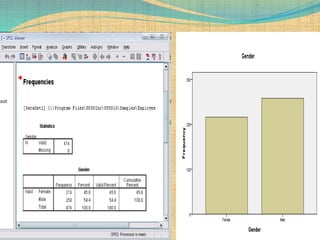
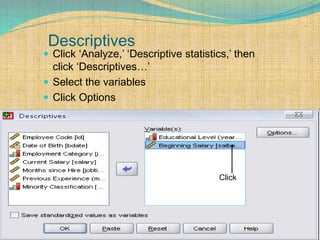
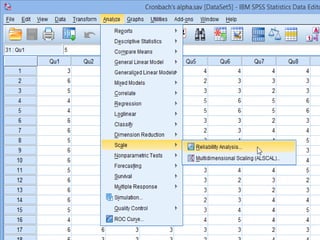
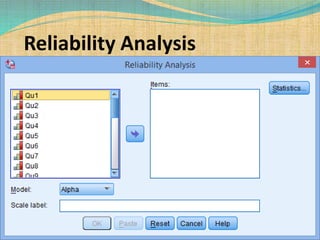
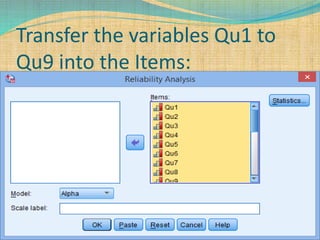
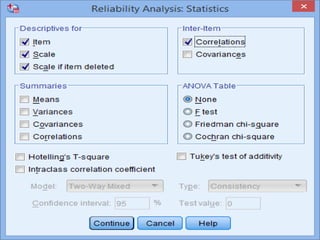
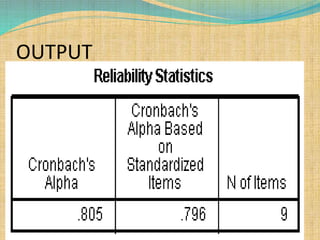
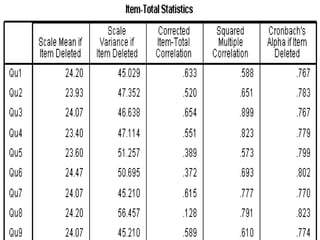
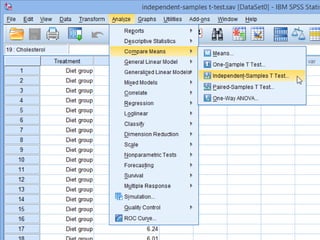
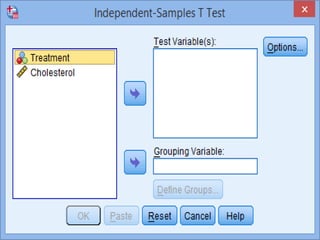
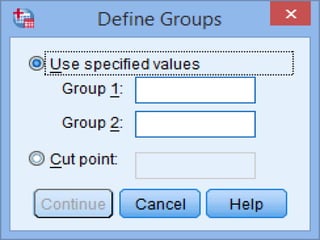
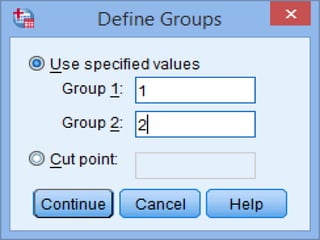
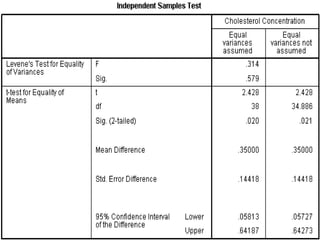
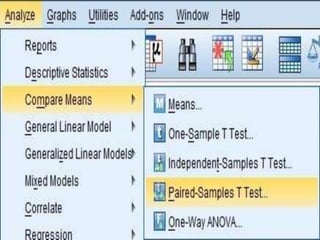
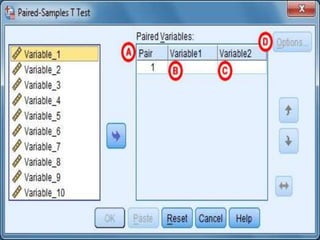
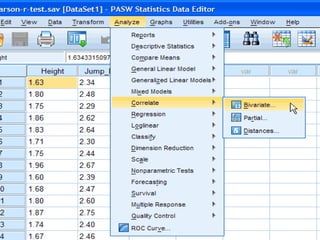
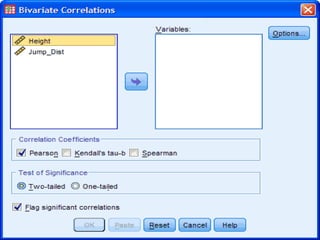
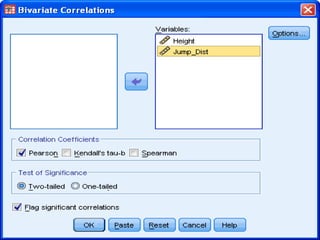
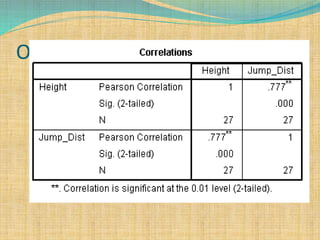
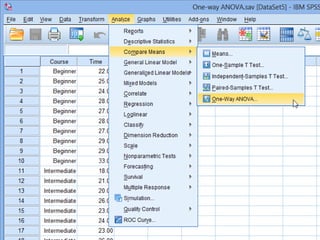
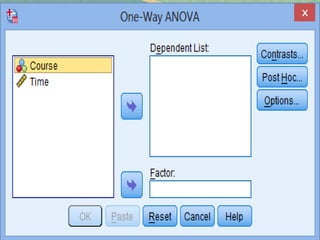
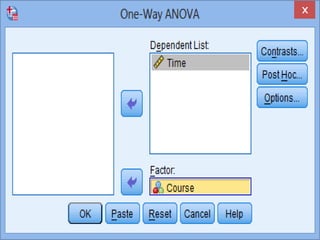
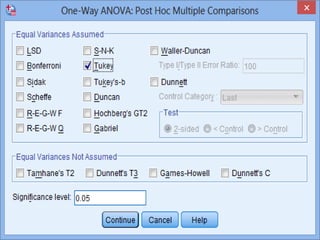
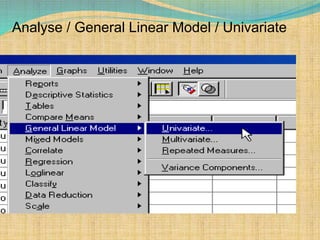
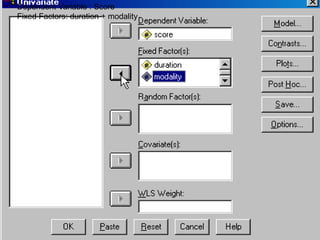
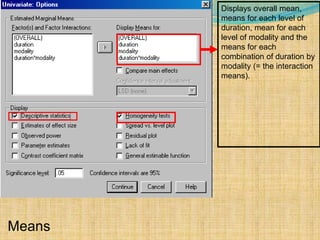
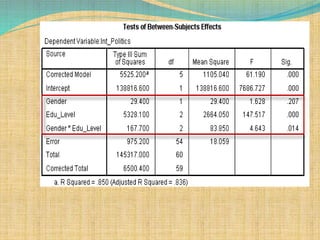
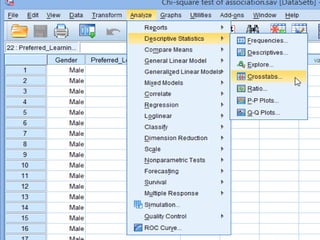
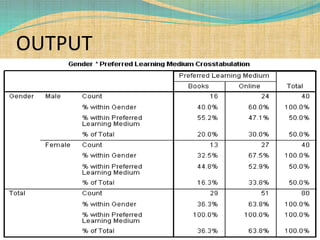
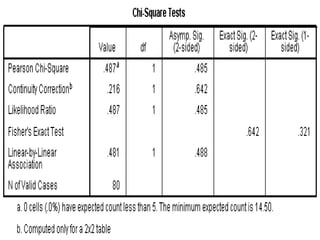
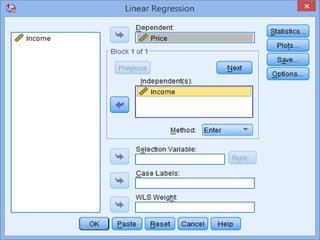
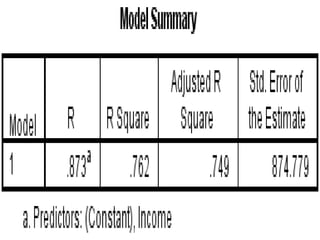
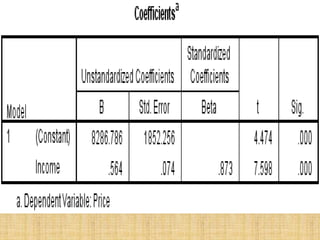
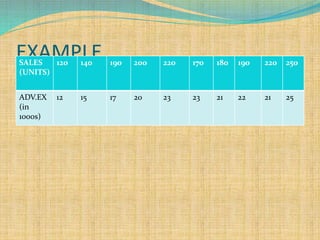
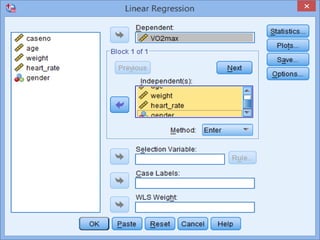
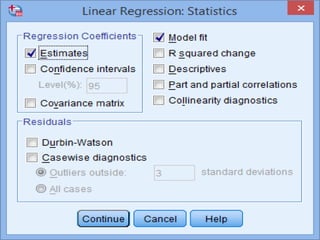
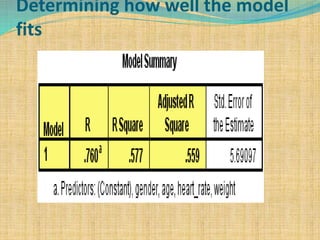
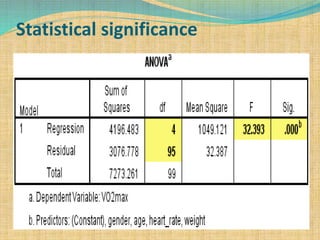
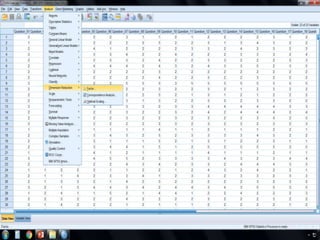
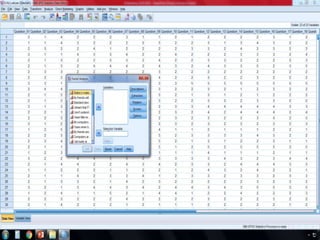
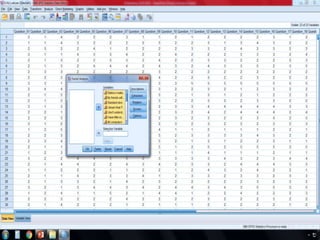
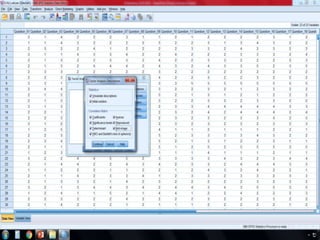
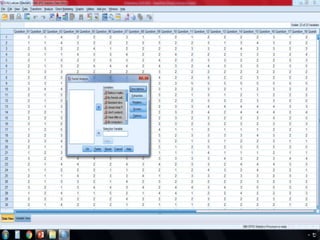
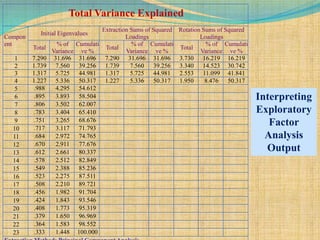
SPSS is a statistical software package used for interactive or programmed data analysis. It can perform complex data analysis and statistics with simple commands. Originally called the Statistical Package for the Social Sciences when it was first created in 1968, SPSS is now owned by IBM. The default window in SPSS contains a data editor with two sheets - the data view sheet displays raw data while the variable view sheet defines metadata for each variable. SPSS allows users to easily enter, clean, manage and analyze data to derive useful information for making informed decisions.